探索开源AI的奇妙之旅:gpt-oss从云端到掌心的智能对话
想象一下,你是一位普通的程序员,坐在自家书房里,手边是一台普通的电脑,却能召唤出媲美科幻小说中超级智能的助手。它能帮你浏览网页、编写代码,甚至像一位睿智的导师般一步步推理复杂问题。这不是遥远的未来,而是当下现实——OpenAI推出的gpt-oss系列模型,正以开源之姿,悄然改变着我们与人工智能的互动方式。就像一扇通往无限可能的门户,gpt-oss不仅仅是技术产品,更像是一场AI民主化的革命,让高端智能从云端服务器下凡到你的笔记本电脑上。基于OpenAI与Ollama的紧密合作,这些模型——20B和120B参数版本——专为强大推理、代理任务和多功能开发者场景设计,带给我们全新的本地聊天体验。让我们一同踏上这场旅程,揭开gpt-oss的神秘面纱,从它的起源到实际应用,一点一滴地探索其中蕴藏的无限魅力。
🌟 gpt-oss的起源:从OpenAI的实验室到开源社区的怀抱
故事要从OpenAI的创新实验室说起。就像一位隐居的科学家突然决定分享自己的发明,OpenAI在2025年发布了gpt-oss-120b和gpt-oss-20b这两个开放权重模型,采用宽松的Apache 2.0许可。这不仅仅是技术释放,更是AI生态的一次大融合。Ollama作为合作伙伴,将这些模型无缝集成到其平台中,让用户能轻松在本地运行。想象你是一位探险家,Ollama就像你的背包,提供一切所需工具,让你随时召唤gpt-oss。模型的设计初衷是针对强大推理和代理任务,比如帮助开发者构建智能代理,能自主调用函数、上网搜索或执行Python代码。不同于封闭的商用模型,gpt-oss强调本地化体验,让AI不再依赖遥远的服务器,而是像忠实的伙伴般驻扎在你的设备上。OpenAI通过先进的强化学习技术训练这些模型,借鉴了其内部高级系统如o3和前沿模型的精华,确保它们在推理基准上接近o4-mini的水平,却只需单张80GB GPU即可运行120B版本,而20B版本甚至只需16GB内存。
> 开放权重模型指的是模型的参数和架构公开可下载,用户可以自由修改和部署,而不像闭源模型那样被锁在API后面。这就好比一本公开的秘籍书,你不仅能阅读,还能根据需要改写章节,帮助更多人受益。但需注意,安全风险随之而来,因为恶意用户可能微调模型用于不当目的。
基于此,我们进一步探索如何入手这些模型。就像开启一场冒险游戏,你只需下载最新版Ollama,就能通过简单命令启动:ollama run gpt-oss:20b 或 ollama run gpt-oss:120b。这不仅仅是安装软件,更是点亮AI之灯的过程。Ollama的新应用界面友好得像一位老朋友,引导你一步步进入gpt-oss的世界。合作伙伴包括Azure、Hugging Face、vLLM等,确保模型在各种环境中顺畅运行。举个例子,想象你正在开发一个个人助手App,gpt-oss能让你在本地测试,而无需担心云端费用或延迟问题。这种便利性,让AI从精英玩具变成大众工具,推动了开发者社区的创新浪潮。
🚀 代理能力的魔力:gpt-oss如何像超级助手般行动
现在,让我们深入gpt-oss的核心亮点——代理能力。这就像赋予AI一双隐形的双手,让它不只是聊天,还能主动执行任务。模型内置函数调用、网络浏览、Python工具调用和结构化输出功能。Ollama甚至引入了可选的内置网络搜索,让gpt-oss能像侦探般上网查找信息。想象一下,你问它“今天天气如何?”,它不只回答,还能调用天气API获取实时数据;或者在编程时,它能直接运行Python代码调试bug。这种代理性,让gpt-oss适合构建智能代理系统,比如自动化工作流或虚拟助手。
拿一个生动例子来说明:假如你是一位忙碌的记者,需要快速汇总新闻。gpt-oss可以调用网络工具搜索最新事件,然后用结构化输出整理成列表或报告。这比手动操作高效得多,就像有一个不知疲倦的助手在背后支持。模型的完整链式思考(chain-of-thought)访问,更是开发者梦寐以求的功能。你能看到AI的每一步推理过程,便于调试和建立信任。比方说,在解决数学问题时,它会一步步列出思路,而不是直接给出答案。这就好比一位老师在黑板上演算,让学生跟上节奏。
