
摘要
该论文《Verifying Chain-of-Thought Reasoning via Its Computational Graph》提出了一种名为"基于电路的推理验证"(Circuit-based Reasoning Verification, CRV)的白盒方法,旨在通过分析大型语言模型(LLM)在思维链(CoT)推理过程中的内部计算图结构,来验证其推理步骤的正确性。 [479]
其核心思想是,正确与错误的推理步骤会在模型的计算图上留下截然不同的"结构指纹"。通过将模型的MLP模块替换为可解释的"转码器",CRV能够构建归因图,提取结构特征,并训练分类器以高精度预测推理错误。
实验表明,CRV在多个任务上显著优于现有基线方法,并能通过干预特定特征来因果性地纠正错误,为AI的可解释性、安全性和可靠性研究开辟了新的道路。 [484]
核心思想与贡献
研究背景
思维链(CoT)推理已成为提升LLM性能的核心方法,但其可靠性仍面临挑战。研究表明,LLM生成的CoT文本有时并不能准确反映其内部的真实推理过程,这种现象被称为"不忠实的CoT"。 [389]
现有的黑盒和灰盒验证方法存在根本性局限:它们只能检测到模型的内部状态与错误相关,但无法解释为什么底层的计算过程会导致错误。
核心假设
正确与错误的推理步骤在模型内部的计算图上会留下截然不同的"结构指纹"。正确的推理步骤对应的归因图呈现清晰、有序的结构,而错误的步骤则表现出混乱、纠缠的特征。 [479]
这种结构上的差异,如同指纹一样,是推理正确与否的独特标识,为白盒验证提供了理论基础。
提出CRV白盒方法
通过分析计算图直接验证推理过程,将验证焦点从输出转移到内部计算结构
发现错误特征可预测性
推理错误的结构指纹具有高度可预测性和领域特异性,在合成任务上准确率达92%
实现因果性干预
不仅能检测错误,还能通过干预特定特征因果性地纠正错误推理
方法论:基于电路的推理验证
CRV整体流程概述
CRV是一个系统性的四步流程,旨在将LLM的推理过程从不透明的"黑盒"转变为可检查的"白盒"。整个流程通过分析模型在推理过程中产生的计算图结构特征来判断推理步骤的正确性。 [488]
模型可解释化改造
使用可解释的"转码器"替换MLP模块
构建归因图
为每个推理步骤建立因果信息流图
提取结构特征
从图中提取可解释的特征
训练分类器
基于特征预测推理正确性
步骤一:模型可解释化改造
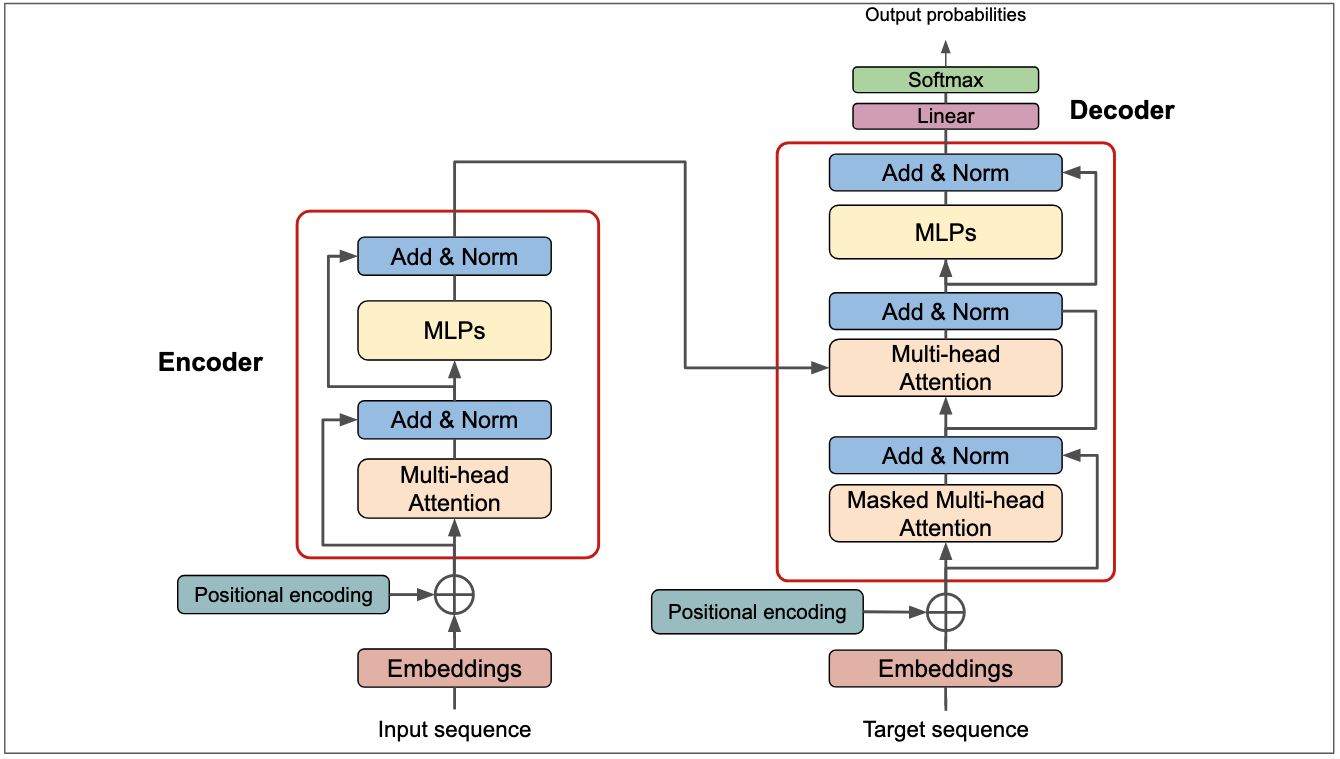
通过用可解释的"转码器"(transcoder)替换模型中标准的MLP模块,将原始模型改造为内部计算透明的版本。 [505]
转码器的关键作用:
- • 精确模拟原始MLP的输入-输出函数
- • 增强稀疏性,只激活少数可解释特征
