破解"思考幻觉" LLM在汉诺塔问题中的性能崩坏与确定性循环分析
破解"思考幻觉"
LLM在汉诺塔问题中的性能崩坏与确定性循环分析
核心发现
当盘子数超过临界点后,模型成功率从90%骤降至接近零
失败模式
陷入无法逃脱的确定性循环,反复执行无效动作序列
近期由苹果公司发布并引发广泛争议的研究《思考的幻觉》揭示了一个核心现象:大型推理模型(LRMs)在处理具有可控复杂性的逻辑谜题时,其表现并非随着问题难度的增加而平稳下降,而是在达到某个特定的复杂性阈值后,出现急剧的性能崩坏。
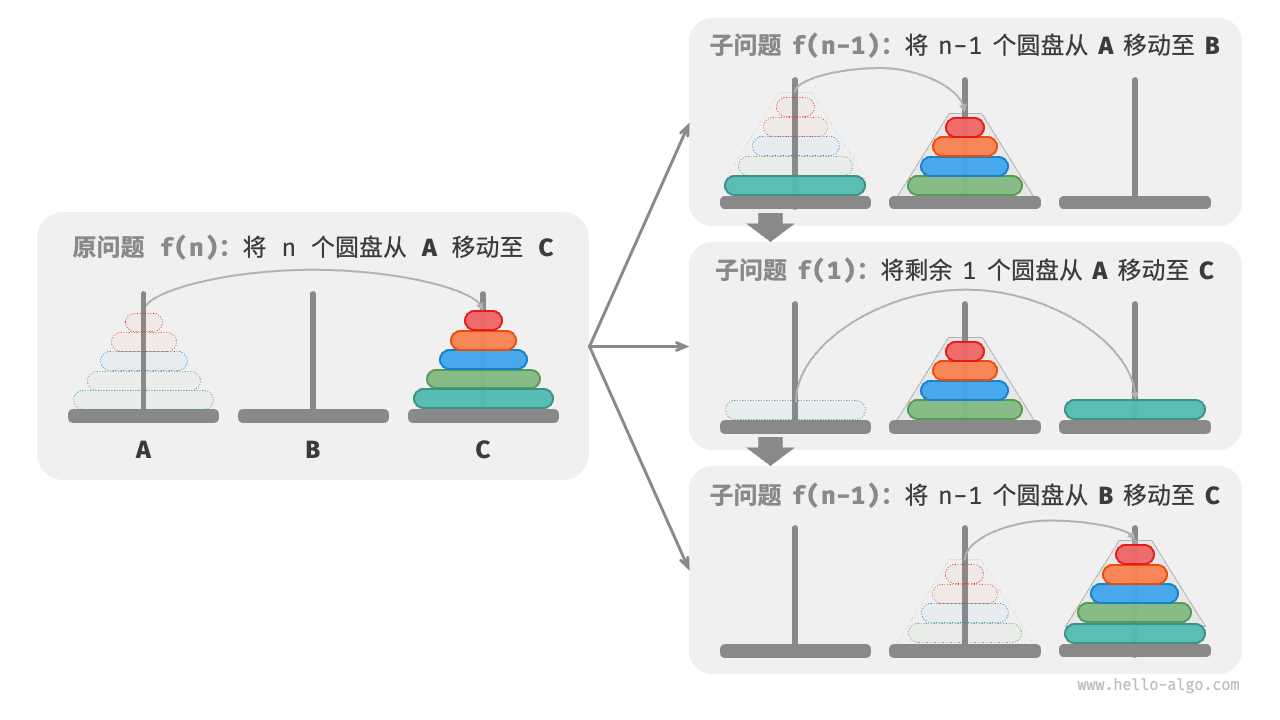
为了精确评估模型的推理能力,研究人员选择了经典的汉诺塔(Towers of Hanoi)问题作为核心测试平台。该问题具有明确的规则、确定性的状态空间以及一个与盘子数量直接相关的、可量化的复杂度指标。
实验结果清晰地展示了"性能崩坏"现象。当盘子数量较少时(3-4个),模型通常能够成功解决问题。然而,当盘子数量增加到5个或6个时,模型的成功率会从接近完美骤降至几乎为零。
这种急剧的性能下降并非一个渐进的、可预测的过程,而是一种突发的、灾难性的失败。
进一步的分析揭示了模型性能随复杂度变化的三个明显阶段:
标准LLM表现更优,直接高效 推理模型(LRM)利用链式思考展现优势 所有模型成功率骤降至零
苹果公司的原始研究观察到一个非常规现象:当任务处于模型能够解决的复杂度范围内但接近能力上限时,模型会消耗最多的Token。然而,当任务复杂度进一步提升时,它会戏剧性地减少其输出长度。
这种Token使用量的锐减,暗示模型可能具备一种内部的、尽管是粗糙的、对任务难度的评估机制。
即使在实验中向模型提供了显式的、正确的递归算法,它在处理高复杂度的汉诺塔问题时依然会失败。这有力地证明了模型的失败并非源于找不到正确的算法。
模型无法在高复杂度下维持递归调用的深度和状态跟踪,这是其架构性的根本局限。
核心发现:LLM推理能力的"思考幻觉"与性能崩坏
现象概述:从卓越到崩溃的临界点
汉诺塔问题作为测试平台
性能崩坏的临界点
三阶段性能表现模型
低复杂度
中复杂度
高复杂度
反直觉的行为模式:推理努力的减少
Token使用量的非线性关系
递归算法的执行失败
"确定性循环"指的是当LLM在解决汉诺塔问题的过程中遇到障碍时,它不会尝试新的策略或进行回溯,而是会陷入一个预先确定的、无效的移动序列中。
这个序列在多次运行中对于相同或相似的状态是可重复的,因此被称为"确定性"的。
模型在合法移动中进行无限循环,每一步在局部看来都是合法的,但从全局来看却构成了无法逃脱的闭环。这种行为可以被描述为"明知故犯"。
在无非法移动的情况下无法收敛到有效解
研究发现,Transformer模型主要通过"匹配操作"来实现多步推理。它将整个推理过程视为一个序列,并在每一层中通过注意力机制匹配相关的信息片段。然而,对于需要深度递归和状态栈管理的复杂问题,这种将多步推理简化为线性化子图匹配的方法存在根本性的局限。
LLM的成功在很大程度上取决于其能否在训练数据中找到与当前问题高度相似的"计算图"或解题路径。对于汉诺塔问题,3-4个盘子的解法在训练数据中普遍存在。
当盘子数量增加到5-6个时,完整的解题路径(2^n - 1步)在训练数据中变得极其稀疏甚至不存在。
真正的逻辑推理能力意味着能够根据问题的基本规则,动态地发展和适应新的解题策略。然而,LLM在面对新结构复杂性时,表现出的是完全的失效,而非适应。
模型无法从零开始推导出递归解法,也无法在试错中学习到新的启发式规则。
失败根源剖析:确定性循环与模式匹配的局限性
确定性循环:模型失败的核心行为模式
确定性循环定义
表现形式:明知故犯
无限循环
循环特征
根本原因:高级"模式匹配"而非真正逻辑演绎
Transformer模型的组合推理局限
训练数据依赖
面对新复杂性的失效
