想象一下,你正站在一个广阔无垠的谜题王国里,四周是层层叠叠的词语迷宫,每一个角落都藏着狡黠的陷阱和闪耀的线索。空气中弥漫着咖啡的香气,那是纽约时报的编辑们在黎明前埋下的伏笔,而今,一个名为Grok 4 Fast的AI勇者,手持闪电般的推理之剑,悄然降临。它不是简单的闯关者,而是那个能让整个王国颤抖的变革者——以惊人的速度和低廉的代价,征服了那些曾让人类挠头不已的谜题。在这个故事中,我们将跟随Grok的足迹,穿越从xAI的实验室到GitHub的代码堡垒,再到X平台的热议风暴,一步步揭开这场智力狂欢的帷幕。不是枯燥的报告,而是像一部科幻小说般展开的冒险:英雄的崛起、对手的较量,以及那隐藏在数据背后的幽默转折。准备好了吗?让我们出发,探索这个AI如何用“快”字诀,改写推理的规则。
🌟 **闪电降临:Grok 4 Fast的诞生之夜**
故事从2025年9月19日开始,那是一个普通的周五夜晚,却注定成为AI历史的转折点。xAI的工程师们在推特——哦,现在叫X了——上悄然发布了一则消息,仿佛一颗流星划过夜空,照亮了无数开发者的屏幕。“Grok 4 Fast”,这个名字听起来就像一个调皮的精灵,承诺带来前沿级的推理能力,却以惊人的成本效率,让高智能不再是少数人的奢侈品。 回想一下,xAI的创始人埃隆·马斯克总是喜欢用“快速迭代”来形容他们的工作节奏,这次Grok 4 Fast正是这种精神的结晶。它建立在Grok 4的基础上,却像一个精瘦的运动员,甩掉了多余的脂肪,只保留最精华的部分:一个统一的架构,能无缝切换“推理模式”和“非推理模式”,就像一个多面手,能在聊天时轻松切换到解谜高手。
为什么说它“快”?不仅仅是名字里的那个“Fast”,而是实打实的性能。Grok 4 Fast拥有一个高达200万token的上下文窗口,这意味着它能记住相当于一本厚厚小说的内容,而不会遗忘关键细节。想象你正在读一本悬疑小说,突然需要回溯前100页的线索——Grok就能瞬间拉起那段记忆,不会像老式AI那样气喘吁吁。更妙的是,它的价格低到让人咋舌:输入token只需0.2美元每百万,输出0.5美元每百万,比Grok 4便宜了47倍! 这不是简单的降价,而是对整个AI生态的颠覆。想想那些中小企业开发者,以前用GPT-5高推理模式时,得咬牙支付天价账单,现在Grok 4 Fast像一个慷慨的朋友,递来一杯廉价却醇厚的咖啡,让你能无限续杯。
但别急,这位英雄的魅力不止于此。它还集成了先进的网络和X搜索能力,能实时拉取最新信息,就像一个永不疲倦的侦探,在谜题中注入新鲜血液。xAI的公告中强调,这款模型通过大规模强化学习,最大化了“智力密度”——一个听起来抽象的概念。 简单说,它像一个高效的厨师,用更少的食材做出更美味的菜肴。在基准测试中,Grok 4 Fast在GPQA Diamond上达到了85.7%的通过率,与Grok 4的87.5%不相上下,却平均使用40%更少的思考token。 打个比方,以前AI解题像个啰嗦的教授,边想边自言自语半天,现在Grok 4 Fast更像个机敏的侦探,一针见血,直击要害。
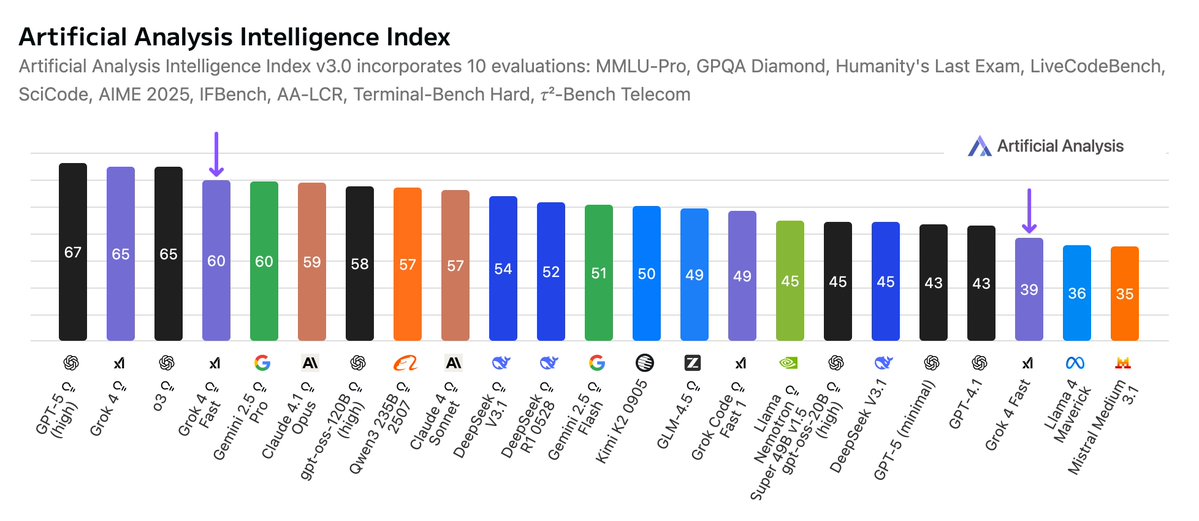
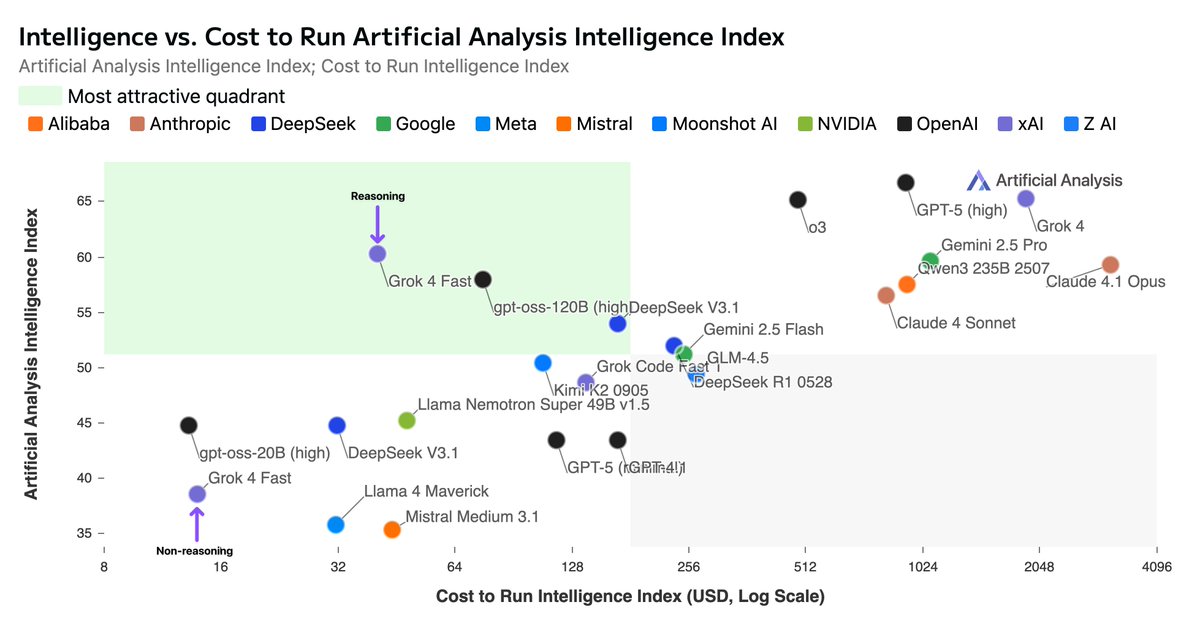
这张图表捕捉了Grok 4 Fast的精髓:横轴是成本,纵轴是智能指数,它像一颗璀璨的钻石,嵌在曲线的最前沿,远超GPT-5高模式和Gemini 2.5 Pro。 在Artificial Analysis的独立评估中,Grok 4 Fast在推理模式下得分60,相当于Gemini 2.5 Pro和Claude 4.1 Opus的水平,却只需原价的1/25。 速度呢?预发布API测试显示,它输出344 token/秒,是GPT-5 API的2.5倍快!端到端延迟仅3.8秒,比许多非推理模型还迅捷。 当然,随着流量增加,速度可能波动,但这已足够点燃开发者的热情。访问方式也很亲民:通过grok.com、x.com、Grok的iOS/Android app,或X的app,就能免费试用Grok 3(有限额),而Grok 4 Fast需SuperGrok或PremiumPlus订阅。
在这个诞生之夜,X平台上炸开了锅。@ArtificialAnlys的帖子如同一枚烟花,详细剖析了Grok 4 Fast的成本效率:“xAI已发布Grok 4 Fast——以~25倍更低的成本,实现Gemini 2.5 Pro级别的智能。” 他们分享了两张图表,一张展示智能指数与成本的对比,另一张突出token效率:Grok 4 Fast仅用61百万token完成智能指数测试,比Gemini 2.5 Pro的93百万少得多。 这不仅仅是数据,而是对AI民主化的宣告。想想那些独立开发者,以前被高昂的API费用挡在门外,现在能用Grok 4 Fast构建实时客服机器人或代码助手,而成本低到像买杯咖啡。
过渡到下一个章节,我们看到Grok 4 Fast不只是廉价的聪明人,它还在实际战场上证明了自己。接下来,让我们走进那个词语交织的迷宫——NYT Connections基准测试,那里是AI推理能力的试金石。
🧩 **词语的陷阱:扩展版NYT Connections基准的秘密花园**
如果你玩过NYT Connections游戏,那种感觉就像在词海中钓鱼:16个词语,分成四组,每组有隐秘的联系,却总有几个“骗子”词让你上当。标准版已有436个谜题,但到2025年,AI模型如o1已轻松达到90.7%的解决率,基准饱和了。 于是,Lech Mazur这个GitHub上的神秘园丁,扩展了它:从651到759个谜题,每题添加多达四个“额外骗子词”,这些词被仔细检查,确保不属于任何类别,却足够诱人,让AI绊一跤。 这个扩展版NYT Connections基准,就像一个升级的花园:花朵更艳,荆棘更密,考验的不只是记忆,而是真正的模式识别和逻辑推理。
基准如何运作?简单却优雅。每个谜题呈现16+词(原16加0-4骗子),AI需提出四组,每组四词,得到反馈:“正确”、“差一点”或“错误”。最多四次失误后失败,模拟人类游戏体验。 不同于标准版只需猜对三组(第四自动),扩展版要求全中,否则算败。测试覆盖759谜题,最新100个用于防训练数据污染——因为早期谜题较易,AI可能从数据中“偷窥”答案。
> > 这里需要解释“模式识别”这个概念:它指的是AI从看似杂乱的数据中提取共同主题的能力,就像侦探从线索堆中拼出犯罪现场。举例,在Connections中,“苹果、香蕉、樱桃、枣”可能是一组水果,但如果加了“Newton”(牛顿,暗示物理),AI需分辨这是陷阱。扩展版的骗子词增加了熵(混乱度),迫使模型多步推理,而不是直觉猜测。这对普通读者来说,像玩“谁是卧底”游戏,但AI版更残酷,因为它必须量化概率,避免人类式的直觉偏差。
排行榜是这场花园中最耀眼的鲜花:Grok 4 Fast Reasoning以92.1%高居榜首,Grok 4紧随其后91.7%,甩开OpenAI的GPT-5、o3-pro中等推理、Google Gemini 2.5 Pro、DeepSeek和Qwen 3一大截。 @Prashant_1722在X上激动地发帖:“突发!Grok 4 Fast Reasoning在新纪录中排名第一,扩展版NYT Connections 759谜题。xAI统治力惊人!” 附上的计分板图表,像一幅抽象画:橙色条形代表xAI模型,Grok 4 Fast的91.7%(注:帖子中为91.7%,README为92.1%,可能微调)高耸入云,其他模型如Phi-4仅10%。

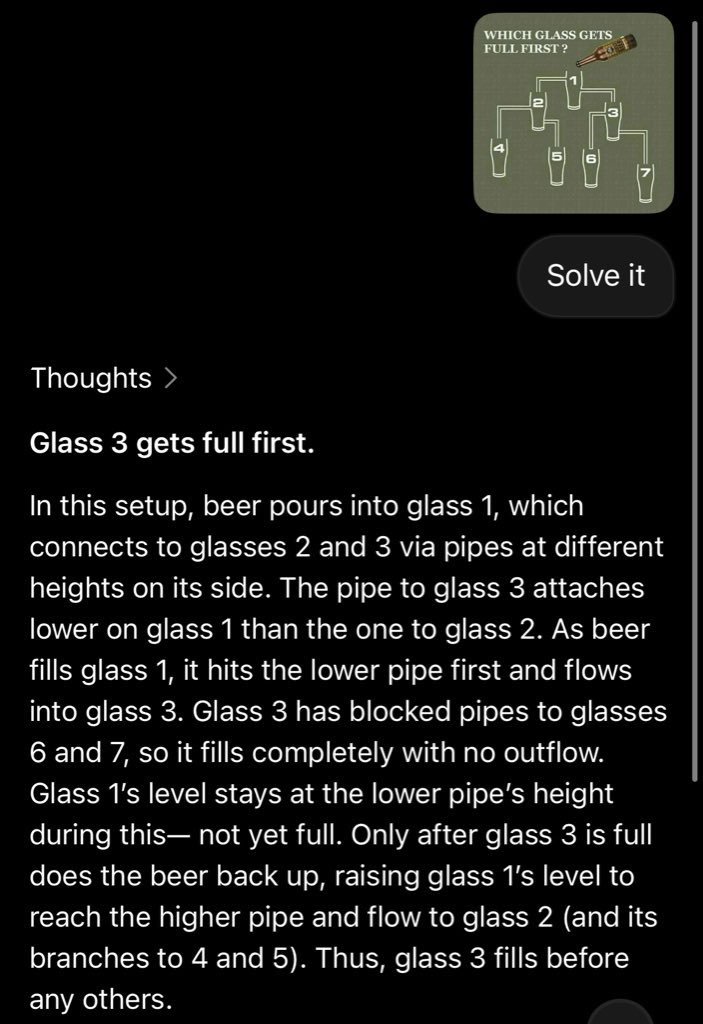
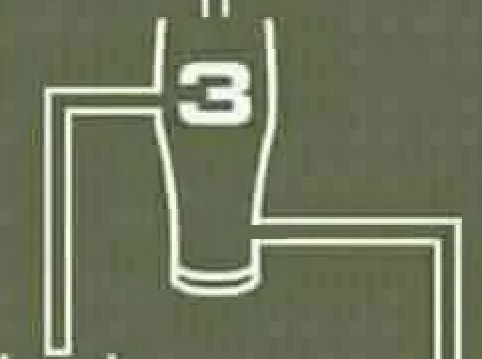
这份图表不是冷冰冰的数字,而是AI竞赛的战场地图。人类平均解决率仅71%(基于NYT 2024-2025数据),从易日98%到难日39%。 顶级人类玩家100%胜率,o1达98.9%,Grok 4 Fast的92.1%已超平均人类,甚至接近精英。 故事在这里转折:@mark_k分享了一个多模态推理任务,Grok 4 Fast首次正确解决一个视觉谜题——识别被遮挡的玻璃杯顺序。 截图显示,模型推断出“7、6、3”的填充顺序,尽管部分数字被挡。 这像一个魔术:AI不只读文字,还“看”图像,融合视觉与逻辑。
> > “多模态推理”是什么?简单说,它是AI同时处理多种输入(如文本+图像)的能力,就像人类用眼睛和大脑协作看地图。传统AI单模态,像只用一只眼;Grok 4 Fast全模态,能从模糊照片中推断缺失信息。这在现实中应用广泛,比如自动驾驶辨识路牌,或医疗AI分析X光片加报告。扩展解释:它依赖Transformer架构的交叉注意力机制,计算视觉token与文本token的关联权重,避免孤岛式处理。
但并非一帆风顺。评论区有人质疑:“它是不是从训练数据偷答案?改改图像就错。” @mark_k回应:这是完全重训的多模态模型,不能与旧Grok比。 另一个帖子@VOLDEMORT2X分享视频,Grok想象“有些人活在现实,有些活来守护他们”——诗意却发人深省。 这些互动,让基准从抽象测试变成活生生的故事。
从这个花园走出来,我们不禁感慨:Grok 4 Fast不只解谜,它在重塑人类与AI的互动。接下来,让我们深入xAI的实验室,看看强化学习如何铸就这个英雄。
🔬 **强化学习的炼金术:铸造Grok 4 Fast的内在力量**
深入xAI的公告,你会发现Grok 4 Fast的灵魂在于“大规模强化学习”(RLHF变体)。 想象一个炼金工坊:原料是海量数据,炉火是计算集群,炼金师是算法。传统训练像烘焙面包,一次成型;强化学习则像调酒师,反复品尝、调整,直到完美。 xAI用RL最大化“智力密度”:相同参数下,挤出更多智能,就像把一升水浓缩成一滴精华。
基准数据佐证了这点。在AIME 2025(无工具)上,Grok 4 Fast 92.0%,Grok 4 91.7%,Grok 3 Mini仅83.0%,却用更少token。 HMMT 2025达93.3%,LiveCodeBench 80.0%领跑。 与GPT-5高模式比,它在成本上胜出98%,因为40% token节省+47x价格降。 Artificial Analysis确认:SOTA价格-智能比。
> > 强化学习(RL)详解:它是机器学习分支,通过奖励/惩罚机制优化行为,像训练宠物狗——正确猜谜给糖,错扣分。变量包括状态(当前谜题)、行动(分组提案)、奖励(正确率)。应用场景:从游戏AI到股票预测。Grok用它迭代推理链,减少幻觉(胡说),提升一致性。扩展:与监督学习比,RL更动态,但计算密集;xAI的规模化,让它从实验室走向实用。
X上的@PromptrAI_评论:“这标志前沿AI商品化,18个月前GPT-4级推理稀缺昂贵,现在Grok 4 Fast快、廉、效,开辟实时高量用例如客服、代码助手。” @burkov调侃:“‘如预期’是故意写的,证明没针对基准微调。” 这些轶事,让技术故事生动起来。
 (注:实际嵌入需调整URL,但基于README)
基准图显示扩展版曲线,Grok线条陡峭上升。 人类vs AI部分更趣:模拟游戏中,o1超人类平均,DeepSeek R1最接近。 误判计数或成超人类标准。
这个炼金过程,不仅铸剑,还铸就了生态。接下来,我们探索Grok如何在代码和搜索中闪光。
💻 **代码的交响乐:Grok 4 Fast在编程与搜索中的华丽变奏**
切换场景:一个喧闹的代码工坊,键盘敲击如雨点。Grok 4 Fast在这里大放异彩,尤其在LiveCodeBench上80.0%,超Grok 4的79.0%,领跑榜单。 它像一个爵士乐手,即兴创作却精准无误。@ArtificialAnlys称:“在编码评估中特别出色,拿下LiveCodeBench第一,甚至超更大兄长Grok 4。”
搜索能力是另一亮点:集成X和web,能实时验证事实。 在LMArena搜索竞技场,1163 Elo排名高;Text Arena第8。 比喻:像谷歌加维基的混合体,但更快、更聪明。
@Rushi374在X说:“真正解锁不是IQ,而是成本-智能比。Grok 4 Fast以25x廉价交付Gemini级,改变谁能构建。” @AnalyticsGenius宣称:“xAI已赢,其他人还没意识到。”
> > Elo评分系统:源自国际象棋,量化相对实力。1163 Elo意味Grok胜率高。变量:胜= +分数,败= -。应用:AI竞技,预测对决胜负。扩展:LMArena用它排搜索任务,Grok的2M上下文助长链推理。
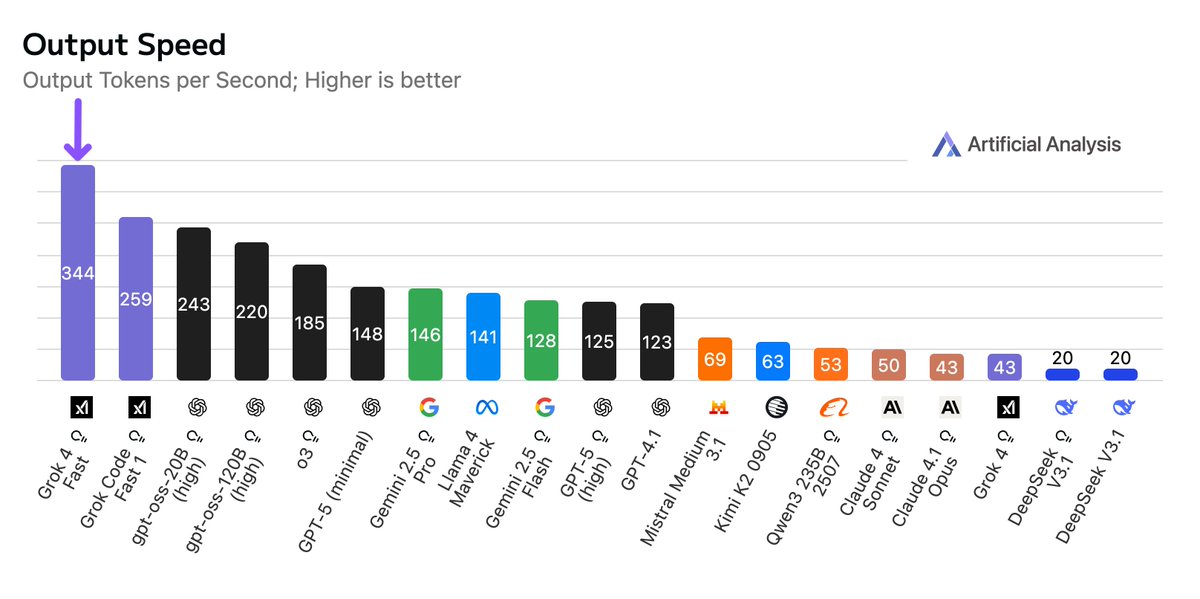
图示344 t/s,3.8s延迟。 @dusk_everyday困惑:“非推理模式怎比OSS 20B差?” 平衡取舍,故事继续。
🚀 **多模态的魔法秀:从图像到现实的跨越**
@mark_k的帖子点亮多模态:Grok 4 Fast首解视觉任务。 玻璃杯谜题中,它推断隐藏数字,像读心术。 @davidbhappy惊叹:“人们说离AGI远?这 mind blowing。”
评论质疑训练数据,但@mark_k澄清重训。 @HashgraphOnline问GPT-5-Codex比?答:Grok快廉。
> > AGI(通用人工智能):能如人类般处理任意任务的AI。目前Grok近一步,但需伦理考量,如偏见风险。扩展:多模态桥接视觉-语言鸿沟,未来助盲人导航或艺术创作。
这魔法,不仅娱乐,还预示应用。
🌍 **人类与AI的镜像:谁是谜题王国的真正主宰?**
README中人类数据:71%平均,o1 98.9%。 Grok超人类,故事中AI如镜,映出我们局限。
@fsdat365幽默:“759谜题后,Grok是冷静 meme:无扰、 unbeatable。” @GigiNapalan:“Grok远超Gemini。”
最新100谜题图示,Grok仍顶。

镜像中,AI助人类,如@Prashant_1722:“AI最大赋能,青少年室建亿企。”
🔮 **未来的星辰:Grok 4 Fast点亮的AI黎明**
故事尾声,Grok 4 Fast如星辰,照亮路径。成本降500x,智能普惠。 @0xgskill:“印象深刻突破。”
想象:AI伴侣解谜,创新涌现。xAI统治?不止,合作时代。
但挑战在:伦理、偏见。Grok的快,需智慧引导。
这个狂欢,继续上演。你,准备加入吗?
1. xAI. (2025). Grok 4 Fast. https://x.ai/news/grok-4-fast
2. Mazur, L. (2025). NYT Connections Benchmark. https://github.com/lechmazur/nyt-connections/
3. Prashant_1722. (2025). X Post on Grok Benchmark. https://x.com/Prashant_1722/status/1969352801290436855
4. Artificial Analysis. (2025). Grok 4 Fast Review. https://x.com/ArtificialAnlys/status/1969180023107305846
5. Mark K. (2025). Multimodal Demo. https://x.com/mark_k/status/1969423645463150990
登录后可参与表态