- • 将密集向量转换为人类可理解的概念
步骤二:构建归因图
为每个推理步骤构建归因图,捕捉模型内部特征和组件之间的因果信息流。该图以节点和边的形式清晰展示计算过程。 [506]
构建方法:
- • 从最终logits向后追踪
- • 保留高归因分数的连接
- • 构建稀疏加权有向图
步骤三:提取结构特征
全局图统计
节点数、边数、图密度、聚类系数
节点影响统计
节点度、中心性、激活值统计
拓扑路径特征
最长路径、平均路径、环路检测
步骤四:训练诊断分类器
利用提取的结构特征训练诊断分类器,仅根据图结构特征预测推理步骤的正确性,实现自动化验证。 [488]
分类器优势:
- • 独立于模型输出和激活状态
- • 可实时进行推理过程监控
- • 在多个指标上超越基线方法
实验结果与分析
对AI安全与可解释性的潜在影响
AI可解释性贡献
- 从"黑盒"到"白盒":提供推理过程的内部视图
- 机制性理解:揭示模型"如何"以及"为何"犯错
- 可视化推理轨迹:将抽象思维具象化为计算图谱
AI安全性影响
- 提升模型可靠性:提前预测并诊断推理错误
- 实现可控智能:为实时干预和纠错提供可能
- 推动AI安全审计:为高风险领域提供透明度
产业生态与未来
- 重塑AI开发与运维(MLOps)流程
- 催生AI透明度审计与安全认证服务
- 开源计划推动社区共同构建可靠AI
未来展望
"CRV方法的出现,标志着AI可解释性研究从简单的'错误检测'迈向了更深层次的'因果理解和修复',为实现可控、可靠的AI系统铺平了道路。" [485]
局限性
计算成本高昂
从训练大量转码器到构建归因图,整个过程需要巨大的计算资源,目前主要适用于学术研究,难以直接应用于实时生产环境。
对转码器质量的依赖
CRV的有效性完全依赖于转码器能否精确模拟原始MLP功能并学习可解释特征,目前训练高质量转码器仍具挑战性。
总结
核心结论
《Verifying Chain-of-Thought Reasoning via Its Computational Graph》通过提出基于电路的推理验证(CRV)方法,在AI可解释性和安全性领域取得了重大突破。该研究证实,大型语言模型的推理过程并非不可捉摸,其正确与否会在内部计算图上留下可识别、可预测的"结构指纹"。 [479]
CRV不仅能够以远超现有方法的精度验证推理步骤的正确性,更重要的是,它通过因果性干预实现了从"理解"到"控制"的飞跃。这种方法为构建更透明、更可靠、更安全的AI系统提供了全新的理论基础和强大的实践工具。
重要价值
- • 科学价值:首次实现LLM推理过程的白盒验证,推动机制性可解释性研究
- • 应用价值:提供强大的推理错误检测和修复工具,提升AI系统可靠性
- • 社会价值:为高风险领域AI应用提供安全审计基础,建立公众信任