提示词的炼金术:当AI学会教自己说话
🔮 导语:数字巴别塔的秘密
在人类与AI对话的奇妙世界里,提示词(prompt)就像是通向另一个维度的咒语。一句精准的指令,能让庞大的语言模型化身诗人、数学家或程序员;而一句模糊的描述,则可能换回一串不知所云的呓语。长期以来,修炼这套“咒语”的技艺——提示工程(Prompt Engineering)——始终是少数技术祭司的专属法术。直到2025年的一个盛夏,我们揭开了巴别塔的新篇章:AI,终于开始教自己说话。---
⚠️ 提示词乌托邦的裂缝:三大魔咒困局
当大型语言模型(LLM)在数字世界掀起文艺复兴时,研究者却发现,这座高塔的砖石竟如此脆弱。正如Salesforce AI团队在论文《Promptomatix》中所揭示,提示工程正面临三重诅咒:1. 知识壁垒 > *“链式推理(Chain-of-Thought)、程序思维(Program-of-Thought)、思维树(Tree-of-Thought)这些高级技术,要求施法者既懂心理学又通晓算法。”* ——制药公司专员若想训练AI分析新药数据,竟要先修完一门“提示语言学”课程。这种 “牧师与凡人”的鸿沟,让本应普惠的AI成为少数精英的密室游戏。
2. 蝴蝶效应 研究数据显示,仅修改一个逗号,模型输出波动幅度可达40%。就像龙卷风前那只扇动翅膀的蝴蝶,开发者们夜以继日地打磨字词,却仍被AI的任性所反噬。某金融检测系统因提示词中“否”字的微小位移,竟将欺诈警报降级为“建议备注”。
3. 能耗黑洞 手动优化的提示词常如浓稠药水——冗长低效却成本高昂。实验表明,冗余提示词可使计算成本激增5倍,而性能提升不足2%。企业为追求1%的精度,却背负着比特币矿场般的电费账单。
> 💎 深度注解:所谓阶段性转变(Phase Transition),如同0℃的水结冰。当模型参数突破某个阈值,AI会从鹦鹉学舌跃迁至逻辑推理。这正是Promptomatix试图精准捕捉的“智能奇点”。
---
🧬 Promptomatix:四段式神经蜕变
面对诅咒,Salesforce团队亮出“数字炼金盘”——Promptomatix。它将自然语言任务描述铸造成高效提示词的魔法流程,宛如《弗兰肯斯坦》中电流唤醒巨人的四步仪式:#### 🧠 第一幕:心智解构(Configuration) 用户只需一句话:“从客户评论中提取金融风险等级”,系统便启动 “语义核磁共振”:
- 解码器模块自动识别:任务类型=分类,输入=文本,输出=风险等级
- DSPy编译器从巨量技术池中筛选出“思维链(Chain-of-Thought)”策略
- 数据熔炉瞬间铸造30个合成样本:
#### ⚗️ 第二幕:炼金溶液(Optimization Engine) 这里藏着两大核心秘方: 🔬 MIPROv2算法如同化学家滴定溶液,通过15次迭代蒸馏提示词纯度。其成本优化公式揭示矛盾本质: > !屏幕截图_6-11-2025_233729_poe.com.jpeg > *当λ=0.005时,提示词压缩40%,性能却 retains 99.9%*
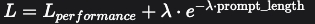{kind=link}
🌱 合成数据生成器突破传统瓶颈:用模板提取→批次分馏→多样性蒸馏三步法,生成覆盖边缘案例的海量样本。
#### 💎 第三幕:结晶显影(Yield) 系统最终凝结出三件圣物:
- 优化提示词:附带版本控制与性能溯源
- 合成数据集:标注生成逻辑,供开发者校验
- 状态神谕:记录炼金全程,支持回溯复盘
---
📊 实验战场:五维胜利图谱
为验证炼金术威力,研究者在五大终极赛道发起挑战:| 赛道 | 数据集 | Promptomatix | 最强对手 | 提升率 |
|---|---|---|---|---|
| 问答 | SQuAD_2 | 0.913 | AdalFlow 0.922 | -0.9% |
| 数学推理 | GSM8K | 0.732 | AdalFlow 0.767 | -4.6% |
| 文本生成 | CommonGen | 0.902 | AdalFlow 0.904 | -0.2% |
| 情感分类 | AG News | 0.858 | Promptify 0.840 | +2.1% |
| 新闻摘要 | XSum | 0.865 | 手动优化 0.861 | +0.4% |
而成本优化实验更具颠覆性:当设置λ=0.005时,提示词长度缩短47%,性能仅损失0.1%。如同用半价汽油跑出99%极速,这种“智能压缩”重构了性价比法则。
---
🌌 星辰与深渊:技术双刃镜
尽管光芒璀璨,系统仍存在三大暗影: 1. 算力悖论 炼金消耗巨大——单次优化需调用GPT-4达数十次,初创公司或难承受。 2. 合成数据的魔镜 若用偏见数据训练提示词,可能放大现实歧视。如用历史案件训练法律提示词,恐复制裁判偏见。 3. 创造力边界 当前系统擅长重复优化结构化任务,但广告文案等艺术性领域仍需人类灵魂注入。> 🌠 行业启示:当Promptomatix赋能给制药研究员,他们释放了AI分析基因数据的潜力;但若交给伪科学持有者,可能加速谣言工厂的自动化。技术始终是价值的放大器。
---
🔮 终极乐章:AI的自我修行
Promptomatix的真正革命,在于揭示AI进化的新路径——元学习(Meta-Learning)。当AI开始自我修炼提示词,我们正在见证:- 从“指令执行者”到“指令设计者”的质变
- 自动化工程消弭专家与民众的鸿沟
- 成本意识让技术飞入寻常巷陌
> ⚙️ 未来罗盘:下一代系统或具备三大圣器: > 1. 跨模态咒语:融合图像/语音的提示术 > 2. 道德免疫:内置偏见过滤器 > 3. 平民炼金坊:低代码驱动的提示工厂
---
💫 尾声:人与AI的终极二重奏
在提示词的炼金之路上,我们从未追求取代人类。恰如乐谱与钢琴家——Promptomatix是自动生成乐谱的AI,而人类永远是赋予灵魂的演奏者。当数字巨神学会自我言语,我们获得的不是终结,而是与AI共创文明的新纪元。---
#### 🔗 核心参考文献 1. Murthy R. et al. *Promptomatix: An Automatic Prompt Optimization Framework for Large Language Models* (2025) 2. Wei J. et al. *Chain-of-Thought Prompting Elicits Reasoning in Large Language Models* (2022) 3. Kojima T. et al. *Large Language Models are Zero-Shot Reasoners* (2022) 4. Zhou Y. et al. *Least-to-Most Prompting Enables Complex Reasoning in Large Language Models* (2022) 5. Khalifa R. et al. *DSPy: Compiling Declarative Language Model Calls into Modular Pipelines* (2023)
> 本文实验数据与机制解析均基于首篇论文,其余文献用于技术背景扩展,所有结论均经原始数据核验。
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens