
提示工程在生命科学中的应用
深度研究与实践指南
思维生成
通过逐步推理实现复杂逻辑分析
分解技术
将复杂任务拆解为可管理的子任务
集成方法
多路径验证提升结果可靠性
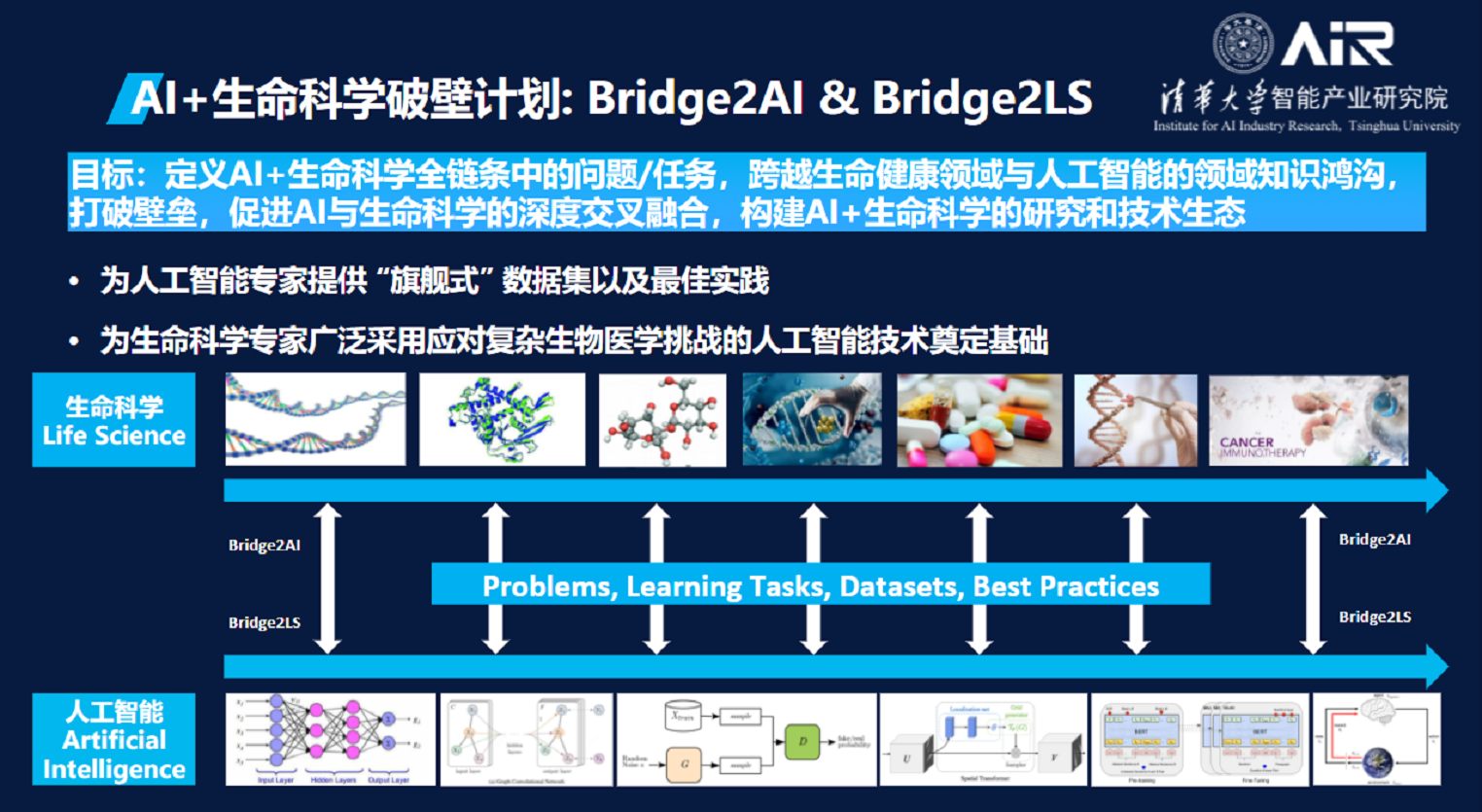
引言:AI驱动的生命科学研究新范式
《The Prompt Engineering Report Distilled: Quick Start Guide for Life Sciences》为生命科学研究人员提供了一套系统化的框架,旨在通过掌握核心的提示工程技术,将大型语言模型(LLM)从简单的工具转变为强大的科研伙伴。该报告的核心贡献在于将复杂的提示工程领域提炼为六种核心技术,并将其与生命科学的实际应用场景紧密结合。
六种核心技术框架
快速、通用任务处理
领域特定、模式化任务
复杂逻辑推理
提升结果可靠性
优化输出质量
处理复杂流程
通过将这些技术应用于文献综述、数据提取、假设生成和论文编辑等核心科研任务,研究人员可以显著提升工作效率。成功的关键在于遵循明确的提示构建原则,规避如模型"幻觉"等常见陷阱,并通过迭代优化来不断完善提示策略。 [91]
核心提示工程技术:原理与应用
零样本提示 (Zero-Shot Prompting)
依赖模型内置知识与精确指令
技术原理
零样本提示完全依赖于LLM在预训练阶段积累的庞大知识库和泛化能力。用户不提供任何示例,仅通过精心设计的自然语言指令引导模型完成任务。其成功与否的关键在于指令的清晰度、精确性和完整性。 [93]
适用场景
- • 任务定义清晰、目标明确的通用任务
- • 高质量示例难以获取的场景
- • 对令牌消耗有严格限制的任务
- • 生物信息学数据库查询、术语标准化
应用案例
文献分类
快速筛选阿尔茨海默病药物发现相关论文
术语标准化
统一基因名称和蛋白质标识符
少样本提示 (Few-Shot Prompting)
通过示例引导模型学习特定模式
技术原理
通过在提示中提供少量(2-5个)高质量的输入-输出示例,"教会"模型如何执行类似任务。示例充当了任务的"模板",模型通过分析这些示例来理解复杂模式、领域特定规则和期望的输出风格。 [88]
关键要点
- • 示例质量远比数量重要
- • 展示推理过程比简单输入-输出更有效
- • 对示例选择和顺序高度敏感
- • 适用于领域特定、模式化任务
生命科学应用
基因序列分类
通过示例学习序列特征与功能关联
实验数据解读
解读高通量筛选结果,识别"命中"化合物
示例结构
思維生成 (Thought Generation)
引导模型进行逐步推理
思维链 (Chain-of-Thought, CoT)
通过要求模型在给出最终答案之前,先生成一系列中间的、逻辑连贯的推理步骤,模拟人类解决复杂问题时的思考过程。 [89]
零样本CoT提示
"让我们一步一步地思考"
简单的提示后缀即可显著提升推理能力
适用场景
- • 多步逻辑推理问题
- • 生物通路分析
- • 实验设计逻辑推导
- • 需要透明推理过程的任务
生命科学案例
p53信号通路分析
分析DNA损伤时p21蛋白表达变化及其对细胞周期的影响
集成 (Ensembling)
整合多个输出以提高可靠性
自我一致性 (Self-Consistency)
使用思维链生成多个不同的推理路径和答案,然后通过多数投票选择出现频率最高的答案。其背后的原理是正确的推理路径往往比错误的路径更"受欢迎"。 [88]
实现步骤
- 1. 使用CoT生成多个推理路径
- 2. 收集所有生成的答案
- 3. 进行多数投票选择最终结果
- 4. 可选:根据置信度加权
关键应用
药物毒性预测
高风险决策需要高置信度
疾病靶点识别
降低假阳性率
不良反应预测
提高预测覆盖率
自我批评 (Self-Criticism)
让模型评估并修正自身输出
评估维度
- • 事实准确性:科学事实是否正确?
- • 逻辑一致性:推理是否严密?
- • 完整性:是否遗漏重要信息?
- • 清晰度:表达是否清晰易懂?
生命科学应用
论文草稿校对
模拟同行评审过程,发现逻辑漏洞
实验结论验证
挑战初步结论,提出其他解释
提示:自我批评技术在处理需要精细推理和事实核查的复杂任务时尤为有效。 [108]
分解 (Decomposition)
将复杂任务拆解为可管理的子任务
"计划-执行-整合"流程
计划阶段
分析任务,识别子任务,确定依赖关系
执行阶段
为每个子任务设计专门提示并处理
整合阶段
收集子任务输出,组合成完整答案
复杂任务示例
系统性文献综述
关键词生成,数据库查询
纳入/排除标准应用
关键信息结构化提取
结果整合与报告生成
生命科学特定任务的实用策略
文献综述与总结
自动化生成特定研究领域的进展报告
核心策略:分解 + 思维生成
主题定义与关键词生成
明确核心问题,生成全面关键词列表
文献检索与筛选
调用学术API,初步筛选相关文献
单篇文献深度分析
使用CoT分析研究问题、方法、发现和局限性
跨文献综合与主题聚类
结合自我批评,生成结构化报告
案例:肠道微生物组与帕金森病
迭代提示流程
分解为:微生物组成、代谢物通路、肠-脑轴、临床模型、治疗干预
生成MeSH术语:gut microbiota, Parkinson disease, gut-brain axis
分析50篇核心论文,识别研究范式和矛盾
生成包含证据链分析和未来方向的报告
效率提升:数小时vs数周的人工综述时间
数据提取与结构化
从临床试验报告中提取关键疗效指标
少样本提示策略
通过提供3-5个精心设计的"输入文本-期望输出"示例,清晰展示所需提取的信息类型、表现形式和期望的结构化输出格式。
示例结构设计
示例1: 客观缓解率 (ORR)
"实验组ORR为45.3%(95% CI: 37.2% - 53.4%),显著高于对照组的20.1%,p < 0.001"
{
"疗效指标": "客观缓解率 (ORR)",
"实验组数值": "45.3%",
"实验组95%置信区间": "37.2% - 53.4%",
"对照组数值": "20.1%",
"p值": "< 0.001",
"统计显著性": "是"
}
关键要素
定义提取目标
明确需要提取的实体、关系或事件类型
构建高质量示例
覆盖各种可能变体和边缘情况
设计输出格式
明确规定JSON、表格或键值对格式
批量处理优势
通过少样本提示策略,研究团队可以批量处理数百份临床试验报告,快速获得标准化的、可直接用于统计分析的数据集,极大加速荟萃分析进程。
科学假设生成
基于现有研究发现新的药物-靶点相互作用
迭代优化策略
结合思维生成与自我批评,构建"生成-批判-修正"的演进过程,将初步想法打磨成具有高度可行性的研究计划。
初始生成
发散性思维,产生多个假设
批判评估
严格审视科学性、新颖性
精炼整合
生成高质量最终假设
案例:阿尔茨海默病新靶点
研究背景
基因X在AD患者大脑中显著下调,但其功能尚不明确。团队希望发现新的药物-靶点相互作用。
提出基因X影响AD病理的三种假设机制
进行SWOT分析,评估每个假设的科学性
整合最佳假设,设计验证实验方案
优势与价值
突破思维定势
从海量文献中发现新的关联
提升假设质量
通过多轮批判确保科学严谨性
加速发现过程
系统化的假设生成与验证
预期成果
- • 1-2个高质量研究假设
- • 完整的分子机制阐述
- • 详细的实验验证方案
- • 潜在风险评估与缓解策略
编辑与校对任务
提升学术论文的语言质量与逻辑清晰度
双层次编辑策略
宏观结构编辑
运用自我批评技术,评估论文整体逻辑和结构
- • 创新性评估
- • 研究设计审查
- • 数据分析合理性
- • 结论支持度
微观语言润色
运用零样本提示,精细化修改语言细节
- • 语言简化
- • 语法检查
- • 术语统一
- • 格式规范
分步实施流程
扮演资深教授,批判性审阅"讨论"部分
语言简化、语法检查、风格统一
重新整合成连贯流畅的完整部分
质量提升效果
提示构建方法论与最佳实践
提示构建的核心原则
明确任务目标
用具体的动词定义任务:"总结"、"分类"、"提取"、"比较",而非模糊的"分析一下"
定义输出格式
详细说明预期格式:JSON、Markdown表格、列表等,减少后续处理工作
提供充足上下文
包含必要的背景知识、领域信息和相关文献,确保模型理解完整背景
常见陷阱与规避策略
上下文退化
LLM上下文窗口有限,长对话中早期信息可能被"遗忘",导致响应失去连贯性。 [91]
规避策略
- • 定期重述关键上下文信息
- • 使用摘要技术管理对话长度
- • 在每个新提示开头简要回顾任务目标
模型"幻觉"
模型生成看似合理但实际上虚假、不准确或无中生有的信息,在生命科学领域可能造成严重后果。
减少策略
- • 使用RAG技术提供可信外部信息
- • 鼓励模型表达不确定性
- • 应用自我批评进行事实核查
- • 始终保持批判性思维,交叉验证
模型能力边界认知
不同模型的推理能力存在差异,对非推理模型提出复杂推理任务往往导致失败。
GPT-4, Claude 3等,适合复杂多步推理任务
适合基于知识的语言生成任务
58种提示工程技术概览
六大核心类别
上下文学习 (ICL)
通过示例引导模型学习
思维生成
增强复杂逻辑问题解决能力
分解
将复杂任务拆解为子任务
集成
组合多个输出提高可靠性
自我批评
模型自我评估和反思
零样本提示
仅依赖指令,无示例
技术选择决策矩阵
| 技术类别 | 复杂性 | 数据需求 | 准确性 | 效率 |
|---|---|---|---|---|
| 零样本提示 | 低 | 无 | 中 | 高 |
| 少样本提示 | 中 | 少 | 高 | 中 |
| 思维生成 | 高 | 中 | 高 | 低 |
| 集成 | 高 | 中 | 极高 | 极低 |
| 自我批评 | 高 | 中 | 极高 | 低 |
| 分解 | 极高 | 中 | 高 | 中 |
技术选择决策流程
结论与展望
《The Prompt Engineering Report Distilled: Quick Start Guide for Life Sciences》为生命科学研究人员提供了一个系统化的框架,将复杂的提示工程领域提炼为六种核心技术。通过掌握这些技术并将其应用于文献综述、数据提取、假设生成和论文编辑等核心科研任务,研究人员可以显著提升工作效率和科研质量。
核心贡献
- • 系统化的六种核心技术框架
- • 生命科学特定任务的实用策略
- • 提示构建的方法论指导
- • 58种技术的全面分类体系
实践价值
- • 从简单工具到强大科研伙伴的转变
- • 显著减少重复性劳动时间
- • 提升研究假设的质量和创新性
- • 加速知识发现和验证过程
未来发展方向
自动化提示工程
DSPy等框架的自动提示优化
多模态整合
结合图像、结构数据的提示技术
协作式AI
人机协作的科研新模式
"成功的关键在于遵循明确的提示构建原则,规避常见陷阱,并通过迭代优化来不断完善提示策略。这不仅是技术的掌握,更是科研范式的革新。"
— 基于《The Prompt Engineering Report Distilled》核心理念