该智能体框架的核心设计哲学是"减负",即将所有与记忆和状态跟踪相关的复杂任务从LLM身上剥离,转交给一个外部的、确定性的环境模块来处理。
测试LLM在没有长期记忆负担的情况下,进行动态规划和多步决策的能力。
最基础的交互方式,模型每一步接收结构化提示,包含当前状态、规则和明确指令。
旨在引导模型进行单步的、局部的最优决策
多个LLM智能体(规划者、执行者)通过对话协作,引入不同"视角"和"角色"。
旨在激发更深层次的规划和反思
MAP架构将复杂规划分解为冲突监控、状态预测、状态评估等专门功能模块。
模仿人脑的模块化规划机制
核心目标是系统地记录和分析LLM在解决汉诺塔问题时的行为序列,特别是当问题复杂度超过其能力阈值时,是否会以及如何陷入循环。
分析模型生成的移动指令序列,寻找重复的子序列。
判定标准:连续多次执行完全相同的移动序列
智能体框架(Agentic Framework)设计与交互模式
框架核心目标:剥离记忆负担,测试纯粹推理能力
设计哲学:减负
外部化状态管理
多步交互模式
LLM与环境的具体交互方式
交互方式
核心机制
目标
高复杂度表现
逐步提示
模型在每一步接收当前状态并生成下一步动作
测试单步决策和局部规划能力
依然会陷入确定性循环
智能体对话
多个LLM智能体通过对话协作
通过角色分工和协作激发深层次规划
最终仍会陷入无限循环
模块化智能体规划器
将规划任务分解为专门模块
模仿人脑模块化结构
在3-4个盘子表现优异
逐步提示
智能体对话
模块化规划器
实验设计:验证与观察确定性循环
实验命名:"Hanoi Loop"
交互流程
循环检测机制
当问题复杂度增加,状态空间变得庞大且陌生时,注意力机制可能会变得"困惑"。由于缺乏明确的、可匹配的模式,注意力权重可能会固化和坍缩到一些在训练数据中最常见的、但与当前问题无关的模式上。
过度关注最大盘子,反复关注源柱和目标柱,忽略辅助柱的复杂中间步骤
大型语言模型本质上是"黑箱",其内部拥有数千亿甚至数万亿的参数,注意力权重和中间层表示的精确含义极其复杂,难以直接解读。虽然有一些可视化工具可以尝试分析注意力模式,但要清晰地建立起"某个特定的注意力分布"与"陷入循环"之间的因果关系,仍然是一个开放的研究难题。
LLM倾向于选择概率最高的下一个Token,这种"贪婪"策略在生成流畅文本时有效,但在解决逻辑谜题时可能成为障碍。
正确的下一步可能并非统计上最明显的,导致缺乏探索精神
Transformer架构本身并不具备内在的递归机制。它通过注意力机制建立长距离依赖,但这与递归调用所需的保存和恢复调用栈状态的能力完全不同。
模型只能通过学习递归实例来"模拟"递归,而无法真正"执行"递归
LLM的推理过程可比喻为"记忆灌输"。在复杂问题上,内部张量表示可能无法容纳所需信息,导致"崩溃"。
模型退回到最保守的行为模式,重复基础动作,形成确定性循环
LLM在汉诺塔问题上陷入"确定性循环"并最终导致"性能崩坏",其根源深植于其内部架构和生成机制的内在局限性。这并非简单的"不够聪明",而是Transformer模型在处理特定类型复杂问题时的根本性能力边界。
在复杂问题上趋向于固化,无法动态调整关注点
贪婪性采样策略缺乏探索精神,易陷入局部最优
内部机制探析:为何模型会陷入确定性循环
注意力机制的潜在作用
注意力分布的固化
观测挑战:黑箱模型的局限性
生成过程的局限性
自回归采样的贪婪性
递归机制的缺失
记忆灌输与崩溃
核心洞察:架构性的根本局限
注意力机制
生成过程
本研究揭示了当前大型语言模型在推理能力方面的根本性局限,为人工智能领域的未来发展提供了重要的理论指导和实践参考。
理解这些局限不仅有助于我们更好地应用现有技术,也为开发真正具备通用推理能力的新一代AI系统指明了方向。
研究启示与未来展望
关键发现
未来方向
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens