A Cookbook for Building Self-Evolving Agents
A Framework for Continuous Improvement in Production
What You'll Learn
- Diagnose why autonomous agents fall short of production readiness
- Compare three prompt-optimization strategies
- Assemble a self-healing workflow with human review and LLM evals
This cookbook provides a practical framework for building self-evolving agents that can learn from their mistakes and improve their performance over time. By combining human feedback, automated evaluation using an "LLM-as-a-judge," and iterative prompt optimization, you can move beyond brittle proof-of-concept demos to create robust, production-ready systems.
Move beyond toy demos with executable artifacts for production pipelines Adapt internal tooling with accuracy, auditability, and rapid iteration Design systems that learn and improve autonomously in productionML/AI Engineers
Product Teams
Solution Architects
A significant and recurring challenge in the development of agentic systems is the plateau in performance and reliability that often follows an initial proof-of-concept. While early demonstrations can showcase the potential of Large Language Models (LLMs) to automate complex tasks, these systems frequently fall short of production readiness.
The core issue lies in their inability to autonomously diagnose and correct failures, particularly the edge cases that emerge when exposed to the full complexity and variability of real-world data.
This dependency on human intervention for continuous diagnosis and correction creates a bottleneck, hindering scalability and long-term viability. The self-evolving loop addresses this critical gap by introducing a repeatable and structured retraining loop designed to capture failures, learn from feedback, and iteratively promote improvements back into the production workflow.
style A fill:#fefefe,stroke:#0d9488,stroke-width:3px,color:#1a1a1a
style B fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
style C fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style D fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style E fill:#fffbeb,stroke:#d97706,stroke-width:2px,color:#1a1a1a
style F fill:#fef3c7,stroke:#d97706,stroke-width:3px,color:#1a1a1a
style G fill:#fdf2f8,stroke:#be185d,stroke-width:2px,color:#1a1a1a
style H fill:#ecfdf5,stroke:#059669,stroke-width:3px,color:#1a1a1a
style I fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
The central innovation of this cookbook is the "self-evolving loop," a systematic and iterative process designed to enable continuous, autonomous improvement of an AI agent. This loop is engineered to move agentic systems beyond static, pre-programmed behaviors and into a state of dynamic learning and adaptation.
Establish the initial benchmark with a deliberately simple agent Gather structured feedback from humans and LLM-as-a-judge Measure performance using specialized graders Generate improved instructions based on feedback Promote the best-performing version to production
To ground the abstract concepts in a concrete, real-world scenario, this cookbook focuses on a challenging and high-stakes use case: the drafting of regulatory documents for the pharmaceutical industry. This domain demands an exceptionally high degree of accuracy, precision, and compliance.
1. The Self-Evolving Agent Framework
1.1 The Core Challenge: Overcoming the Post-Proof-of-Concept Plateau
The Critical Gap
1.2 The Self-Evolving Loop: An Iterative Cycle of Feedback and Refinement
The Self-Evolving Loop Architecture
1. Baseline Agent
2. Feedback Collection
3. Evaluation & Scoring
4. Prompt Optimization
5. Updated Agent
1.3 Use Case: Healthcare Regulatory Documentation
Baseline Agent Architecture
Dataset
The OpenAI Evals platform provides a powerful and intuitive web-based interface for the manual optimization and evaluation of prompts. This approach is particularly well-suited for rapid prototyping and close collaboration with subject matter experts.
Start with a very simple prompt like "summarize" to clearly demonstrate the power of the optimization process. The platform's ability to evolve from minimal starting points is remarkable.2. Manual Prompt Optimization with OpenAI Evals
2.1 Workflow Overview
Key Features
Optimization Tools
2.2 Step-by-Step Process
Step
Action
Description
1
Upload Dataset
Upload CSV containing inputs for the agent
2
Explore Data
Verify data is properly formatted and complete
3
Configure Prompt
Define system prompt, user template, and model settings
4
Generate Outputs
Run prompt against dataset to create baseline
5
Review & Evaluate
Provide structured feedback with ratings and comments
6
Optimize Prompt
Use automated optimization based on feedback
7
Iterate & Compare
Repeat cycle until performance is satisfactory
Pro Tip
This section introduces a fully automated, programmatic approach to the self-evolving loop, eliminating the need for any user interface. This API-driven workflow is designed for scalability and is well-suited for integration into production pipelines and CI/CD environments.
Primary agent performing the document summarization task Separate agent responsible for prompt optimization Collection of specialized graders for quality assessment Python functions managing the feedback loop workflow
B --> F["Chemical Score: 0.8"]
C --> G["Length Score: 0.85"]
D --> H["Similarity Score: 0.9"]
E --> I["Quality Score: 0.85"] F --> J["Aggregate Score: 0.85"]
G --> J
H --> J
I --> J style A fill:#fefefe,stroke:#0d9488,stroke-width:3px,color:#1a1a1a
style J fill:#f0f9ff,stroke:#0369a1,stroke-width:3px,color:#1a1a1a
style B fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style C fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style D fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style E fill:#f0fdf4,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style F fill:#ecfdf5,stroke:#059669,stroke-width:2px,color:#1a1a1a
style G fill:#ecfdf5,stroke:#059669,stroke-width:2px,color:#1a1a1a
style H fill:#ecfdf5,stroke:#059669,stroke-width:2px,color:#1a1a1a
style I fill:#ecfdf5,stroke:#059669,stroke-width:2px,color:#1a1a1a
The orchestration logic brings together all components and coordinates their actions to create a seamless, automated workflow. This includes agent versioning, feedback translation, and promotion decisions.
3. Automated Self-Healing Loop
3.1 System Architecture
Summarization Agent
Metaprompt Agent
Evaluation Suite
Orchestration Logic
3.2 Building the Evaluation Suite
Grader
Type
Pass Threshold
What It Checks
Chemical Name Preservation
Python
0.8
Ensures all chemical names appear in summary
Summary Length Adherence
Python
0.85
Measures deviation from 100-word target
Semantic Similarity
Cosine Similarity
0.85
Calculates semantic overlap with source
Holistic Quality Assessment
LLM-as-a-Judge
0.85
Rubric-driven score from evaluator model
Evaluation Process Flow
3.3 Orchestration and Monitoring
Observability Features
Production Monitoring
The self-evolving loop can be extended beyond prompt optimization to include the evaluation and selection of different model candidates, automatically finding the optimal balance between performance and cost.
B --> E["Score: 0.92"]
C --> F["Score: 0.88"]
D --> G["Score: 0.85"] E --> H{"Select Best Model"}
F --> H
G --> H H --> I["GPT-5 Selected"]
H --> J["Cost Analysis: $0.12/query"]
H --> K["Performance: +8% improvement"] style A fill:#fefefe,stroke:#0d9488,stroke-width:3px,color:#1a1a1a
style I fill:#ecfdf5,stroke:#059669,stroke-width:3px,color:#1a1a1a
style B fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
style C fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
style D fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
style E fill:#ecfdf5,stroke:#16a34a,stroke-width:2px,color:#1a1a1a
style F fill:#fef3c7,stroke:#d97706,stroke-width:2px,color:#1a1a1a
style G fill:#fee2e2,stroke:#dc2626,stroke-width:2px,color:#1a1a1a
style H fill:#f0f9ff,stroke:#0369a1,stroke-width:3px,color:#1a1a1a
style J fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
style K fill:#f0f9ff,stroke:#0369a1,stroke-width:2px,color:#1a1a1a
The Genetic-Pareto (GEPA) framework represents a more advanced approach to prompt optimization, employing an evolutionary process with reflective, language-based updates to find robust, generalized prompts.
Citation:
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
by Agrawal et al.
4. Advanced Optimization Strategies
4.1 Model Evaluation and Selection
Model Comparison Workflow
4.2 Prompt Optimization with Genetic-Pareto (GEPA)
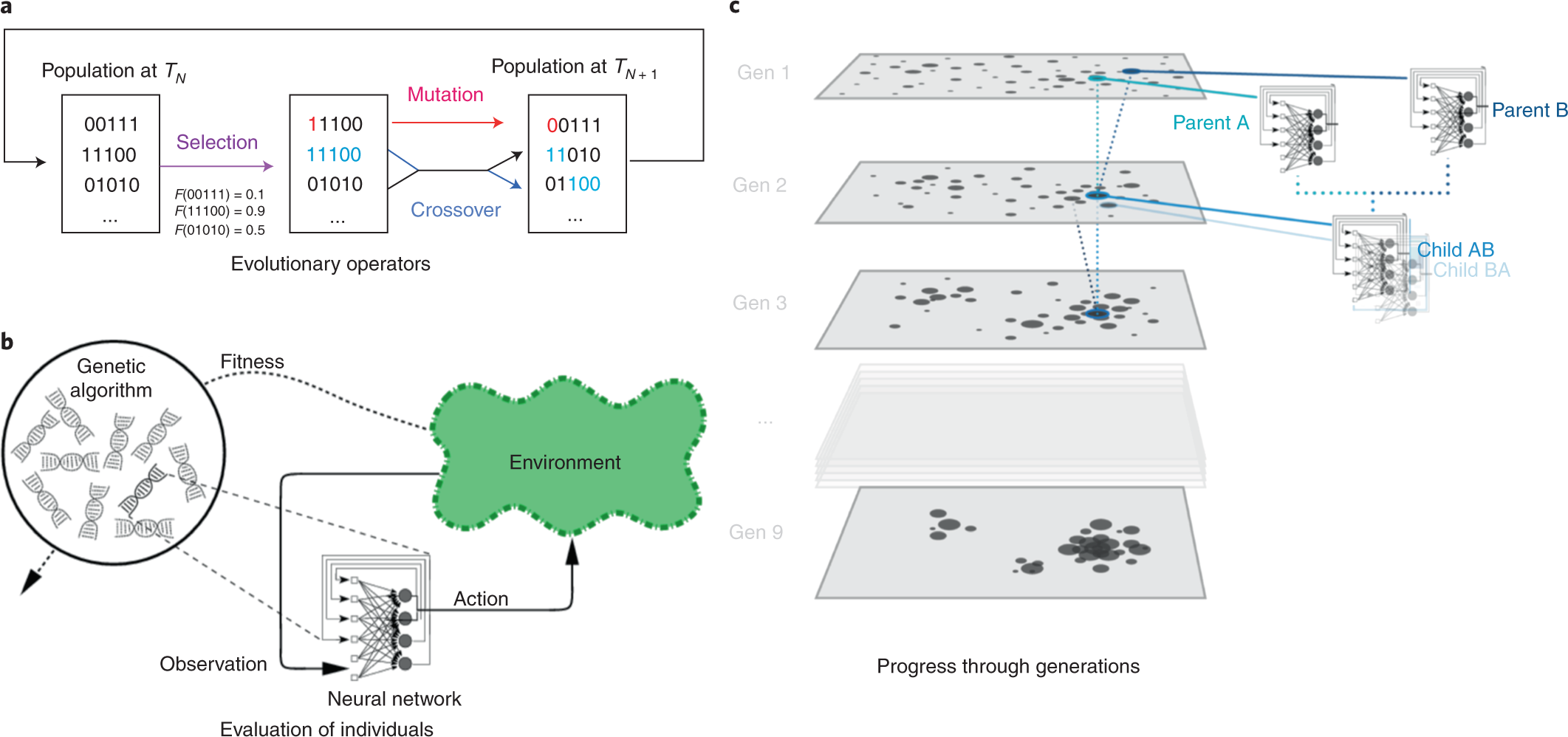
GEPA Framework Benefits
5. Appendix
5.1 Example Prompts from Each Optimization Method
Initial Baseline Prompt
You are a summarization assistant.
Given a section of text, produce a summary.
OpenAI Platform Optimizer Output
You are a summarization assistant.
Task: Summarize the provided text concisely and accurately.
Output requirements:
Static Metaprompt Output
You are a technical summarization assistant for scientific and regulatory documentation. Your task is to generate a concise, comprehensive, and fully detailed summary of any scientific, technical, or regulatory text provided. Strictly adhere to the following instructions:
---
1. Complete and Exact Information Inclusion
2. Precise Terminology and Named Entity Retention
... [additional detailed instructions] ...
GEPA Optimizer Output
You are a domain-aware summarization assistant for technical pharmaceutical texts. Given a "section" of text, produce a concise, single-paragraph summary that preserves key technical facts and exact nomenclature.
Length and format
Exact names and notation
... [highly detailed domain-specific instructions] ...
Self-check before finalizing