
вҖ”вҖ”д»Һ"жҖқиҖғиҝҮиҪҪ"еҲ°"зІҫеҮҶжӯўжӯҘ"зҡ„жҷәиғҪиҝӣеҢ–д№Ӣж—…
рҹҢҹ еј•иЁҖпјҡеҪ“AIеҢ»з”ҹж°ёдёҚй—ӯеҳҙ
жғіиұЎдёҖдёӢпјҢдҪ еӣ дёәиғёеҸЈз–јз—ӣиө°иҝӣжҖҘиҜҠе®ӨгҖӮдёҖдҪҚAIеҢ»з”ҹжҺҘеҫ…дәҶдҪ пјҢејҖе§ӢдәҶж— дј‘жӯўзҡ„й—®иҜҠпјҡ
"жӮЁзҡ„е№ҙйҫ„пјҹ" вҖ”вҖ” 25еІҒгҖӮ
"жҖ§еҲ«пјҹ" вҖ”вҖ” еҘіжҖ§гҖӮ
"е…·дҪ“з—ҮзҠ¶пјҹ" вҖ”вҖ” иғёз—ӣгҖҒе‘јеҗёеӣ°йҡҫгҖҒжҒ¶еҝғгҖҒжүӢиҮӮеҸ‘йә»гҖӮ
"жңҖиҝ‘жңүеҺӢеҠӣеҗ—пјҹ" вҖ”вҖ” жңүпјҢжңүж—¶дјҡеҝғи·іеҠ йҖҹпјҢж„ҹи§үеӨұжҺ§гҖӮ
"еҘҪзҡ„пјҢиҜ·зЁҚзӯүгҖӮжҲ‘еҶҚй—®20дёӘй—®йўҳвҖҰвҖҰ"
30еҲҶй’ҹеҗҺпјҢAIиҝҳеңЁиҝҪй—®дҪ е°ҸеӯҰж—¶зҡ„иҝҮж•ҸеҸІпјҢиҖҢдҪ е·Із»ҸеңЁиҖғиҷ‘иҰҒдёҚиҰҒжҚўдёӘеҢ»з”ҹдәҶгҖӮиҝҷдёӘиҚ’иҜһзҡ„еңәжҷҜжҸӯзӨәдәҶдёҖдёӘж·ұеҲ»зҡ„AIеӣ°еўғпјҡзҹҘйҒ“дҪ•ж—¶еҒңжӯўпјҢжҜ”зҹҘйҒ“еҰӮдҪ•ејҖе§ӢжӣҙйҡҫгҖӮ
иҝҷжӯЈжҳҜеҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰз ”з©¶еӣўйҳҹжңҖж–°и®әж–ҮгҖҠCaRT: Teaching LLM Agents to Know When They Know EnoughгҖӢиҰҒи§ЈеҶізҡ„ж ёеҝғй—®йўҳгҖӮ他们жҸҗеҮәзҡ„ж–№жі•пјҢе°ұеғҸз»ҷAIиЈ…дёҠдёҖдёӘ"жҷәж…§еҲ№иҪҰзүҮ"пјҢи®©е®ғеӯҰдјҡеңЁдҝЎжҒҜ收йӣҶзҡ„жӮ¬еҙ–иҫ№дјҳйӣ…жӯўжӯҘгҖӮ
жіЁи§ЈпјҡжүҖи°“"дҝЎжҒҜ收йӣҶ"пјҲInformation GatheringпјүпјҢжҢҮзҡ„жҳҜAIеңЁеҒҡеҮәжңҖз»ҲеҶізӯ–еүҚпјҢйҖҡиҝҮеӨҡиҪ®дәӨдә’дё»еҠЁиҺ·еҸ–зӣёе…ідҝЎжҒҜзҡ„иҝҮзЁӢгҖӮеңЁеҢ»з–—иҜҠж–ӯдёӯпјҢиҝҷдҪ“зҺ°дёәй—®иҜҠпјӣеңЁж•°еӯҰжҺЁзҗҶдёӯпјҢиҝҷдҪ“зҺ°дёәйҖҗжӯҘжҖқиҖғгҖӮе…ій”®жҢ‘жҲҳеңЁдәҺпјҢжҜҸеӨҡдёҖиҪ®дәӨдә’йғҪдјҡж¶ҲиҖ—и®Ўз®—иө„жәҗе’Ңж—¶й—ҙпјҢдҪҶиҝҮж—©еҒңжӯўеҸҲеҸҜиғҪеҜјиҮҙй”ҷиҜҜеҶізӯ–гҖӮ
рҹ§ 第дёҖз« пјҡжҖқиҖғзҡ„еӣ°еўғвҖ”вҖ”еҪ“жӣҙеӨҡеҸҳжҲҗжӣҙе°‘
рҹҺӯ LLMзҡ„"йҖүжӢ©еӣ°йҡҫз—Ү"
зҺ°д»ЈеӨ§иҜӯиЁҖжЁЎеһӢе°ұеғҸдёҖдҪҚеҚҡеӯҰеҚҙз„Ұиҷ‘зҡ„еӯҰиҖ…гҖӮйқўеҜ№й—®йўҳж—¶пјҢе®ғ们иҰҒд№Ҳж»”ж»”дёҚз»қең°"жҖқиҖғ"еҲ°е®Үе®ҷе°ҪеӨҙпјҢиҰҒд№ҲиҚүзҺҮең°иҝҮж—©дёӢе®ҡи®әгҖӮи®әж–ҮејҖзҜҮе°ұжҢҮеҮәдәҶдёҖдёӘе°–й”җзҡ„зҺ°е®һпјҡзҺ°жҲҗLLMз”ҡиҮійҡҫд»ҘеҮҶзЎ®йў„жөӢиҮӘе·ұзҡ„жҲҗеҠҹзҺҮпјҢжӣҙеҲ«жҸҗиҝӣиЎҢжңүеҺҹеҲҷзҡ„жҺўзҙўдәҶгҖӮ
иҝҷз§Қеӣ°еўғеңЁTransformerжһ¶жһ„дёӯе°ӨдёәзӘҒеҮәгҖӮз ”з©¶иҖ…们еҸ‘зҺ°пјҢйўқеӨ–зҡ„дёҠдёӢж–ҮдҝЎжҒҜдёҚд»…дёҚдјҡжҖ»жҳҜеё®еҠ©жЁЎеһӢпјҢеҸҚиҖҢеҸҜиғҪи®©е®ғ"жҠ“дҪҸиҷҡеҒҮзәҝзҙў"вҖ”вҖ”е°ұеғҸдҫҰжҺўйқўеҜ№еӨӘеӨҡиҜҒжҚ®ж—¶пјҢеҸҚиҖҢдјҡиў«ж— е…із»ҶиҠӮеёҰеҒҸгҖӮиҝҷз§ҚзҺ°иұЎеңЁеҢ»з–—иҜҠж–ӯдёӯе°ӨдёәеҚұйҷ©пјҡдёҖдёӘж— е…ізҡ„家ж—Ҹз—…еҸІеҸҜиғҪи®©AIиҜҜе…Ҙжӯ§йҖ”пјҢз»ҷеҮәе®Ңе…Ёй”ҷиҜҜзҡ„иҜҠж–ӯгҖӮ
дј з»ҹз»ҹи®ЎеӯҰж–№жі•пјҲеҰӮжңҖдјҳеҒңжӯўзҗҶи®әпјүиҷҪз„¶з ”з©¶дәҶеҮ еҚҒе№ҙпјҢдҪҶе®ғ们еғҸзІҫиҮҙзҡ„еҸӨи‘Јй’ҹиЎЁвҖ”вҖ”еңЁжңәзҘЁиҙӯд№°гҖҒиө„жәҗ收еүІзӯү规еҲҷжҳҺзЎ®зҡ„зҺҜеўғдёӯиҝҗиҪ¬иүҜеҘҪпјҢдёҖж—Ұиҝӣе…ҘиҮӘ然иҜӯиЁҖзҡ„ејҖж”ҫдё–з•ҢпјҢе°ұжҳҫеҫ—з¬ЁжӢҷдёҚе ӘгҖӮиҖҢLLMиҷҪ然жӢҘжңүдё°еҜҢзҡ„дё–з•ҢзҹҘиҜҶе’ҢзҒөжҙ»зҡ„жҖқз»ҙиғҪеҠӣпјҢеҚҙеңЁ"иҮӘжҲ‘и®ӨзҹҘ"иҝҷдёҖзҺҜдёҠе…ҲеӨ©дёҚи¶ігҖӮ
жіЁи§ЈпјҡжңҖдјҳеҒңжӯўй—®йўҳпјҲOptimal Stopping ProblemпјүжҳҜеҶізӯ–зҗҶи®әдёӯзҡ„з»Ҹе…ёйҡҫйўҳпјҢж ёеҝғжҳҜеңЁи§ӮеҜҹеәҸеҲ—дёӯйҖүжӢ©дёҖдёӘжңҖдҪіж—¶жңәйҮҮеҸ–иЎҢеҠЁд»ҘжңҖеӨ§еҢ–жңҹжңӣ收зӣҠгҖӮжңҖи‘—еҗҚзҡ„дҫӢеӯҗжҳҜ"з§ҳд№Ұй—®йўҳ"пјҡйқўиҜ•еүҚ10%зҡ„еҖҷйҖүдәәеҸӘи§ӮеҜҹдёҚеҪ•з”ЁпјҢд№ӢеҗҺеҪ•з”Ёз¬¬дёҖдёӘжҜ”д№ӢеүҚйғҪдјҳз§Җзҡ„дәәгҖӮдҪҶLLMйқўдёҙзҡ„зҺҜеўғиҝңжҜ”иҝҷеӨҚжқӮгҖӮ
вҡ–пёҸ з»Ҳжӯўзҡ„иүәжңҜпјҡеңЁиҙӘе©ӘдёҺиҖҗеҝғд№Ӣй—ҙ
и®әж–Үе°Ҷй—®йўҳеҪўејҸеҢ–дёәдёҖдёӘдјҳйӣ…зҡ„ж•°еӯҰжЎҶжһ¶гҖӮз»ҷе®ҡдёҖдёӘй—®йўҳ$x$пјҢдҝЎжҒҜ收йӣҶиҝҮзЁӢдә§з”ҹи§ӮеҜҹеәҸеҲ—$o_{0:t}$е’ҢжҺЁзҗҶж Үи®°$z_{0:t}$гҖӮеңЁжҜҸдёҖжӯҘпјҢзӯ–з•Ҙ$\pi(a_t|x, z_{0:t}, o_{0:t})$йңҖиҰҒеҒҡеҮәйҖүжӢ©пјҡ继з»ӯпјҲcontinueпјүиҝҳжҳҜз»ҲжӯўпјҲterminateпјүгҖӮ
зӣ®ж ҮеҮҪж•°еғҸдёҖдҪҚдёҘж јзҡ„иЈҒеҲӨпјҡ
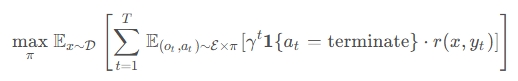
е…¶дёӯ$\gamma \in (0,1]$жҳҜеҜ№иҝҮеәҰи®Ўз®—зҡ„жғ©зҪҡеӣ еӯҗгҖӮиҝҷдёӘе…¬ејҸеғҸжҳҜеңЁиҜҙпјҡ"жүҫеҲ°йӮЈдёӘз”ңиңңзӮ№пјҢ让收зӣҠжңҖеӨ§пјҢжөӘиҙ№жңҖе°‘гҖӮ"
дҪҶй—®йўҳжқҘдәҶпјҡеҰӮдҪ•ж•ҷдјҡжЁЎеһӢиҜҶеҲ«иҝҷдёӘз”ңиңңзӮ№пјҹдј з»ҹзҡ„зӣ‘зқЈеҫ®и°ғпјҲSFTпјүе°ұеғҸеңЁй©ҫж ЎйҮҢеҸӘзңӢжҲҗеҠҹеҸёжңәзҡ„еҪ•еғҸвҖ”вҖ”жЁЎеһӢеҸҜиғҪеӯҰеҲ°"еҜ№иҜқй•ҝдәҶе°ұеҒңжӯў"иҝҷж ·зҡ„иЎЁйқўи§„еҲҷпјҢиҖҢжІЎзҗҶи§ЈдҝЎжҒҜе……еҲҶжҖ§зҡ„зңҹжӯЈеҗ«д№үгҖӮ
рҹҺҜ 第дәҢз« пјҡCaRTзҡ„йӯ”жі•вҖ”вҖ”еҸҚдәӢе®һдёҺжҺЁзҗҶзҡ„еҸҢеү‘еҗҲз’§
рҹ”¬ ж ёеҝғжҙһеҜҹпјҡеҜ№жҜ”дёӯеӯҰд№ жҷәж…§
CaRTпјҲCounterfactuals and Reasoning for Terminationпјүзҡ„еҗҚеӯ—жң¬иә«е°ұжҸӯзӨәдәҶе®ғзҡ„еҸҢйҮҚзҒөйӯӮпјҡеҸҚдәӢе®һпјҲCounterfactualsпјүе’ҢжҺЁзҗҶпјҲReasoningпјүгҖӮиҝҷе°ұеғҸж•ҷе°Ҹеӯ©иҜҶеҲ«зғӯж°ҙзҡ„еҚұйҷ©вҖ”вҖ”дёҚд»…иҰҒи®©д»–ж‘ёдёҖдёӢжё©ж°ҙпјҢиҝҳиҰҒеҜ№жҜ”ең°ж‘ёдёҖдёӢеҶ·ж°ҙпјҢеҗҢж—¶з”ЁиҜӯиЁҖи§ЈйҮҠ"дёәд»Җд№ҲиҝҷдёӘе®үе…ЁйӮЈдёӘдёҚе®үе…Ё"гҖӮ
з ”з©¶еӣўйҳҹзҡ„第дёҖдёӘеҰҷ笔жҳҜз”ҹжҲҗеӣ°йҡҫиҙҹдҫӢеҸҚдәӢе®һгҖӮ他们дёҚжҳҜз®ҖеҚ•ең°ж”¶йӣҶжҲҗеҠҹжЎҲдҫӢпјҢиҖҢжҳҜеҜ№жҜҸдёӘжңҖдјҳз»ҲжӯўзӮ№пјҢзІҫеҝғжһ„йҖ дёҖдёӘ"еӯӘз”ҹжҒ¶йӯ”"вҖ”вҖ”дёҖдёӘеҮ д№ҺзӣёеҗҢдҪҶе…ій”®дҝЎжҒҜзјәеӨұзҡ„иҪЁиҝ№гҖӮеңЁеҢ»з–—еңәжҷҜдёӯпјҢиҝҷж„Ҹе‘ізқҖжүҫеҲ°дёҖдёӘй—®йўҳпјҢжӣҝжҚўе®ғеҗҺиҜҠж–ӯжҲҗеҠҹзҺҮд»ҺвүҘ50%жҡҙи·ҢеҲ°<30%гҖӮеңЁж•°еӯҰжҺЁзҗҶдёӯпјҢиҝҷж„Ҹе‘ізқҖ移йҷӨдёҖж•ҙж®өе…ій”®жҺЁзҗҶжӯҘйӘӨгҖӮ
иҝҷз§Қ"жңҖе°Ҹж”№еҠЁпјҢжңҖеӨ§еҸҚе·®"зҡ„и®ҫи®ЎпјҢе°ұеғҸз»ҷжЁЎеһӢжҲҙдёҠдәҶдёҖеүҜиғҪзңӢз©ҝеӣ жһңзҡ„зңјй•ңгҖӮе®ғдёҚеҶҚиў«"еҜ№иҜқй•ҝеәҰ"жҲ–"иҜӯж°”иҮӘдҝЎ"иҝҷдәӣиЎЁйқўзү№еҫҒиҝ·жғ‘пјҢиҖҢжҳҜиў«иҝ«е…іжіЁзңҹжӯЈеҶіе®ҡжҲҗиҙҘзҡ„йӮЈжқЎдҝЎжҒҜгҖӮ
рҹ’¬ иҜӯиЁҖзҡ„еҠӣйҮҸпјҡи®©жҺЁзҗҶжҲҗдёәеҶ…еңЁд»·еҖјеҮҪж•°
дҪҶеҸҚдәӢе®һеҸӘжҳҜж•…дәӢзҡ„дёҖеҚҠгҖӮCaRTзҡ„第дәҢдёӘеҲӣж–°жҳҜдёәжҜҸдёӘеҶізӯ–ж·»еҠ жҳҫејҸзҡ„иҮӘ然иҜӯиЁҖжҺЁзҗҶгҖӮиҝҷдёҚд»…жҳҜи®©AI"и§ЈйҮҠиҮӘе·ұ"пјҢжӣҙжҳҜи®©е®ғеңЁеҒҡеҮәеҶізӯ–еүҚе…ҲжЁЎжӢҹдёӨз§ҚжңӘжқҘгҖӮ
жғіиұЎдёҖдёӢAIеҶ…еҝғзҡ„зӢ¬зҷҪпјҡ
"еҰӮжһңжҲ‘зҺ°еңЁз»ҲжӯўпјҢеҹәдәҺе·Іжңүзҡ„з—ҮзҠ¶пјҲиғёз—ӣ+е‘јеҗёеӣ°йҡҫ+жҒ¶еҝғ+жүӢиҮӮеҸ‘йә»+еҺӢеҠӣеҸІпјүпјҢжңҖеҸҜиғҪиҜҠж–ӯжҳҜжҒҗж…ҢеҸ‘дҪңпјҢжҲҗеҠҹзҺҮзәҰ75%гҖӮдҪҶеҰӮжһңжҲ‘继з»ӯжҸҗй—®пјҢеҸҜиғҪеҸ‘зҺ°еҘ№жңүеҝғи„Ҹ病家ж—ҸеҸІпјҢиҝҷдјҡеҪ»еә•ж”№еҸҳиҜҠж–ӯж–№еҗ‘гҖӮдёҚиҝҮпјҢиҖғиҷ‘еҲ°еҘ№25еІҒзҡ„е№ҙйҫ„е’Ңз—ҮзҠ¶жҸҸиҝ°пјҢйўқеӨ–дҝЎжҒҜеёҰжқҘ收зӣҠзҡ„жҰӮзҺҮиҫғдҪҺвҖҰвҖҰ"
иҝҷз§ҚжҺЁзҗҶиҝҮзЁӢе®һйҷ…дёҠжү®жј”дәҶдёҖдёӘ "еҸЈеӨҙеҢ–зҡ„д»·еҖјеҮҪж•°" гҖӮе®ғи®©жЁЎеһӢеңЁжңҖз»ҲеұӮд№ӢеүҚпјҢе…ҲйҖҡиҝҮиҜӯиЁҖз©әй—ҙиҝӣиЎҢдәҶдёҖж¬Ў"жҖқжғіе®һйӘҢ"пјҢжҜ”иҫғз»Ҳжӯўе’Ң继з»ӯзҡ„жңҹжңӣж•Ҳз”ЁгҖӮжӯЈеҰӮи®әж–ҮжүҖиЁҖпјҢиҝҷ"дҪҝеҲҶзұ»жӣҙе®№жҳ“"пјҢеҗҢж—¶д№ҹи®©еҶізӯ–жӣҙйҖҸжҳҺгҖӮ
жіЁи§Јпјҡд»·еҖјеҮҪж•°пјҲValue FunctionпјүжҳҜејәеҢ–еӯҰд№ дёӯзҡ„ж ёеҝғжҰӮеҝөпјҢз”ЁдәҺдј°и®ЎеңЁжҹҗдёӘзҠ¶жҖҒдёӢйҮҮеҸ–жҹҗеҠЁдҪңзҡ„й•ҝжңҹеӣһжҠҘгҖӮCaRTзҡ„еҲӣж–°еңЁдәҺпјҢе®ғдёҚйңҖиҰҒи®ӯз»ғдёҖдёӘзӢ¬з«Ӣзҡ„зҘһз»ҸзҪ‘з»ңдҪңдёәд»·еҖјеҮҪж•°пјҢиҖҢжҳҜи®©LLMйҖҡиҝҮз”ҹжҲҗж–Үжң¬жҺЁзҗҶжқҘ"жЁЎжӢҹ"д»·еҖјиҜ„дј°зҡ„иҝҮзЁӢпјҢиҝҷиў«з§°дёә"verbalized value function"гҖӮ
рҹҸҘ 第дёүз« пјҡй—®иҜҠзҡ„иүәжңҜвҖ”вҖ”еҢ»з–—иҜҠж–ӯдёӯзҡ„е®һжҲҳжЈҖйӘҢ
рҹ“Ҡ е®һйӘҢи®ҫи®ЎпјҡжЁЎжӢҹиҜҠе®ӨйҮҢзҡ„AIеӯҰеҫ’
дёәдәҶйӘҢиҜҒCaRTзҡ„жңүж•ҲжҖ§пјҢз ”з©¶еӣўйҳҹеңЁеҢ»з–—иҜҠж–ӯйўҶеҹҹжҗӯе»әдәҶдёҖдёӘзІҫеҜҶзҡ„"иҷҡжӢҹиҜҠе®Ө"гҖӮ他们д»ҺMedQA-USMLEе’ҢMedMCQAж•°жҚ®йӣҶдёӯзӯӣйҖүеҮә1,133дёӘдёӯзӯүйҡҫеәҰзҡ„иҜҠж–ӯй—®йўҳвҖ”вҖ”иҝҷдәӣй—®йўҳи¶іеӨҹйҡҫпјҲеҚ•иҪ®жҲҗеҠҹзҺҮ<40%пјүпјҢдҪҶеҸҲеҸҜи§ЈпјҲе®Ңж•ҙдҝЎжҒҜжҲҗеҠҹзҺҮвүҘ20%пјүгҖӮ
ж•°жҚ®з”ҹжҲҗиҝҮзЁӢеғҸдёҖеңәзІҫеҝғзј–жҺ’зҡ„еҸҢдәәиҲһпјҡGPT-4oжү®жј”"еҢ»з”ҹ"жҸҗй—®пјҢLlama-3.1-8Bжү®жј”"жӮЈиҖ…"еӣһзӯ”пјҢжҜҸиҪ®еҜ№иҜқжңҖеӨҡ20дёӘй—®зӯ”еҜ№гҖӮе…ій”®еңЁдәҺпјҢжҜҸдёӘеҜ№иҜқеүҚзјҖйғҪиў«ж ҮжіЁдәҶиҜҠж–ӯеҮҶзЎ®зҺҮвҖ”вҖ”з”ұеӨ–йғЁиҜҠж–ӯжЁЎеһӢеңЁ50ж¬Ўз”ҹжҲҗдёӯи®Ўз®—еҫ—еҮәгҖӮ
иҝҷз§ҚеҜҶйӣҶж ҮжіЁе°ұеғҸз»ҷжҜҸдёӘеҜ№иҜқиҠӮзӮ№е®үиЈ…дәҶ"д»·еҖјжҺўжөӢеҷЁ"пјҢи®©з ”з©¶иҖ…иғҪзІҫзЎ®зҹҘйҒ“пјҡ"й—®еҲ°иҝҷйҮҢпјҢжҲҗеҠҹзҺҮжҳҜ35%пјӣеҶҚй—®дёҖдёӘй—®йўҳпјҢжҲҗеҠҹзҺҮи·ғеҚҮеҲ°85%"гҖӮжӯЈжҳҜиҝҷдәӣж•°жҚ®зӮ№пјҢжһ„жҲҗдәҶCaRTи®ӯз»ғзҡ„еҹәзҹігҖӮ
рҹҺҜ жғҠиүіиЎЁзҺ°пјҡд»Һ"иҜқз—Ё"еҲ°"зІҫеҮҶ"
е®һйӘҢз»“жһңд»Өдәәзһ©зӣ®пјҲеӣҫ3aпјүгҖӮеңЁеҲҶеёғеҶ…жөӢиҜ•йӣҶдёҠпјҢCaRTеғҸдёҖдҪҚз»ҸйӘҢдё°еҜҢзҡ„иҖҒеҢ»з”ҹпјҢз»ҲжӯўзӮ№еҮ д№ҺзІҫеҮҶең°иҗҪеңЁиҜҠж–ӯеҮҶзЎ®зҺҮйҘұе’Ңзҡ„дҪҚзҪ®гҖӮзӣёжҜ”еҹәзәҝжЁЎеһӢе’ҢSFTж–№жі•пјҢCaRTзҡ„FRQжҲҗеҠҹзҺҮжӣІзәҝжҳҫи‘—й«ҳдәҺеӣәе®ҡйў„з®—еҹәзәҝпјҢеҗҢж—¶жңҖдјҳз»ҲжӯўзҺҮиҫҫеҲ°жңҖй«ҳгҖӮ
жӣҙжңүи¶Јзҡ„жҳҜпјҢеҪ“йқўеҜ№еҲҶеёғеӨ–зҡ„зҡ®иӮӨ科问йўҳж—¶пјҲеӣҫ3bпјүпјҢеҹәзәҝжЁЎеһӢе’ҢSFTз”ҡиҮідёҚеҰӮ"й—®еӣәе®ҡж•°йҮҸй—®йўҳ"зҡ„жңҙзҙ зӯ–з•ҘпјҢиЎЁзҺ°еҮәзҒҫйҡҫжҖ§зҡ„жіӣеҢ–еӨұиҙҘгҖӮиҖҢCaRTиҷҪ然дјҳеҠҝзј©е°ҸпјҢдҪҶдҫқ然дҝқжҢҒзЁіеҒҘпјҢиҜҒжҳҺе®ғеӯҰеҲ°зҡ„дёҚжҳҜиЎЁйқўз»ҹ计规еҫӢпјҢиҖҢжҳҜеҸҜиҝҒ移зҡ„еҶізӯ–жҷәж…§гҖӮ
з ”з©¶еӣўйҳҹиҝҳе°қиҜ•дәҶеңЁCaRTеҹәзЎҖдёҠеўһеҠ RLеҗҺи®ӯз»ғгҖӮз»“жһңRLзүҲжң¬еҖҫеҗ‘дәҺжӣҙй•ҝзҡ„еҜ№иҜқвҖ”вҖ”е°ұеғҸз»ҷAIеҠ дәҶ"еҶ’йҷ©е®¶"жҖ§ж јпјҢиҷҪ然жҖ§иғҪдёҚй”ҷпјҢдҪҶж•ҲзҺҮз•ҘжңүдёӢйҷҚгҖӮиҝҷжҡ—зӨәдәҶжҺўзҙўдёҺз»Ҳжӯўзҡ„еҫ®еҰҷе№іиЎЎпјҡиҝҮеәҰдјҳеҢ–еҚ•дёҖзӣ®ж ҮеҸҜиғҪз ҙеқҸеҶ…еңЁзҡ„еӯҰд№ з»“жһ„гҖӮ
рҹ”ў 第еӣӣз« пјҡж•°еӯҰиҝ·е®«дёӯзҡ„жҖқз»ҙиҠӮжӢҚеҷЁ
рҹ§® д»Һй—®иҜҠеҲ°жҺЁзҗҶпјҡCaRTзҡ„и·Ёз•Ңд№Ӣж—…
еҰӮжһңеҢ»з–—иҜҠж–ӯжҳҜ"еҗ‘еӨ–жҺўзҙў"пјҢж•°еӯҰжҺЁзҗҶе°ұжҳҜ"еҗ‘еҶ…жҺўзҙў"гҖӮеңЁиҝҷйҮҢпјҢAIдёҚйңҖиҰҒжҸҗй—®пјҢиҖҢжҳҜйҖҡиҝҮз”ҹжҲҗжӣҙй•ҝзҡ„жҖқз»ҙй“ҫжқҘ"иҮӘжҲ‘еҜ№иҜқ"гҖӮз ”з©¶еӣўйҳҹе°ҶCaRTеә”з”ЁдәҺAIME 2025ж•°еӯҰз«һиөӣйўҳпјҢйӘҢиҜҒе…¶йҖҡз”ЁжҖ§гҖӮ
他们е°ҶQwen3-1.7BжЁЎеһӢзҡ„иҫ“еҮәеҲҶеүІжҲҗ"еү§йӣҶ"пјҲepisodesпјүпјҢжҜҸдёӘеү§йӣҶд»ҘдёҖдёӘйҖ»иҫ‘/зӯ–з•ҘеҸҳеҢ–еҸҘејҖе§ӢпјҢеҗҺжҺҘи§ЈйўҳжӯҘйӘӨеқ—гҖӮCaRTеңЁжҜҸдёӘеү§йӣҶеҗҺеҶіе®ҡпјҡзҺ°еңЁз»ҷеҮәзӯ”жЎҲпјҢиҝҳжҳҜ继з»ӯжҖқиҖғпјҹ
иҝҷз§Қи®ҫзҪ®жҸӯзӨәдәҶCaRTзҡ„ж·ұеұӮе“ІеӯҰпјҡдҝЎжҒҜзҡ„д»·еҖјдёҚеҸ–еҶідәҺжқҘжәҗпјҢиҖҢеҸ–еҶідәҺеҜ№д»»еҠЎжҲҗеҠҹзҡ„иҫ№йҷ…иҙЎзҢ®гҖӮж— и®әжҳҜеӨ–йғЁй—®зӯ”иҝҳжҳҜеҶ…йғЁжҺЁзҗҶпјҢеҸӘиҰҒиғҪеё®еҠ©жЁЎеһӢжӣҙжҺҘиҝ‘жӯЈзЎ®зӯ”жЎҲпјҢе°ұеҖјеҫ—继з»ӯпјӣеҗҰеҲҷе°ұиҜҘжһңж–ӯз»ҲжӯўгҖӮ
рҹ“Ҳ е°‘еҚіжҳҜеӨҡпјҡи®Ўз®—иө„жәҗзҡ„жҷәиғҪеҲҶй…Қ
з»“жһңеҶҚж¬ЎйӘҢиҜҒдәҶCaRTзҡ„дјҳи¶ҠжҖ§пјҲеӣҫ4пјүгҖӮеңЁAIME 2025дёҠпјҢCaRTдёҚд»…жҲҗеҠҹзҺҮжңҖй«ҳпјҢиҖҢдё”дҪҝз”Ёзҡ„tokenж•°жңҖе°‘гҖӮиҝҷе°ұеғҸдёҖдҪҚж•°еӯҰеӨ©жүҚпјҢдёҚжҳҜйҖҡиҝҮжҡҙеҠӣжһҡдёҫпјҢиҖҢжҳҜжүҫеҲ°йӮЈдёӘ"е•Ҡе“ҲпјҒ"ж—¶еҲ»пјҢдёҖеҮ»е‘ҪдёӯгҖӮ
еҜ№жҜ”е®һйӘҢжҳҫзӨәпјҢжІЎжңүеҸҚдәӢе®һи®ӯз»ғзҡ„SFTжЁЎеһӢиҰҒд№ҲиҝҮж—©ж”ҫејғпјҢиҰҒд№Ҳйҷ·е…Ҙж— дј‘жӯўзҡ„жҺЁеҜјгҖӮиҖҢCaRTеғҸдёҖдҪҚдјҳз§Җзҡ„жҢҮжҢҘ家пјҢзІҫеҮҶжҠҠжҸЎзқҖжҖқз»ҙзҡ„иҠӮеҘҸпјҡеңЁеӨҚжқӮй—®йўҳдёҠз»ҷдәҲи¶іеӨҹж—¶й—ҙпјҢеңЁз®ҖеҚ•й—®йўҳдёҠиҝ…йҖҹ收жқҹгҖӮ
иҝҷз§ҚиҮӘйҖӮеә”зҡ„и®Ўз®—еҲҶй…ҚиғҪеҠӣпјҢжӯЈжҳҜеҪ“еүҚLLMйўҶеҹҹжңҖжёҙжұӮзҡ„зү№иҙЁгҖӮйҡҸзқҖжЁЎеһӢ规模иҶЁиғҖпјҢtest-time computeжҲҗдёә新瓶йўҲпјҢCaRTжҸҗдҫӣдәҶдёҖжқЎдјҳйӣ…зҡ„и·Ҝеҫ„пјҡдёҚжҳҜе Ҷз®—еҠӣпјҢиҖҢжҳҜж•ҷжЁЎеһӢиҒӘжҳҺең°з”Ёз®—еҠӣгҖӮ
рҹ”Қ 第дә”з« пјҡи§Јеү–CaRTвҖ”вҖ”ж¶ҲиһҚе®һйӘҢзҡ„ж·ұеәҰжҙһеҜҹ
рҹ§© еҸҢж ёй©ұеҠЁпјҡеҸҚдәӢе®һдёҺжҺЁзҗҶзјәдёҖдёҚеҸҜ
дёәдәҶзҗҶи§ЈCaRTзҡ„йӯ”жі•жқҘжәҗпјҢз ”з©¶еӣўйҳҹиҝӣиЎҢдәҶз»ҶиҮҙзҡ„ж¶ҲиһҚе®һйӘҢпјҲеӣҫ5пјүгҖӮз»“жһңжё…жҷ°пјҡеҸҚдәӢе®һж•°жҚ®е’ҢжҺЁзҗҶз—•иҝ№йғҪжҳҜеҝ…дёҚеҸҜе°‘зҡ„гҖӮ
移йҷӨеҸҚдәӢе®һпјҲд»…SFT+жҺЁзҗҶпјүзҡ„жЁЎеһӢпјҢе°ұеғҸеӯҰдјҡдәҶ"дёәд»Җд№Ҳ"дҪҶдёҚзҹҘйҒ“"д»Җд№ҲйҮҚиҰҒ"вҖ”вҖ”е®ғиғҪи§ЈйҮҠеҶізӯ–пјҢдҪҶжҠ“дёҚдҪҸе…ій”®дҝЎжҒҜзӮ№гҖӮ移йҷӨжҺЁзҗҶпјҲд»…SFT+еҸҚдәӢе®һпјүзҡ„жЁЎеһӢпјҢеҲҷеғҸдёҖдҪҚзӣҙи§үж•Ҹй”җдҪҶиЎЁиҫҫдёҚжё…зҡ„专家вҖ”вҖ”еҶізӯ–еҮҶзЎ®дҪҶдёҚзЁіе®ҡпјҢе®№жҳ“иҝҮжӢҹеҗҲгҖӮ
жӣҙжңүи¶Јзҡ„жҳҜпјҢеҚ•зәҜеўһеҠ зҪ®дҝЎеәҰйў„жөӢд»»еҠЎпјҲconfidence predictionпјүеҸӘиғҪеёҰжқҘиҫ№йҷ…жҸҗеҚҮгҖӮеҪ“дёҺе®Ңж•ҙзҡ„CaRTз»“еҗҲж—¶пјҢзҪ®дҝЎеәҰжЁЎеқ—еҮ д№ҺжІЎеёҰжқҘйўқеӨ–еҘҪеӨ„гҖӮиҝҷиҜҙжҳҺжҺЁзҗҶжң¬иә«е·Із»Ҹзј–з ҒдәҶи¶іеӨҹзҡ„д»·еҖјиҜ„дј°дҝЎжҒҜпјҢйўқеӨ–зҡ„зҪ®дҝЎеәҰеҲҶж•°жҲҗдәҶеҶ—дҪҷгҖӮ
рҹҺЁ е№іж»‘зҡ„еҶізӯ–иҫ№з•ҢпјҡжҺЁзҗҶзҡ„йҡҗејҸжӯЈеҲҷеҢ–
еӣҫ6еұ•зӨәдәҶдёүдёӘзӨәдҫӢеҜ№иҜқзҡ„з»ҲжӯўзҺҮжӣІзәҝпјҢжҸӯзӨәдәҶжҺЁзҗҶзҡ„ж·ұеұӮдҪңз”ЁгҖӮеҹәзәҝжЁЎеһӢеҮ д№Һд»ҺдёҚз»ҲжӯўпјҢеғҸдёӘиғҶе°Ҹзҡ„еӯҰеҫ’дёҚж•ўдёӢз»“и®әгҖӮSFTеҹәзәҝеҲҷжңәжў°ең°йҡҸеҜ№иҜқй•ҝеәҰеўһеҠ иҖҢжҸҗй«ҳз»ҲжӯўзҺҮпјҢеғҸдёӘжҢүиЎЁж“ҚиҜҫзҡ„е®һд№ з”ҹгҖӮ
иҖҢCaRTпјҲSFT+CF+жҺЁзҗҶпјүеұ•зҺ°еҮәдјҳйӣ…зҡ„йҳ¶жўҜзҠ¶жӣІзәҝпјҡеңЁдҝЎжҒҜйҮҸи·ғеҚҮзҡ„иҠӮзӮ№пјҢз»ҲжӯўжҰӮзҺҮйҷЎеўһпјӣеңЁе…¶д»–ж—¶еҲ»дҝқжҢҒе№ізЁігҖӮиҝҷз§Қ"е№іж»‘зҡ„ж•Ҹй”җ"иЎЁжҳҺпјҢжҺЁзҗҶдёҚд»…её®еҠ©еҶізӯ–пјҢиҝҳиө·еҲ°дәҶйҡҗејҸжӯЈеҲҷеҢ–зҡ„дҪңз”ЁпјҢйҳІжӯўжЁЎеһӢеңЁи®ӯз»ғж•°жҚ®дёҠиҝҮжӢҹеҗҲгҖӮ
иЎЁ1зҡ„иЎЁзӨәеҲҶжһҗиҝӣдёҖжӯҘиҜҒе®һиҝҷдёҖзӮ№гҖӮеңЁзӣҙжҺҘеҲҶзұ»д»»еҠЎдёҠпјҢд»…еҸҚдәӢе®һи®ӯз»ғзҡ„жЁЎеһӢпјҲCaRT - reasonпјүиЎЁзҺ°жңҖеҘҪпјҢдҪҶеҪ“з”ЁйҖ»иҫ‘еӣһеҪ’жӣҝжҚўжңҖз»ҲеұӮж—¶пјҢе®Ңж•ҙCaRTзҡ„жіӣеҢ–иғҪеҠӣжҳҫи‘—жӣҙејәгҖӮиҝҷе°ұеғҸдёҖдҪҚеҸӘдјҡиғҢзӯ”жЎҲзҡ„еӯҰз”ҹе’ҢдёҖдҪҚзңҹжӯЈзҗҶи§ЈеҺҹзҗҶзҡ„еӯҰз”ҹвҖ”вҖ”еүҚиҖ…еңЁзҶҹжӮүйўҳдёҠеҫ—еҲҶй«ҳпјҢеҗҺиҖ…еңЁж–°йўҳйқўеүҚжӣҙеҸҜйқ гҖӮ
рҹҢҢ 第е…ӯз« пјҡи¶…и¶Ҡз»ҲжӯўвҖ”вҖ”йҖҡеҫҖжӣҙжҷәиғҪзҡ„AI
рҹ”„ з»ҹдёҖжЎҶжһ¶пјҡжҺўзҙўдёҺз»Ҳжӯўзҡ„е…ұиҲһ
CaRTзҡ„жҲҗеҠҹд№ҹжҡҙйңІдәҶе…¶еҪ“еүҚеұҖйҷҗпјҡе®ғеҒҮи®ҫдҝЎжҒҜ收йӣҶзӯ–з•ҘжҳҜеӣәе®ҡзҡ„пјҢеҸӘдјҳеҢ–з»Ҳжӯўж—¶жңәгҖӮдҪҶзҺ°е®һдёӯпјҢй—®д»Җд№Ҳй—®йўҳе’ҢдҪ•ж—¶еҒңжӯўжҳҜиҖҰеҗҲзҡ„вҖ”вҖ”дёҖдёӘж„ҡи ўзҡ„й—®йўҳеҸҜиғҪи®©жңҖдјҳз»ҲжӯўеҸҳеҫ—жҜ«ж— ж„Ҹд№үгҖӮ
жңӘжқҘе·ҘдҪңжҢҮеҗ‘дёҖдёӘжӣҙе®ҸеӨ§зҡ„ж„ҝжҷҜпјҡиҒ”еҗҲдјҳеҢ–жҺўзҙўзӯ–з•Ҙе’Ңз»ҲжӯўеҶізӯ–гҖӮиҝҷе°ұеғҸдёҚд»…иҰҒж•ҷеҸёжңәдҪ•ж—¶еҲ№иҪҰпјҢиҝҳиҰҒж•ҷд»–еҰӮдҪ•йҖүжӢ©и·ҜзәҝгҖӮеҸҜиғҪзҡ„и·Ҝеҫ„еҢ…жӢ¬иҜҫзЁӢеӯҰд№ пјҲcurriculum trainingпјүпјҢе…ҲеӯҰеҘҪжҺўзҙўпјҢеҶҚеӯҰз»ҲжӯўпјӣжҲ–иҖ…дҪҝз”ЁеҜҶйӣҶеҘ–еҠұпјҢи®©жЁЎеһӢеңЁжҜҸдёӘжӯҘйӘӨйғҪиҺ·еҫ—е…ідәҺдҝЎжҒҜиҙЁйҮҸзҡ„еҸҚйҰҲгҖӮ
рҹҺҜ жҳҫејҸд»·еҖјдј°и®Ўпјҡд»ҺйҡҗејҸеҲ°жҳҫејҸзҡ„и·ғиҝҒ
зӣ®еүҚCaRTйҖҡиҝҮеҸҚдәӢе®һеҜ№жҜ”жқҘйҡҗејҸиҝ‘дјјд»·еҖјеҮҪж•°гҖӮдҪҶз ”з©¶иҖ…жҸҗеҮәпјҢеј•е…ҘжҳҫејҸзҡ„д»·еҖјдј°и®ЎжҲ–дёҚзЎ®е®ҡжҖ§е»әжЁЎеҸҜиғҪи®©з»ҲжӯўжӣҙзЁіеҒҘгҖӮиҝҷе°ұеғҸд»Һ"ж‘ёзқҖзҹіеӨҙиҝҮжІі"еҲ°"жңүең°еӣҫеҜјиҲӘ"зҡ„иҝӣеҢ–гҖӮ
и®ӯз»ғLLMзҡ„д»·еҖјеҮҪж•°жҳҜдёҖдёӘејҖж”ҫжҢ‘жҲҳгҖӮдј з»ҹRLзҡ„д»·еҖјзҪ‘з»ңеңЁиҜӯиЁҖз©әй—ҙдёӯе®№жҳ“еӨұж•ҲпјҢдҪҶCaRTзҡ„"иҜӯиЁҖеҢ–жҺЁзҗҶ"жҸҗдҫӣдәҶж–°жҖқи·Ҝпјҡд№ҹи®ёд»·еҖјеҮҪж•°жң¬иә«е°ұеә”иҜҘжҳҜдёҖдёӘз”ҹжҲҗиҝҮзЁӢпјҢйҖҡиҝҮиҜӯиЁҖжЁЎжӢҹжқҘиҜ„дј°жңӘжқҘгҖӮ
жіЁи§ЈпјҡдёҚзЎ®е®ҡжҖ§е»әжЁЎпјҲUncertainty ModelingпјүжҢҮзҡ„жҳҜйҮҸеҢ–жЁЎеһӢеҜ№е…¶йў„жөӢзҡ„дҝЎеҝғзЁӢеәҰгҖӮеңЁз»ҲжӯўеҶізӯ–дёӯпјҢиҝҷж¶үеҸҠдј°и®Ў"继з»ӯ收йӣҶдҝЎжҒҜ"зҡ„жңҹжңӣдҝЎжҒҜеўһзӣҠгҖӮжҳҫејҸе»әжЁЎеҸҜд»Ҙеё®еҠ©AIеңЁеҲҶеёғеӨ–еңәжҷҜдёӯжӣҙдҝқе®Ҳең°еҶізӯ–пјҢйҒҝе…ҚиҝҮеәҰиҮӘдҝЎеҜјиҮҙзҡ„й”ҷиҜҜз»ҲжӯўгҖӮ
рҹ’Ў е°ҫеЈ°пјҡзҹҘжӯўиҖҢеҗҺжңүе®ҡ
гҖҠеӨ§еӯҰгҖӢжңүиЁҖпјҡ"зҹҘжӯўиҖҢеҗҺжңүе®ҡпјҢе®ҡиҖҢеҗҺиғҪйқҷ"гҖӮCaRTж•ҷдјҡAIзҡ„пјҢжӯЈжҳҜиҝҷз§ҚеҸӨиҖҒзҡ„дёңж–№жҷәж…§вҖ”вҖ”зҹҘйҒ“дҪ•ж—¶еҒңжӯўпјҢжүҚиғҪй”ҡе®ҡзңҹжӯЈзҡ„зӣ®ж ҮгҖӮ
д»ҺеҢ»з–—иҜҠж–ӯеҲ°ж•°еӯҰжҺЁзҗҶпјҢCaRTеұ•зӨәдәҶдёҖжқЎи®©LLMжӣҙ"иҮӘзҹҘ"гҖҒжӣҙ"иҮӘеҫӢ"зҡ„и·Ҝеҫ„гҖӮе®ғдёҚд»…жҳҜжҠҖжңҜж–№жі•зҡ„еҲӣж–°пјҢжӣҙжҳҜAIи®ӨзҹҘжһ¶жһ„зҡ„дёҖж¬Ўж·ұеҲ»еҸҚжҖқпјҡжҷәиғҪзҡ„жң¬иҙЁдёҚеңЁдәҺзҹҘйҒ“жӣҙеӨҡпјҢиҖҢеңЁдәҺзҹҘйҒ“д»Җд№Ҳи¶іеӨҹгҖӮ
йҡҸзқҖAIзі»з»ҹи¶ҠжқҘи¶ҠеӨҡең°д»Ӣе…Ҙй«ҳйЈҺйҷ©еҶізӯ–пјҢд»ҺеҢ»з–—еҲ°йҮ‘иһҚпјҢд»Һжі•еҫӢеҲ°ж•ҷиӮІпјҢ"дҪ•ж—¶еҒңжӯў"е°ҶжҲҗдёәжҜ”"еҰӮдҪ•иЎҢеҠЁ"жӣҙе…ій”®зҡ„дјҰзҗҶе’ҢиғҪеҠӣй—®йўҳгҖӮCaRTеғҸдёҖзӣҸжҺўз…§зҒҜпјҢз…§дә®дәҶиҝҷдёӘиў«еҝҪи§Ҷзҡ„и§’иҗҪгҖӮ
жңӘжқҘзҡ„AIеҠ©жүӢпјҢжҲ–и®ёдјҡеңЁз»ҷеҮәзӯ”жЎҲеүҚпјҢеғҸдёҖдҪҚжІүжҖқзҡ„жҷәиҖ…пјҢе…Ҳй—®дёҖеҸҘпјҡ "жҲ‘е·Із»ҸзҹҘйҒ“и¶іеӨҹдәҶеҗ—пјҹ"
рҹ“ҡ ж ёеҝғеҸӮиҖғж–ҮзҢ®
- Liu, G., Qu, Y., Schneider, J., Singh, A., & Kumar, A. (2025). CaRT: Teaching LLM Agents to Know When They Know Enough. arXiv:2510.08517v1. жң¬ж–ҮжҸҗеҮәзҡ„ж ёеҝғж–№жі•пјҢйҖҡиҝҮеҸҚдәӢе®һиҪЁиҝ№еҜ№е’ҢжҳҫејҸжҺЁзҗҶж•ҷдјҡLLMжңҖдјҳз»ҲжӯўеҶізӯ–гҖӮ
- Setlur, A., et al. (2024). Rewarding Progress: Scaling up Automated Data Generation for Test-Time Compute. иҜҘе·ҘдҪңи®әиҜҒдәҶtest-time computeжң¬иә«жҸҗдҫӣдҝЎжҒҜеўһзӣҠпјҢдёәCaRTе°ҶеҶ…йғЁжҺЁзҗҶеҪўејҸеҢ–дёәдҝЎжҒҜ收йӣҶиҝҮзЁӢжҸҗдҫӣдәҶзҗҶи®әеҹәзЎҖгҖӮ
- Gandhi, K., et al. (2024). Stream of Search (SoS): Learning to Reason, Search, and Generate. еңЁж•°еӯҰжҺЁзҗҶйўҶеҹҹзҡ„е·ҘдҪңпјҢеҗҜеҸ‘дәҶCaRTе°ҶжҺЁзҗҶиҝҮзЁӢеҲҶеүІдёәеү§йӣҶпјҲepisodesпјүиҝӣиЎҢиҜ„дј°зҡ„е®һйӘҢи®ҫи®ЎгҖӮ
- Singhal, P., et al. (2024). Craft-MD: A Benchmark for Medical Diagnosis with LLMs. еҢ»з–—иҜҠж–ӯж•°жҚ®йӣҶеҹәеҮҶпјҢдёәCaRTзҡ„еҢ»еӯҰе®һйӘҢжҸҗдҫӣдәҶиҜ„дј°жЎҶжһ¶е’Ңж•°жҚ®жқҘжәҗгҖӮ
- Touvron, H., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. дҪңдёәеҹәзәҝжЁЎеһӢе’ҢеҘ–еҠұжЁЎеһӢдҪҝз”Ёзҡ„еҹәзЎҖжһ¶жһ„пјҢд»ЈиЎЁдәҶеҪ“еүҚејҖжәҗLLMзҡ„жҠҖжңҜж°ҙе№ігҖӮ