**——从"思考过载"到"精准止步"的智能进化之旅**
---
## 🌟 **引言:当AI医生永不闭嘴**
想象一下,你因为胸口疼痛走进急诊室。一位AI医生接待了你,开始了无休止的问诊:
*"您的年龄?"* —— 25岁。
*"性别?"* —— 女性。
*"具体症状?"* —— 胸痛、呼吸困难、恶心、手臂发麻。
*"最近有压力吗?"* —— 有,有时会心跳加速,感觉失控。
*"好的,请稍等。我再问20个问题……"*
30分钟后,AI还在追问你小学时的过敏史,而你已经在考虑要不要换个医生了。这个荒诞的场景揭示了一个深刻的AI困境:**知道何时停止,比知道如何开始更难。**
这正是卡内基梅隆大学研究团队最新论文《CaRT: Teaching LLM Agents to Know When They Know Enough》要解决的核心问题。他们提出的方法,就像给AI装上一个"智慧刹车片",让它学会在信息收集的悬崖边优雅止步。
> **注解**:所谓"信息收集"(Information Gathering),指的是AI在做出最终决策前,通过多轮交互主动获取相关信息的过程。在医疗诊断中,这体现为问诊;在数学推理中,这体现为逐步思考。关键挑战在于,每多一轮交互都会消耗计算资源和时间,但过早停止又可能导致错误决策。
---
## 🧠 **第一章:思考的困境——当更多变成更少**
### 🎭 **LLM的"选择困难症"**
现代大语言模型就像一位博学却焦虑的学者。面对问题时,它们要么滔滔不绝地"思考"到宇宙尽头,要么草率地过早下定论。论文开篇就指出了一个尖锐的现实:**现成LLM甚至难以准确预测自己的成功率**,更别提进行有原则的探索了。
这种困境在Transformer架构中尤为突出。研究者们发现,额外的上下文信息不仅不会总是帮助模型,反而可能让它"抓住虚假线索"——就像侦探面对太多证据时,反而会被无关细节带偏。这种现象在医疗诊断中尤为危险:一个无关的家族病史可能让AI误入歧途,给出完全错误的诊断。
传统统计学方法(如最优停止理论)虽然研究了几十年,但它们像精致的古董钟表——在机票购买、资源收割等规则明确的环境中运转良好,一旦进入自然语言的开放世界,就显得笨拙不堪。而LLM虽然拥有丰富的世界知识和灵活的思维能力,却在"自我认知"这一环上先天不足。
> **注解**:最优停止问题(Optimal Stopping Problem)是决策理论中的经典难题,核心是在观察序列中选择一个最佳时机采取行动以最大化期望收益。最著名的例子是"秘书问题":面试前10%的候选人只观察不录用,之后录用第一个比之前都优秀的人。但LLM面临的环境远比这复杂。
### ⚖️ **终止的艺术:在贪婪与耐心之间**
论文将问题形式化为一个优雅的数学框架。给定一个问题$x$,信息收集过程产生观察序列$o_{0:t}$和推理标记$z_{0:t}$。在每一步,策略$\pi(a_t|x, z_{0:t}, o_{0:t})$需要做出选择:**继续**(continue)还是**终止**(terminate)。
目标函数像一位严格的裁判:
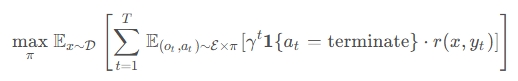
其中$\gamma \in (0,1]$是对过度计算的惩罚因子。这个公式像是在说:"找到那个甜蜜点,让收益最大,浪费最少。"
但问题来了:如何教会模型识别这个甜蜜点?传统的监督微调(SFT)就像在驾校里只看成功司机的录像——模型可能学到"对话长了就停止"这样的表面规则,而没理解**信息充分性**的真正含义。
---
## 🎯 **第二章:CaRT的魔法——反事实与推理的双剑合璧**
### 🔬 **核心洞察:对比中学习智慧**
CaRT(Counterfactuals and Reasoning for Termination)的名字本身就揭示了它的双重灵魂:**反事实**(Counterfactuals)和**推理**(Reasoning)。这就像教小孩识别热水的危险——不仅要让他摸一下温水,还要对比地摸一下冷水,同时用语言解释"为什么这个安全那个不安全"。
研究团队的第一个妙笔是**生成困难负例反事实**。他们不是简单地收集成功案例,而是对每个最优终止点,精心构造一个"孪生恶魔"——一个几乎相同但关键信息缺失的轨迹。在医疗场景中,这意味着找到一个问题,替换它后诊断成功率从≥50%暴跌到<30%。在数学推理中,这意味着移除一整段关键推理步骤。
这种"最小改动,最大反差"的设计,就像给模型戴上了一副能看穿因果的眼镜。它不再被"对话长度"或"语气自信"这些表面特征迷惑,而是被迫关注**真正决定成败的那条信息**。
### 💬 **语言的力量:让推理成为内在价值函数**
但反事实只是故事的一半。CaRT的第二个创新是为每个决策添加显式的自然语言推理。这不仅是让AI"解释自己",更是让它**在做出决策前先模拟两种未来**。
想象一下AI内心的独白:
> *"如果我现在终止,基于已有的症状(胸痛+呼吸困难+恶心+手臂发麻+压力史),最可能诊断是恐慌发作,成功率约75%。但如果我继续提问,可能发现她有心脏病家族史,这会彻底改变诊断方向。不过,考虑到她25岁的年龄和症状描述,额外信息带来收益的概率较低……"*
这种推理过程实际上扮演了一个 **"口头化的价值函数"** 。它让模型在最终层之前,先通过语言空间进行了一次"思想实验",比较终止和继续的期望效用。正如论文所言,这"使分类更容易",同时也让决策更透明。
> **注解**:价值函数(Value Function)是强化学习中的核心概念,用于估计在某个状态下采取某动作的长期回报。CaRT的创新在于,它不需要训练一个独立的神经网络作为价值函数,而是让LLM通过生成文本推理来"模拟"价值评估的过程,这被称为"verbalized value function"。
---
## 🏥 **第三章:问诊的艺术——医疗诊断中的实战检验**
### 📊 **实验设计:模拟诊室里的AI学徒**
为了验证CaRT的有效性,研究团队在医疗诊断领域搭建了一个精密的"虚拟诊室"。他们从MedQA-USMLE和MedMCQA数据集中筛选出1,133个中等难度的诊断问题——这些问题足够难(单轮成功率<40%),但又可解(完整信息成功率≥20%)。
数据生成过程像一场精心编排的双人舞:GPT-4o扮演"医生"提问,Llama-3.1-8B扮演"患者"回答,每轮对话最多20个问答对。关键在于,每个对话前缀都被标注了**诊断准确率**——由外部诊断模型在50次生成中计算得出。
这种密集标注就像给每个对话节点安装了"价值探测器",让研究者能精确知道:"问到这里,成功率是35%;再问一个问题,成功率跃升到85%"。正是这些数据点,构成了CaRT训练的基石。
### 🎯 **惊艳表现:从"话痨"到"精准"**
实验结果令人瞩目(图3a)。在分布内测试集上,CaRT像一位经验丰富的老医生,**终止点几乎精准地落在诊断准确率饱和的位置**。相比基线模型和SFT方法,CaRT的FRQ成功率曲线显著高于固定预算基线,同时最优终止率达到最高。
更有趣的是,当面对**分布外的皮肤科问题**时(图3b),基线模型和SFT甚至不如"问固定数量问题"的朴素策略,表现出灾难性的泛化失败。而CaRT虽然优势缩小,但依然保持稳健,证明它学到的不是表面统计规律,而是**可迁移的决策智慧**。
研究团队还尝试了在CaRT基础上增加RL后训练。结果RL版本倾向于更长的对话——就像给AI加了"冒险家"性格,虽然性能不错,但效率略有下降。这暗示了**探索与终止的微妙平衡**:过度优化单一目标可能破坏内在的学习结构。
---
## 🔢 **第四章:数学迷宫中的思维节拍器**
### 🧮 **从问诊到推理:CaRT的跨界之旅**
如果医疗诊断是"向外探索",数学推理就是"向内探索"。在这里,AI不需要提问,而是通过生成更长的思维链来"自我对话"。研究团队将CaRT应用于AIME 2025数学竞赛题,验证其通用性。
他们将Qwen3-1.7B模型的输出分割成"剧集"(episodes),每个剧集以一个逻辑/策略变化句开始,后接解题步骤块。CaRT在每个剧集后决定:**现在给出答案,还是继续思考?**
这种设置揭示了CaRT的深层哲学:**信息的价值不取决于来源,而取决于对任务成功的边际贡献**。无论是外部问答还是内部推理,只要能帮助模型更接近正确答案,就值得继续;否则就该果断终止。
### 📈 **少即是多:计算资源的智能分配**
结果再次验证了CaRT的优越性(图4)。在AIME 2025上,CaRT不仅**成功率最高,而且使用的token数最少**。这就像一位数学天才,不是通过暴力枚举,而是找到那个"啊哈!"时刻,一击命中。
对比实验显示,没有反事实训练的SFT模型要么过早放弃,要么陷入无休止的推导。而CaRT像一位优秀的指挥家,精准把握着**思维的节奏**:在复杂问题上给予足够时间,在简单问题上迅速收束。
这种**自适应的计算分配**能力,正是当前LLM领域最渴求的特质。随着模型规模膨胀,test-time compute成为新瓶颈,CaRT提供了一条优雅的路径:不是堆算力,而是**教模型聪明地用算力**。
---
## 🔍 **第五章:解剖CaRT——消融实验的深度洞察**
### 🧩 **双核驱动:反事实与推理缺一不可**
为了理解CaRT的魔法来源,研究团队进行了细致的消融实验(图5)。结果清晰:**反事实数据和推理痕迹都是必不可少的**。
移除反事实(仅SFT+推理)的模型,就像学会了"为什么"但不知道"什么重要"——它能解释决策,但抓不住关键信息点。移除推理(仅SFT+反事实)的模型,则像一位直觉敏锐但表达不清的专家——决策准确但不稳定,容易过拟合。
更有趣的是,单纯增加置信度预测任务(confidence prediction)只能带来边际提升。当与完整的CaRT结合时,置信度模块几乎没带来额外好处。这说明**推理本身已经编码了足够的价值评估信息**,额外的置信度分数成了冗余。
### 🎨 **平滑的决策边界:推理的隐式正则化**
图6展示了三个示例对话的终止率曲线,揭示了推理的深层作用。基线模型几乎从不终止,像个胆小的学徒不敢下结论。SFT基线则机械地随对话长度增加而提高终止率,像个按表操课的实习生。
而CaRT(SFT+CF+推理)展现出**优雅的阶梯状曲线**:在信息量跃升的节点,终止概率陡增;在其他时刻保持平稳。这种"平滑的敏锐"表明,推理不仅帮助决策,还起到了**隐式正则化**的作用,防止模型在训练数据上过拟合。
表1的表示分析进一步证实这一点。在直接分类任务上,仅反事实训练的模型(CaRT - reason)表现最好,但当用逻辑回归替换最终层时,**完整CaRT的泛化能力显著更强**。这就像一位只会背答案的学生和一位真正理解原理的学生——前者在熟悉题上得分高,后者在新题面前更可靠。
---
## 🌌 **第六章:超越终止——通往更智能的AI**
### 🔄 **统一框架:探索与终止的共舞**
CaRT的成功也暴露了其当前局限:它假设信息收集策略是固定的,只优化终止时机。但现实中,**问什么问题和何时停止是耦合的**——一个愚蠢的问题可能让最优终止变得毫无意义。
未来工作指向一个更宏大的愿景:**联合优化探索策略和终止决策**。这就像不仅要教司机何时刹车,还要教他如何选择路线。可能的路径包括课程学习(curriculum training),先学好探索,再学终止;或者使用密集奖励,让模型在每个步骤都获得关于信息质量的反馈。
### 🎯 **显式价值估计:从隐式到显式的跃迁**
目前CaRT通过反事实对比来**隐式**近似价值函数。但研究者提出,引入显式的价值估计或不确定性建模可能让终止更稳健。这就像从"摸着石头过河"到"有地图导航"的进化。
训练LLM的价值函数是一个开放挑战。传统RL的价值网络在语言空间中容易失效,但CaRT的"语言化推理"提供了新思路:**也许价值函数本身就应该是一个生成过程**,通过语言模拟来评估未来。
> **注解**:不确定性建模(Uncertainty Modeling)指的是量化模型对其预测的信心程度。在终止决策中,这涉及估计"继续收集信息"的期望信息增益。显式建模可以帮助AI在分布外场景中更保守地决策,避免过度自信导致的错误终止。
---
## 💡 **尾声:知止而后有定**
《大学》有言:"知止而后有定,定而后能静"。CaRT教会AI的,正是这种古老的东方智慧——**知道何时停止,才能锚定真正的目标**。
从医疗诊断到数学推理,CaRT展示了一条让LLM更"自知"、更"自律"的路径。它不仅是技术方法的创新,更是AI认知架构的一次深刻反思:**智能的本质不在于知道更多,而在于知道什么足够**。
随着AI系统越来越多地介入高风险决策,从医疗到金融,从法律到教育,"何时停止"将成为比"如何行动"更关键的伦理和能力问题。CaRT像一盏探照灯,照亮了这个被忽视的角落。
未来的AI助手,或许会在给出答案前,像一位沉思的智者,先问一句: **"我已经知道足够了吗?"**
---
## 📚 **核心参考文献**
1. **Liu, G., Qu, Y., Schneider, J., Singh, A., & Kumar, A.** (2025). *CaRT: Teaching LLM Agents to Know When They Know Enough*. arXiv:2510.08517v1. 本文提出的核心方法,通过反事实轨迹对和显式推理教会LLM最优终止决策。
2. **Setlur, A., et al.** (2024). *Rewarding Progress: Scaling up Automated Data Generation for Test-Time Compute*. 该工作论证了test-time compute本身提供信息增益,为CaRT将内部推理形式化为信息收集过程提供了理论基础。
3. **Gandhi, K., et al.** (2024). *Stream of Search (SoS): Learning to Reason, Search, and Generate*. 在数学推理领域的工作,启发了CaRT将推理过程分割为剧集(episodes)进行评估的实验设计。
4. **Singhal, P., et al.** (2024). *Craft-MD: A Benchmark for Medical Diagnosis with LLMs*. 医疗诊断数据集基准,为CaRT的医学实验提供了评估框架和数据来源。
5. **Touvron, H., et al.** (2023). *Llama 2: Open Foundation and Fine-Tuned Chat Models*. 作为基线模型和奖励模型使用的基础架构,代表了当前开源LLM的技术水平。
---
登录后可参与表态
讨论回复
1 条回复
✨步子哥 (steper)
#1
11-08 23:39
登录后可参与表态