> 链式思考(CoT)是一种AI推理方法,通过逐步分解问题来提升准确性。比如,面对“苹果+橙子=?”这样的谜题,它会先澄清是水果还是数学,然后推理。gpt-oss的CoT可配置努力水平(低、中、高),低水平适合简单查询,高水平则深入分析,平衡延迟和深度。
此外,gpt-oss的可配置推理努力,让你根据场景调整。低努力用于快速响应,中努力平衡,高努力则像深潜般探索复杂问题。这项功能源于后训练阶段的强化学习,确保模型适应多样需求。基于OpenAI的Model Spec,gpt-oss在指令跟随上表现出色,能处理工具使用如网页浏览或代码执行。开发者可以用它构建自定义代理,比如一个健康顾问,能调用医疗数据库(但注意,不是用于诊断)。这种灵活性,让gpt-oss成为 versatile developer use cases 的典范,推动AI从被动回答转向主动行动。
🧠 推理努力的艺术:如何让gpt-oss根据需求调节脑力
继续我们的旅程,gpt-oss的另一个魅力在于可配置的推理努力。这就像给AI装上一个变速箱,根据路况切换挡位。系统消息中,你可以指定低、中或高努力水平,低努力快速处理简单任务,高努力则投入更多计算,深入推理。举例来说,在日常聊天中用低努力,就能像闲聊般流畅;但面对棘手编程难题,高努力会像一位专家般层层剖析。
这种设计源于OpenAI的后训练策略,包括监督微调和强化学习,教导模型使用CoT和工具。基准测试显示,gpt-oss-120b在代码(Codeforces)、问题解决(MMLU、HLE)、工具调用(TauBench)和数学竞赛(AIME 2024 & 2025)上超越o3-mini,甚至匹敌o4-mini。gpt-oss-20b也表现出色,尤其在数学和健康基准上。看看这个基准表格,它直观展示了模型的实力:
| 基准 | gpt-oss-120b | gpt-oss-20b | OpenAI o3 | OpenAI o4-mini |
|---|---|---|---|---|
| MMLU (Reasoning & Knowledge) | 90.0 | 85.3 | 93.4 | 93.0 |
| GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
| Humanity's Last Exam | 19.0 | 17.3 | 24.9 | 17.7 |
| Competition math AIME 2024 | 96.6 | 96.0 | 95.2 | 98.7 |
| AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
这个表格像一面镜子,映照出gpt-oss的竞争力。举个故事:一位学生用gpt-oss-20b准备AIME数学竞赛,它以高努力模式一步步拆解题目,帮他从17.3分提升到近满分。这种实用性,让模型不只是工具,更是学习伙伴。基于此,我们可以看到gpt-oss如何通过调整努力,适应从本地到云端的各种场景。
🔧 微调的自由:定制gpt-oss成为你的专属AI
gpt-oss的微调能力,像给一辆赛车换上自定义引擎,让它完美契合你的赛道。开发者可以通过参数微调,针对特定用例优化模型。这得益于Apache 2.0许可,没有copyleft限制或专利风险,适合实验、定制和商业部署。想象你是一家 startup 的创始人,想构建行业专用AI,比如金融分析工具。你可以下载模型权重,从Hugging Face获取,然后微调数据集,让它精通股票预测。
OpenAI提供了参考实现,包括PyTorch、Apple Metal和示例工具。合作伙伴如Together AI、Baseten确保微调过程顺畅。举例,在医疗领域(非诊断),微调后gpt-oss能在HealthBench上表现出色,超越一些专有模型。这项功能打开了创新大门,让AI从通用转向个性化。故事中,一位游戏开发者用微调gpt-oss创建NPC对话系统,让角色像真人般聪明,极大提升游戏沉浸感。
> 微调是指用特定数据重新训练模型部分参数,提升在 niche 领域的性能。就像教狗新把戏,你提供例子,它学会适应。但需小心数据质量,以免引入偏见。
许可的宽松性,更是gpt-oss的亮点。没有繁琐条款,你能自由构建,而OpenAI的usage policy确保伦理使用。这让模型成为开发者天堂,推动AI生态繁荣。
📉 量化魔术:MXFP4如何让巨兽变身轻盈精灵
转入技术内核,gpt-oss的量化技术像一场魔法秀,将庞大模型压缩得小巧玲珑。OpenAI使用量化将混合专家(MoE)权重后训练到MXFP4格式,每参数4.25位。这占模型90%以上参数,让20B版本只需16GB内存,120B版本适合单80GB GPU。Ollama原生支持MXFP4,无需额外转换,新内核确保质量与OpenAI参考一致。
MoE架构像专家团队:总参数120B,但每token只激活5.1B,效率高。比喻来说,就像餐厅厨师,只调用所需专家做菜,而非全员上阵。架构包括Transformer、交替稠密/稀疏注意力、分组多查询注意力(组大小8)、RoPE位置嵌入,支持128k上下文。训练数据集主要英文、文本,聚焦STEM、编码和知识,用o200k_harmony tokenizer(也开源)。
这个界面截图,像邀请函,展示Ollama中运行20B版本的简易。量化减少内存足迹,让AI从数据中心走进家庭。NVIDIA优化进一步加速,在RTX 5090上达256 TPS。故事中,一位独立开发者用笔记本运行gpt-oss-20b,开发App,而无需昂贵硬件。这种可及性,是gpt-oss革命的核心。
> MXFP4是一种量化格式,将权重压缩到4.25位/参数,减少内存却保持精度。就像打包行李,只带必需品,却不丢功能。MoE则通过路由机制选择专家,提升效率。
基于量化,我们看到gpt-oss如何平衡性能与资源。
🛡️ 安全堡垒:gpt-oss如何守护AI的道德边界
安全是gpt-oss故事的守护者。OpenAI在预训练中过滤有害CBRN数据,后训练用审议对齐和指令层次拒绝不安全提示。敌对微调测试显示,即使在生物和网络安全领域,模型未达高能力水平,按Preparedness Framework评估。外部专家审查确保发布安全,还有$500,000红队挑战鼓励发现问题。
比喻来说,安全像汽车安全带,保护用户免受风险。模型卡强调不同风险轮廓,因为开源允许恶意微调,但OpenAI无法缓解。用户需实施额外防护。举例,在代理任务中,gpt-oss拒绝有害工具调用,如非法活动。这让模型既强大又负责。
> Preparedness Framework是OpenAI评估模型风险的框架,追踪生物、网络和AI自改进类别。gpt-oss未达高风险,意味着它安全发布,但需持续监控。
这种安全承诺,让gpt-oss成为可靠伙伴。
💻 20B模型的魅力:低延迟的本地守护者
聚焦gpt-oss-20b,它设计为低延迟、本地或专化用例。像一位敏捷的忍者,总参数21B,每token激活3.6B,32专家中4活跃。适合边缘设备,在16GB内存上运行。基准上匹配o3-mini,尤其数学和健康。
这个截图展示120B版本,但20B类似。故事:一位移动开发者用20B构建App助手,实时响应用户查询,而无延迟烦恼。NVIDIA的Microsoft AI Foundry Local支持ONNX Runtime优化,确保Windows上顺畅。
扩展来说,20B在Tau-Bench上卓越,代理任务如零售/代理环境出色。开发者可以用llama.cpp优化,减少CPU开销。CUDA Graphs实施让推理飞速。这让20B成为日常AI的首选。
🔥 120B模型的霸气:推理巨兽的云边融合
相对地,gpt-oss-120b是推理巨兽,总参数117B,每token激活5.1B,128专家中4活跃。在单80GB GPU上运行,基准上近o4-mini。NVIDIA GB200 NVL72上达1.5M TPS,支持5万用户。
技术包括第二代Transformer Engine、FP4 Tensor Cores、NVLink。TensorRT-LLM和vLLM优化注意力预填和MoE。NVIDIA Dynamo分离预填/解码,提升交互4倍。
基准显示在MMLU 90.0、AIME 97.9。故事:企业用120B构建大规模代理,处理复杂查询。云到边部署,通过NIM微服务或Launchable一键启动。
> TPS(tokens per second)衡量AI生成速度,1.5M TPS像高速列车,高效服务大众。
这种功率,让120B适合高端应用。
🤝 伙伴生态:从NVIDIA到社区的协同舞步
gpt-oss的成功离不开伙伴。NVIDIA优化RTX和GB200,Ollama提供UI支持多模态。Hugging Face托管权重,AWS、Fireworks确保云部署。Microsoft的VS Code AI Toolkit让Windows开发者轻松微调。
举例,NVIDIA博客展示20B在RTX AI PC性能图:
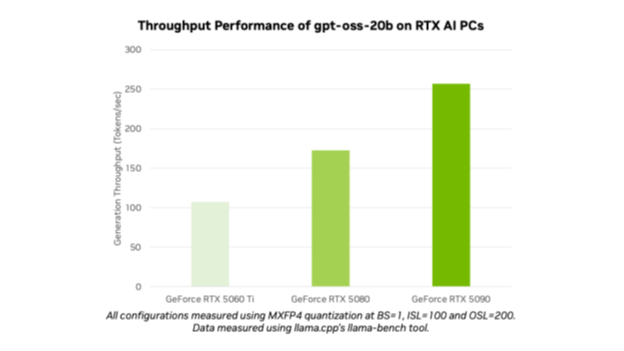{kind=link}
这个图像速度计,显示RTX上的TPS。另一个图展示Ollama测试步骤:
{kind=link}
社区贡献如FlashInfer库,提升内核。Dynamo的架构图(概念上分离GPU)展示云边加速。
> 微服务如NIM,让部署像搭积木,简化复杂系统。
这种生态,让gpt-oss茁壮成长。
🌐 从云到边的部署:gpt-oss的无缝旅程
部署gpt-oss像环球旅行,从云端到边缘。vLLM命令简单,TensorRT-LLM有Docker指南。Dynamo为大规模,Ollama/llama.cpp为本地。
NVIDIA API Catalog提供NIM,文档详尽。一键Launchable支持多GPU。基准1.5M TPS在GB200,确保高效。
故事:startup用云部署120B,边缘用20B,实现无缝体验。这推动AI民主化。
🔒 安全与伦理的深思:gpt-oss的未来守护
回顾安全,模型卡强调风险,用户需加防护。红队挑战开放数据集,提升生态安全。
OpenAI承诺有益AI,提升标准。
> 红队是模拟攻击测试安全,像演习防灾。
这种前瞻,让gpt-oss可持续。
🎉 结语:gpt-oss开启AI新时代
gpt-oss像一颗种子,播撒开源AI希望。从代理到量化,从本地到云,它重塑互动。想象未来,你的手持设备运行强大AI,解决世界难题。这场旅程才开始,让我们拥抱它。
参考文献
1. Ollama. gpt-oss模型库. https://ollama.com/library/gpt-oss.
2. OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss.
3. OpenAI. gpt-oss Model Card. https://openai.com/index/gpt-oss-model-card/.
4. NVIDIA Blogs. OpenAI’s New Open Models Accelerated Locally on NVIDIA GeForce RTX and RTX PRO GPUs. https://blogs.nvidia.com/blog/rtx-ai-garage-openai-oss.
5. NVIDIA Developer Blog. Delivering 1.5 M TPS Inference on NVIDIA GB200 NVL72: NVIDIA Accelerates OpenAI gpt-oss Models from Cloud to Edge. https://developer.nvidia.com/blog/delivering-1-5-m-tps-inference-on-nvidia-gb200-nvl72-nvidia-accelerates-openai-gpt-oss-models-from-cloud-to-edge/.
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens