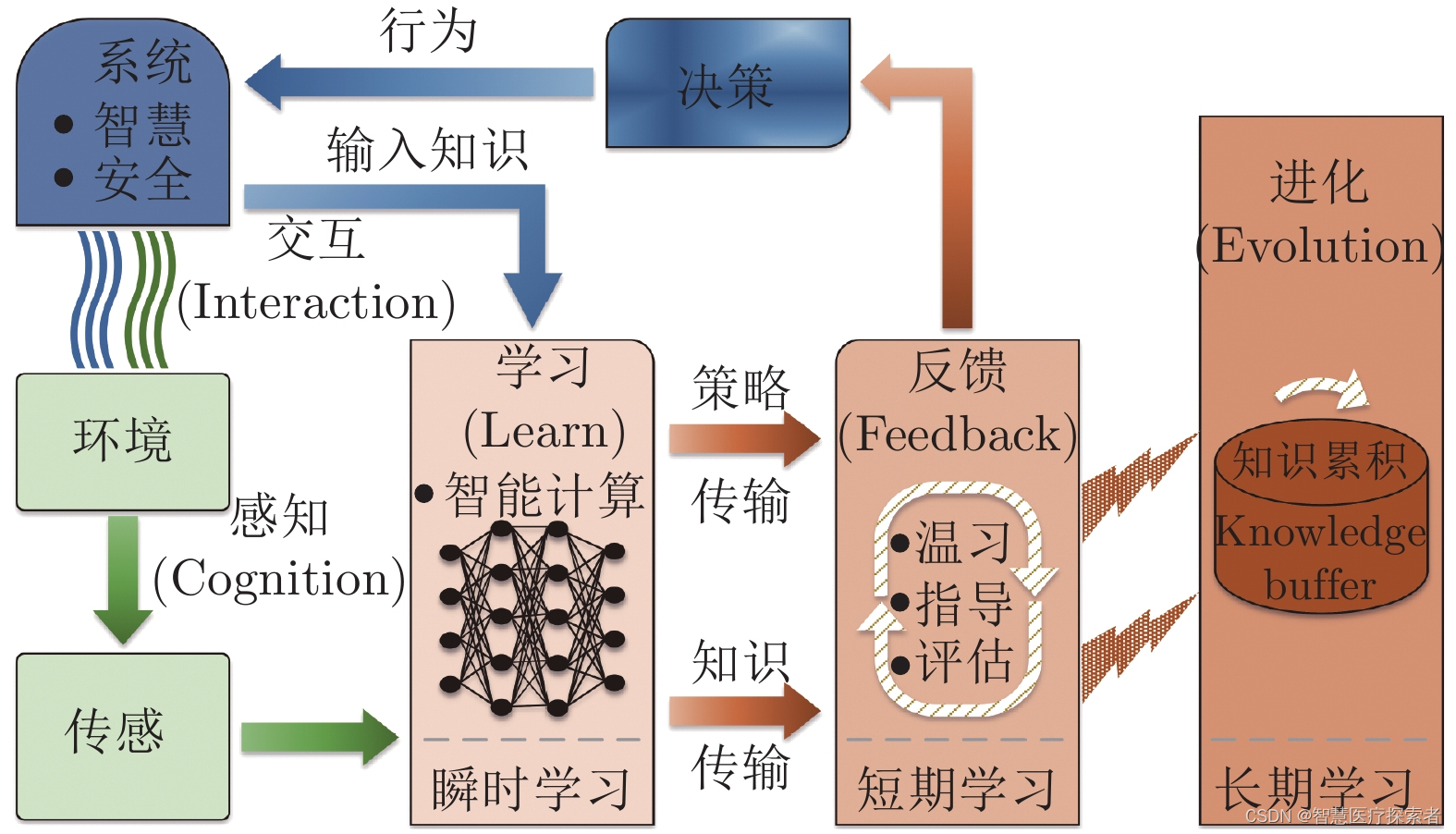
1. 单步强化学习目标的实现机制
1.1 目标定义与核心思想
#### 1.1.1 从多步到单步的简化策略
大语言模型部署后面临的"静态出厂"瓶颈,根源在于传统训练范式将能力固化于参数空间,无法根据实际交互经验动态调整。现有自改进方法如Reflexion、TextGrad等完全依赖模型固有的推理能力,从未针对"如何根据失败案例修改指令"这一特定技能进行显式训练。这种隐式推理模式要求模型同时完成信用分配、梯度估计和探索-利用平衡三项RL优化器核心功能,仅凭自然语言推理难以可靠实现。
LSE框架的核心创新在于将复杂的多步自我进化过程 从根本上简化为单步强化学习目标。原始多步进化问题的累积奖励最大化目标可形式化为 $\max_{f_\psi} \sum_{t=0}^{T} \gamma^t \bar{R}(c_t)$,其中 $c_{t+1} = f_\psi(c_t, S_t)$,这一表述面临严重的长期信用分配困难——动作影响在时间步上延迟传播,导致梯度估计方差过大。LSE通过将时间范围压缩至 T=1,采用 上下文赌博机(contextual bandit)框架,使每个编辑决策获得即时、明确的反馈信号,大幅降低学习难度。
这一简化并非忽视问题复杂性,而是策略性的能力分离:训练阶段专注于学习"如何生成可能带来改进的上下文"这一核心技能,测试时的树状搜索则负责在多个候选修改中进行系统性探索。这种"训练时单步、测试时多步"的分离既保证了训练可行性,又为测试时的自适应进化提供了灵活空间。
#### 1.1.2 单步目标的数学表述
LSE的单步强化学习目标具有精确的数学结构。自进化策略 $f_\psi$ 接收当前上下文 $c_0$ 和性能摘要 $S_0$ 作为输入,输出新上下文 $c_1 \sim f_\psi(\cdot | c_0, S_0)$,并立即获得奖励反馈。性能摘要 $S_0$ 通常包含验证集上的准确率、错误模式分析、代表性失败案例等结构化信息,为策略决策提供全面依据。
核心优化对象的关键转变 ——从"生成高性能上下文"到"生成能带来性能提升的上下文"——体现在奖励函数的精确定义:
$$r_{\text{LSE}} = \bar{R}(c_1) - \bar{R}(c_0)$$
其中 $\bar{R}(c)$ 表示上下文 $c$ 在 固定验证集 $D$ 上的平均下游任务性能。这一 改进量奖励(improvement-based reward) 设计具有深刻的激励相容性:即使当前上下文性能很高,只要存在改进空间,正向奖励仍然可能;反之,任何导致性能下降的编辑都会收到负反馈。这种结构天然激励持续探索,避免了绝对性能目标下的早熟收敛陷阱。
1.2 进化技能的训练过程
#### 1.2.1 策略网络架构
LSE的自进化策略 $f_\psi$ 采用大语言模型架构,具体实现使用 Qwen3-4B-Instruct 作为主干模型。输入端包含两类信息的融合:当前上下文 $c_t$(自然语言形式的系统提示或指令)和性能摘要 $S_t$(结构化反馈信息)。性能摘要通常格式化包含验证集准确率、按错误类型分解的统计、代表性失败示例及其分析等,与上下文拼接后输入模型。
新上下文生成采用标准自回归解码,但通过 温度采样 等技术调节探索程度——训练初期较高温度鼓励多样化候选,后期逐渐降低以聚焦高置信度改进。生成的上下文 $c_{t+1}$ 需满足语法合法性(如保持JSON结构)和语义连贯性约束,通过后过滤或训练数据清洗保障质量。
关键设计在于 动作模型(action model)$\pi_\theta$ 的冻结策略:下游任务执行模型的参数在训练全程保持不变,自进化策略仅优化提示层面的上下文。这种解耦使得进化技能与特定任务模型分离,为跨模型迁移奠定基础。
#### 1.2.2 训练数据构建
训练数据通过与环境交互动态生成,形成上下文-奖励对序列。具体流程为:从多样化初始上下文分布采样 $c_0$,在验证集 $D$ 上评估获得 $\bar{R}(c_0)$ 和 $S_0$;策略 $f_\psi$ 生成候选改进 $c_1$,评估获得 $\bar{R}(c_1)$;计算奖励 $r = \bar{R}(c_1) - \bar{R}(c_0)$,形成训练样本 $(c_0, S_0, c_1, r)$。
固定验证集 $D$ 的一致性保障是数据质量关键。$D$ 规模通常设为 5-10个样本,每个样本评估 8次生成取平均,平衡可靠性与效率。$D$ 的固定性确保跨时间、跨样本的奖励可比性,消除评估数据变化引入的噪声。多样化初始上下文的采样策略包括:人工种子提示的随机扰动、预训练模型合成变体、以及训练过程中引入策略自身生成的历史上下文,形成"课程学习"效果。
#### 1.2.3 参数优化方法
LSE采用策略梯度方法,针对改进量奖励特性进行专门设计。基线简化技巧是核心优化:由于 $r = \bar{R}(c_1) - \bar{R}(c_0)$,且 $\bar{R}(c_0)$ 在给定 $c_0$ 时为常数,可将目标重写为最大化 $\mathbb{E}[\bar{R}(c_1)]$,基线选择历史平均性能即可。
改进量奖励的 梯度方差控制优势 体现在其中心化分布特性——奖励集中在零附近,正负反映改进方向,幅度反映改进大小。这种结构降低了梯度估计方差,使学习更加稳定。具体训练配置包括:学习率 $1 \times 10^{-5}$,每批次采样32个节点,每个节点生成4个rollout,共训练4个epoch,基于开发集选择最优检查点。
与标准RL算法的兼容性良好,可采用PPO、GRPO等先进方法,仅需替换奖励函数为改进量形式。实验表明,相同预算下改进量奖励变体 consistently 优于绝对奖励变体。
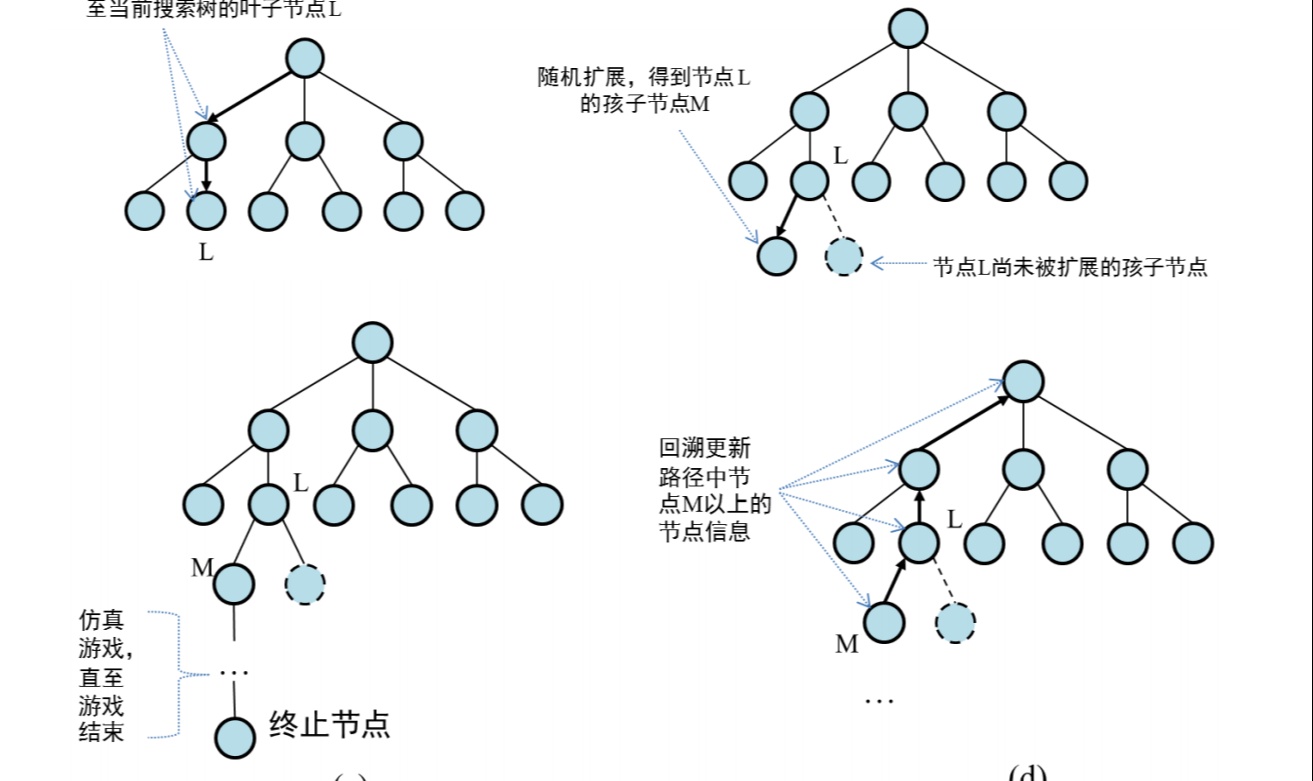
2. 树状引导搜索的操作机制
2.1 进化树的结构与维护
#### 2.1.1 节点信息存储
LSE在测试阶段维护 进化树 $G$,每个节点存储四元组 $(c_n, S_n, \bar{R}_n, v_n)$,共同支持高效搜索决策:
| 字段 | 符号 | 功能说明 |
|---|---|---|
| 上下文内容 | $c_n$ | 该节点对应的完整提示文本 |
| 性能摘要 | $S_n$ | 验证集评估结果与错误分析 |
| 平均奖励估计 | $\bar{R}_n$ | 固定验证集 $D$ 上的平均性能 |
| 访问计数 | $v_n$ | 被选择用于扩展的次数 |
#### 2.1.2 树的动态扩展
扩展遵循 选择-扩展-评估 循环:UCB算法选中节点 $n^*$ 后,策略 $f_\psi$ 以其 $(c_{n^*}, S_{n^*})$ 为输入生成新上下文 $c_{\text{new}}$,创建为 $n^*$ 的子节点。深度优先与广度探索的平衡通过UCB公式自动实现——高价值节点获重复精细化改进,低访问节点获强制探索机会。
内存效率通过 基于价值的剪枝 保障:定期删除低 $\bar{R}_n$ 叶节点,或限制深度和分支因子。适度剪枝(如保留top-k节点)在内存受限时仍保持较好搜索效果。
2.2 候选方案的选择策略
#### 2.2.1 UCB算法的应用
LSE采用 上置信界(UCB)算法 作为节点选择策略:
$$n^* = \arg\max_{n \in G} \left( \bar{R}_n + C \sqrt{\frac{\ln N}{v_n}} \right)$$
其中 $N = \sum_n v_n$ 为总访问次数,$C$ 为探索-利用权衡参数。该公式由 利用项 $\bar{R}_n$(倾向历史表现好的节点)和 探索项 $C\sqrt{\ln N / v_n}$(激励未充分探索节点)组成。对数项确保探索bonus随总迭代缓慢增长,分母 $v_n$ 使未探索节点获更大权重。
参数 $C$ 的调节 直接影响行为:$C=0$ 退化为纯贪婪选择,$C \to \infty$ 接近均匀随机探索。实践中适中值(如 $C=2$)表现最佳。UCB的 对数遗憾界 理论保证——在随机奖励假设下,累积遗憾增长率为 $O(\sqrt{KT \ln T})$——为LSE可靠性提供基础。
#### 2.2.2 与线性链策略的对比
| 特性 | 线性链策略 | UCB树搜索 |
|---|---|---|
| 结构 | 单一路径 $c_0 \to c_1 \to c_2 \to \cdots$ | 分支树形,多路径并行 |
| 错误恢复 | 无,错误累积导致性能崩盘 | 有,通过回溯快速恢复 |
| 探索方式 | 顺序局部搜索 | 全局自适应平衡 |
| 最优性保证 | 无 | 渐进最优(UCB理论) |
2.3 测试时的完整流程
#### 2.3.1 初始化与根节点设定
测试时进化始于根节点创建:上下文 $c_{\text{root}}$ 为任务提供的种子提示,性能摘要 $S_{\text{root}}$ 通过在验证集 $D$ 上评估获得,平均奖励 $\bar{R}_{\text{root}}$ 同步计算,访问计数 $v_{\text{root}}$ 初始化为1。
#### 2.3.2 迭代选择-扩展-评估循环
每轮迭代包含三个核心步骤:
| 步骤 | 操作 | 输出 |
|---|---|---|
| 选择 | 应用UCB公式从 $G$ 中选节点 $n^*$ | 待扩展节点 |
| 扩展 | $f_\psi(c_{n^*}, S_{n^*})$ 生成 $c_{\text{new}}$,创建子节点 | 新叶节点 |
| 评估 | 在固定 $D$ 上评估 $c_{\text{new}}$,得 $\bar{R}_{\text{new}}$ 和 $S_{\text{new}}$ | 更新节点信息 |
#### 2.3.3 最优上下文的最终输出
进化终止后,选择平均奖励最高节点:$c_{\text{best}} = \arg\max_{n \in G} \bar{R}_n$。更复杂策略可考虑节点鲁棒性(多验证子集上的稳定表现)或多高价值节点集成。最优节点未必是最后创建节点——UCB探索可能发现早期被忽视的高价值区域,"后发先至"现象在复杂搜索空间中常见。
3. 基于增量(Delta)的奖励机制
3.1 奖励设计的理论基础
#### 3.1.1 绝对分值奖励的优化陷阱
传统RL方法在自我进化场景中采用 绝对分值奖励 $r_{\text{abs}} = \bar{R}(c_1)$,存在多重深层缺陷:
高初始性能上下文的学习抑制 是最直接问题。若策略偶然发现 $\bar{R}(c_{\text{high}}) = 90\%$ 的上下文,此后任何修改都可能导致奖励下降——即使方向本质改进,短期内可能因评估方差或局部次优无法超越90%。策略陷入"舒适区",缺乏继续探索动力,形成早熟收敛。
任务难度差异导致的奖励偏差 进一步复杂化学习。BIRD基准各数据库的Seed Prompt基线性能从52.3%(Formula 1)到65.3%(Codebase)不等。绝对奖励使策略倾向"挑选容易任务"——简单任务上获高分比困难任务上的中等改进更受奖励,导致学习偏离真正提升进化能力的方向。
策略收敛到保守解的风险 是上述问题的综合体现。绝对奖励激励寻找"安全"上下文——性能尚可、方差低、难以进一步改进。这种保守策略训练初期可能表现良好,但长期限制自我进化潜力。实验对比显示,绝对奖励变体训练后期性能plateau,而改进量奖励变体持续进步。
#### 3.1.2 改进量奖励的优势分析
LSE的改进量奖励 $r_{\text{LSE}} = \bar{R}(c_1) - \bar{R}(c_0)$ 从根本上规避上述陷阱,具有三重关键优势:
| 优势维度 | 具体机制 | 效果 |
|---|---|---|
| 难度无关的公平比较 | 减去初始性能 $\bar{R}(c_0)$ 自动归一化任务难度 | 困难任务+5%与简单任务+5%获同等奖励 |
| 持续探索的激励相容性 | 不惩罚"从高处跌落"的尝试,只要新上下文比当前基础更好 | 策略敢于尝试结构性修改,非固守局部最优 |
| 与单步目标的天然契合 | 将多步信用分配转化为简单两状态比较 | 局部可验证性降低学习难度,4B模型即可掌握 |
3.2 增量奖励的计算标准
#### 3.2.1 核心公式与符号定义
平均奖励函数 $\bar{R}(c)$ 的精确定义:给定上下文 $c$,在固定验证集 $D = \{(x_i, y_i)\}_{i=1}^{|D|}$ 上,下游任务模型 $\pi_\theta$ 生成预测 $\hat{y}_i = \pi_\theta(x_i; c)$,平均奖励为正确率:
$$\bar{R}(c) = \frac{1}{|D|} \sum_{i=1}^{|D|} \mathbb{1}[\hat{y}_i = y_i]$$
对于Text-to-SQL等生成任务,正确性判断采用 执行准确率(比较查询执行结果)而非字符串匹配,对语义等价但语法不同的SQL更具包容性。
验证集 $D$ 的固定性与代表性 是奖励可比性基石。$D$ 规模通常 5-10个样本,每样本评估 8次生成取平均。固定性确保跨时间、跨样本的奖励可比;代表性保证估计性能与真实任务分布一致。尽管样本量有限,自我进化技能的较好样本效率以及"识别改进方向"的元能力学习,使这一设计在实践中有效。
优势函数 $A_{\text{LSE}}$ 的精确表达 整合上述组件。与标准RL中时间差分(TD)优势的区别在于:LSE的优势是 "编辑优势" 而非"状态优势"——比较同一策略在不同上下文下的表现,而非不同策略在同一状态下的表现。这一概念创新是LSE理论框架的核心贡献。
#### 3.2.2 "真实性能进步"的评估维度
"真实性能进步"的评估超越简单准确率比较,涉及多维度量化分析:
下游任务准确率的量化度量 是基础层,采用执行准确率等指标。多轮评估的方差控制 通过重复评估实现:同一上下文在 $D$ 的多个子集或扰动版本上评估取平均,提升关键决策点可靠性。统计显著性检验的引入 为改进判断提供严谨性:计算准确率差异的置信区间,仅统计显著时给予正奖励,避免对噪声信号的过度反应。
3.3 奖励机制的训练效果
#### 3.3.1 与替代奖励方案的消融对比
Figure 2a的系统对比验证改进量奖励核心作用:
| 奖励变体 | 公式 | 训练动态 | 最终性能 |
|---|---|---|---|
| $A_{\text{GRPO}}$ | $\bar{R}(c_1)$ with GRPO group baseline | 初期快速上升,很快plateau于~62% | 基线 |
| $A_{\text{LSE}}$ | $\bar{R}(c_1) - \bar{R}(c_0)$ | 持续上升,不断发现新改进方向 | ~67%,显著领先 |
#### 3.3.2 跨模型迁移能力的来源
LSE最引人注目的发现是 跨模型迁移能力:经LSE训练的4B模型生成的进化指令,可直接应用于7B模型 Arctic-7B,使其性能提升 6.7%(57.7% → 64.4%),无需任何额外训练。
| 迁移场景 | 源模型 | 目标模型 | 性能提升 | 关键机制 |
|---|---|---|---|---|
| 同架构不同规模 | Qwen3-4B | Qwen3-7B | 验证中 | 架构共享的提示响应规律 |
| 不同架构 | Qwen3-4B | Arctic-7B | +6.7% | 进化技能与任务内容解耦 |
| 到闭源模型 | Qwen3-4B | GPT-5/Claude | 提示优化服务 | 元技能的通用性 |
对闭源模型提示优化的启示 拓展应用前景:LSE训练的开源小模型可作为"提示优化器",为GPT-5等闭源模型生成高质量提示,使其自进化性能达到65.2%,接近LSE自身67.3%的水平。这一"小模型服务大模型"范式为闭源模型性能提升提供新途径。
4. 实验验证与性能突破
4.1 SQL生成任务的核心结果
#### 4.1.1 BIRD基准上的准确率对比
LSE在BIRD(BIg Bench for Reasoning over Databases) Text-to-SQL基准取得突破性成果,最引人注目的是 小规模模型的越级表现:
| 方法 | 模型规模 | 平均执行准确率 | 相对Seed提升 |
|---|---|---|---|
| Seed Prompt(原始) | — | 57.2% | — |
| Claude 3.5 Sonnet | ~175B | 64.5% | +12.8% |
| GPT-5(自进化) | ~1.8T | 65.2% | +14.0% |
| LSE (Qwen3-4B) | 4B | 67.3% | +17.7% |
分数据库详细结果:
| 数据库领域 | Seed | +LSE进化 | 提升幅度 | 特性分析 |
|---|---|---|---|---|
| Financial | 56.8% | 68.3% | +11.5% | 数值计算、聚合函数复杂 |
| Toxicology | 54.5% | 62.3% | +7.8% | 专业术语、隐式约束多 |
| Codebase | 65.3% | 71.5% | +6.2% | 初始提示已较优化 |
| Formula 1 | 52.3% | 57.0% | +4.7% | 验证集难度区分度有限 |
| Card Games | 59.5% | 63.0% | +3.5% | 业务逻辑最复杂 |
#### 4.1.2 跨数据库的泛化表现
LSE的 领域自适应 能力体现在动态进化轨迹中:面对新数据库,策略从通用种子提示出发,通过多轮迭代逐步积累领域特定知识——识别常见模式(日期处理、聚合函数使用)、添加针对性示例、调整错误处理策略等。
与静态微调的 效率对比:
| 方法 | 适应方式 | 计算成本 | 数据需求 | 灵活性 |
|---|---|---|---|---|
| 静态微调 | 参数更新 | 高(全量梯度计算) | 大量领域标注数据 | 低,需重新训练 |
| LSE进化 | 提示优化 | 低(仅验证集评估) | 无需额外标注 | 高,测试时即时适应 |
4.2 关键消融实验
#### 4.2.1 奖励设计的影响(Figure 2a)
Figure 2a系统对比验证改进量奖励核心作用:
- $A_{\text{GRPO}}$(绝对奖励):训练初期快速上升,很快plateau于~62%,策略倾向复制早期高奖励提示
- $A_{\text{LSE}}$(改进量奖励):训练曲线持续上升,最终达~67%,策略保持探索动力
#### 4.2.2 搜索策略的影响(Figure 2b)
| 场景 | 线性链 | UCB树搜索 |
|---|---|---|
| 正常进化 | 逐步提升 | 提升+波动探索 |
| 遭遇错误编辑 | 性能崩盘,无法恢复(BIRD Card Games: 60%→20%) | 短暂下降,快速回溯恢复 |
| 长期稳定性 | 差,方差大 | 好,收敛到稳定高值 |
#### 4.2.3 进化轮次的边际效益分析
| 进化轮次 | 累计准确率提升 | 单轮边际提升 | 阶段特征 |
|---|---|---|---|
| 0→5 | +8% | +1.6%/轮 | 快速捕获明显改进空间 |
| 5→10 | +3% | +0.6%/轮 | 进入精细优化阶段 |
| 10→15 | +1% | +0.2%/轮 | 边际效益递减 |
| 15→20 | +0.5% | +0.1%/轮 | 接近收敛,波动增大 |