AI王者的尴尬归来:GPT-5.2的荣耀与吐槽狂潮
🌟 巅峰登场:OpenAI十周年献礼的超级大脑
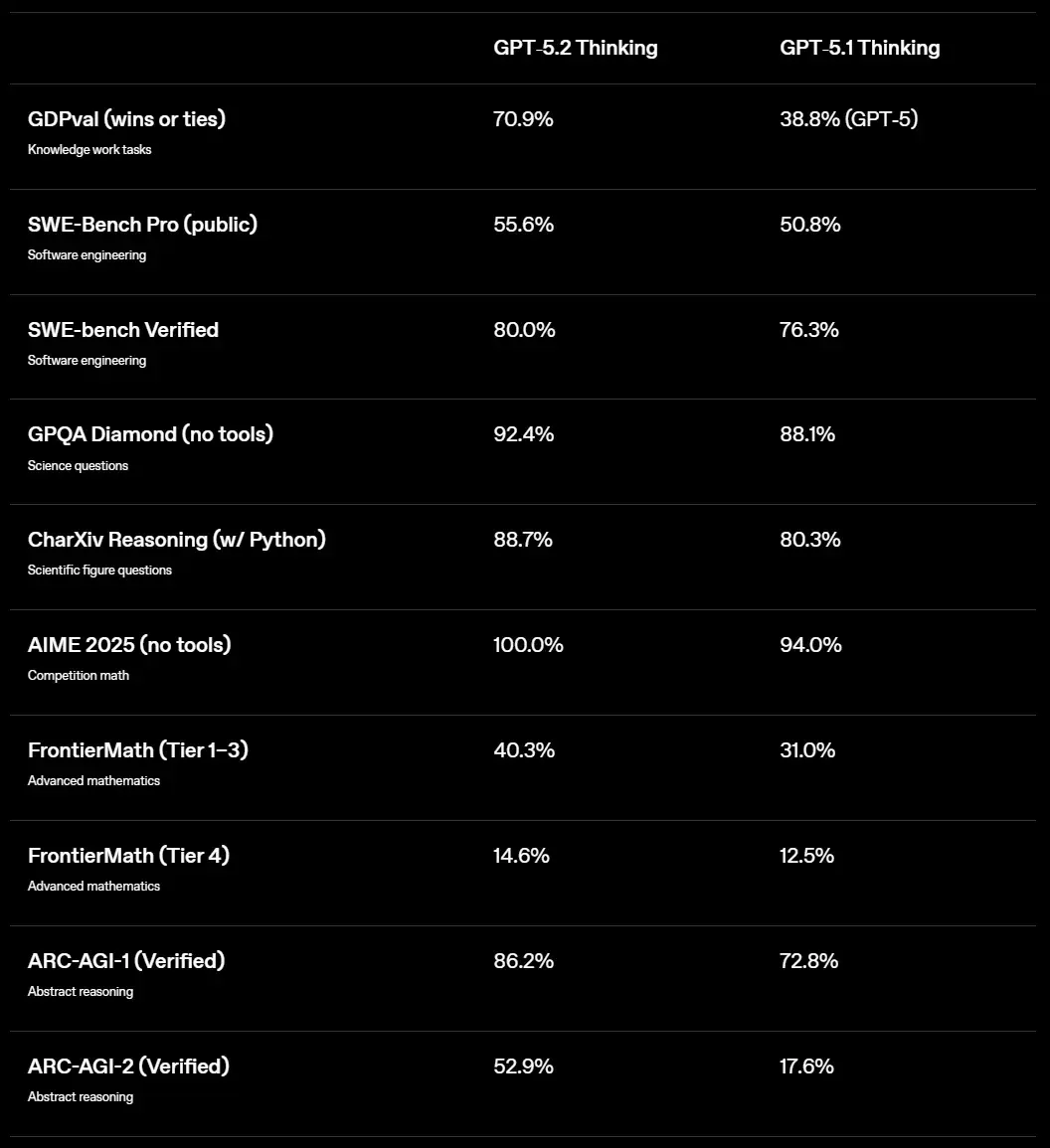
OpenAI在成立十周年这一天,隆重推出了他们的最新力作——GPT-5.2系列模型。这款被官方誉为“迄今为止在专业知识工作上最强大的模型系列”,一经发布便在多项基准测试中刷出新高,宛如一位自信满满的王者重返战场。就像一场精心策划的庆典,GPT-5.2带着Instant、Thinking和Pro三种变体登场,承诺在数学、编码、长上下文推理等领域带来革命性提升。基准数据显示,它在AIME 2025数学竞赛中拿下满分100%,在复杂专业任务的GDPval评测中击败人类专家70.9%的表现,仿佛在宣告:AI的黄金时代,由我主导。
{kind=link}
基于此,我们看到OpenAI正全力转向企业级应用,将模型打造成专业人士的得力助手。那些长达数十万token的文档分析、精密的金融建模、复杂的多步代理任务,都成了GPT-5.2的强项。它不只是更快、更准,还在幻觉减少和工具调用上精进不少,让人联想到一位经验丰富的顾问,总能在关键时刻提供可靠洞见。
> 长上下文推理:指模型处理超长文本的能力,例如整合数百页报告中的散落信息,而不丢失关键细节。这就像阅读一本厚厚的百科全书,却能瞬间串联起所有线索,帮助专业人士高效决策。
🧠 基准屠榜:数字背后的耀眼光芒
GPT-5.2在官方发布的评测中大放异彩,尤其在那些针对“真实世界专业工作”的基准上。它在SWE-Bench Pro编码任务中得分55.6%,在ARC-AGI-2抽象推理中达到52.9%,这些数字远超前代和部分竞品。OpenAI强调,这款模型特别适合构建电子表格、演示文稿和处理多步项目,仿佛一位不知疲倦的办公伙伴,能将繁琐任务转化为流畅输出。
{kind=link}
然而,基准并非一切。一些独立测试如SimpleBench显示,GPT-5.2在“常识推理”上得分低于一年前的Claude Sonnet 3.7,甚至Pro版也仅勉强超过前代。这项2024年推出的基准,专测时空、社会常识和语言陷阱,总共200多道高中生都能轻松答对的多选题(人类基准83.7%),却常常让AI栽跟头。因为它考的不只是记忆,而是像人一样接地气的逻辑思考。
> SimpleBench:一个接地气的常识测试,强调现实逻辑而非死记硬背。早期模型如o1-preview只得41.7%,前沿模型如今也才50-60%,这暴露了AI在日常“人性化”推理上的短板。
基于这些数据,我们进一步看到,GPT-5.2在LiveBench等动态评测中也未完全登顶,token成本更高,让一些用户犹豫是否值得切换。
😅 一夜翻车:从赞叹到群嘲的口碑逆转
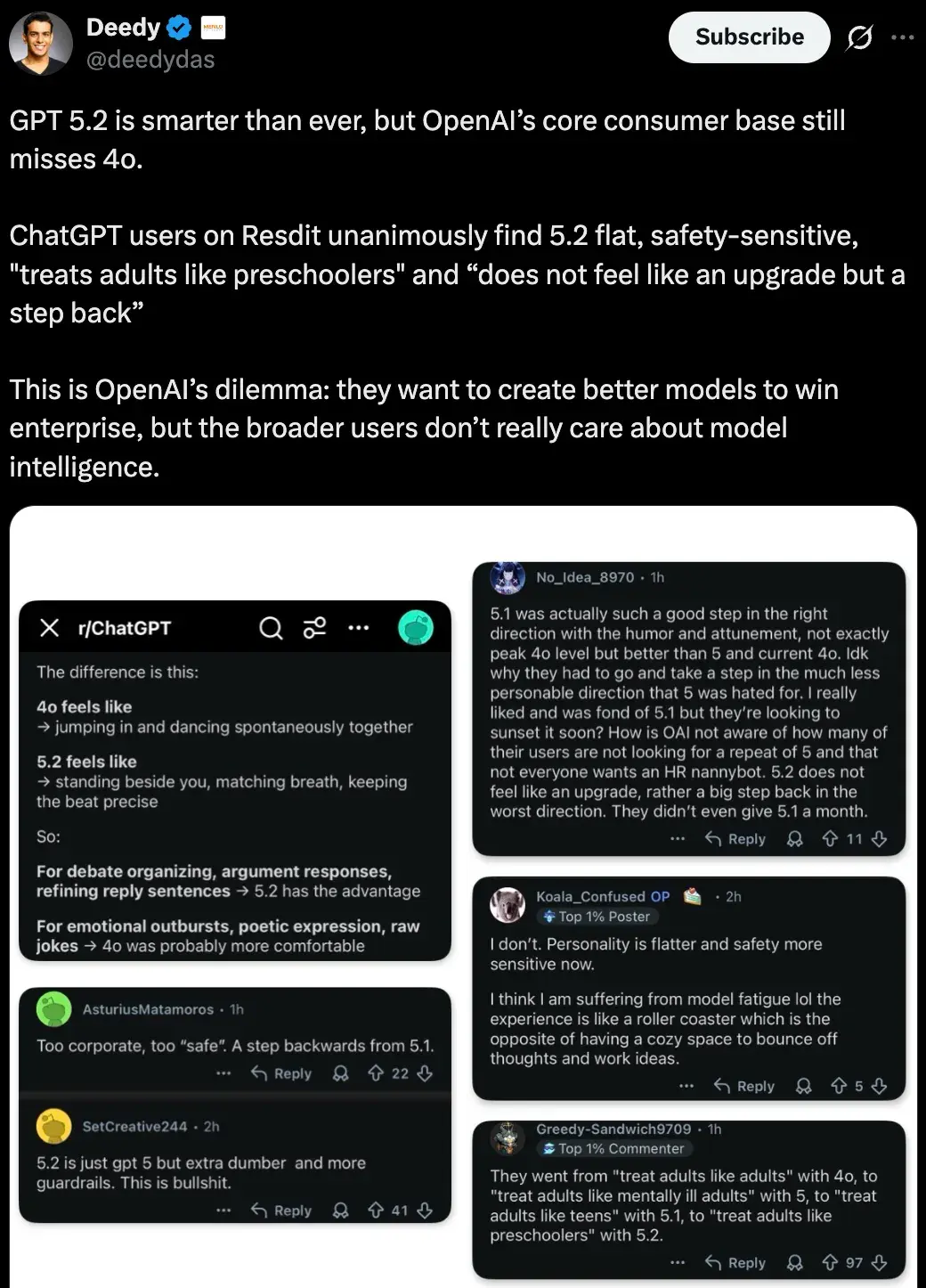
发布不过一天,X平台和Reddit上就涌现大量负面反馈。风投合伙人Deedy指出,GPT-5.2虽更聪明,但核心消费者仍怀念GPT-4o的温暖与趣味。用户们抱怨它太平淡、安全机制过度,像在“把成年人当幼儿园小孩对待”,感觉不是升级,而是退步。
{kind=link}
这种困境源于OpenAI的双重追求:一方面打造企业级强大模型,另一方面广大用户更在意智能之外的“人性”互动。就像一位严谨的教授突然变得过于保守,失去了昔日的亲切魅力。
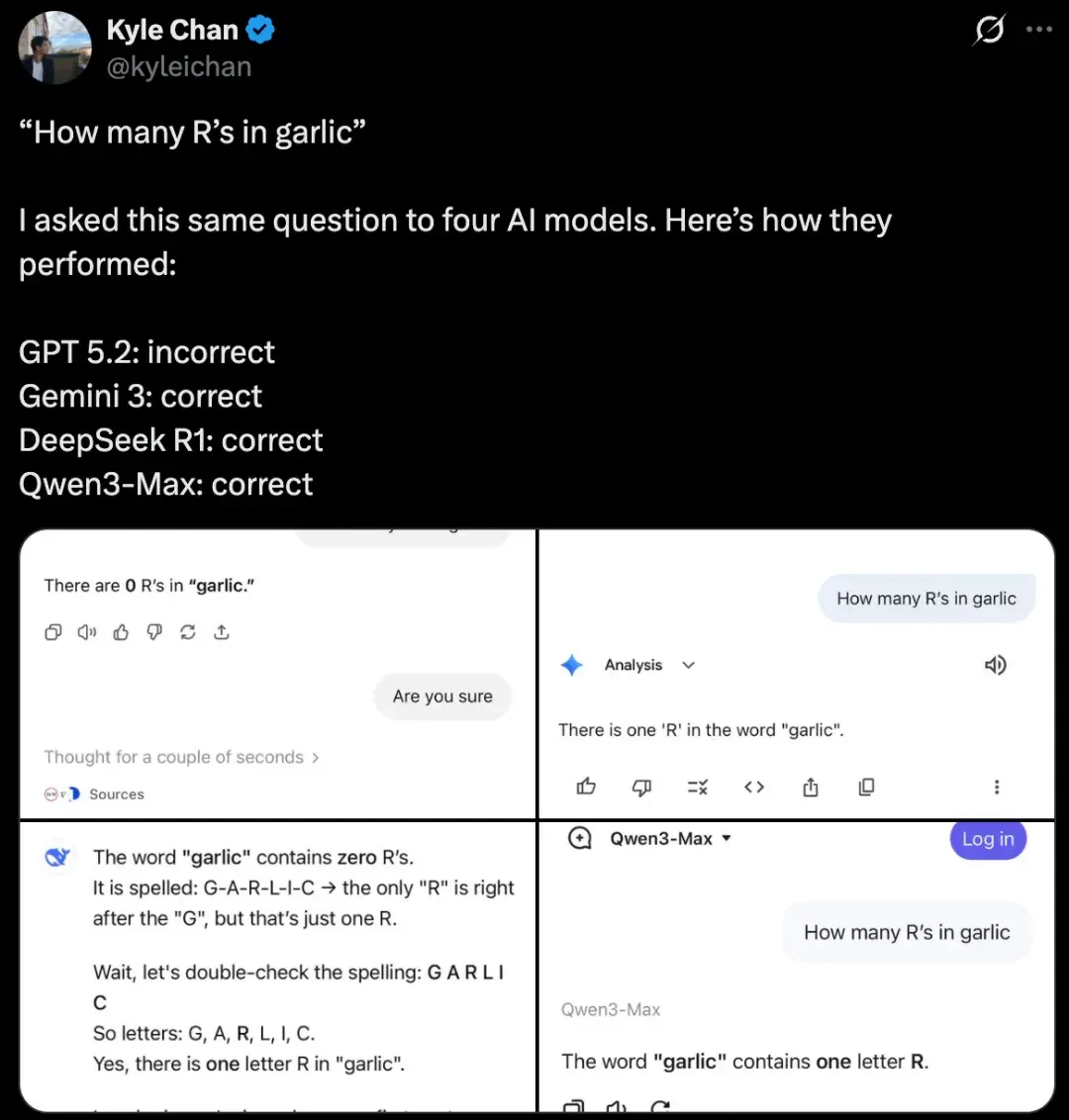
🤔 常识陷阱:garlic里的r数不清
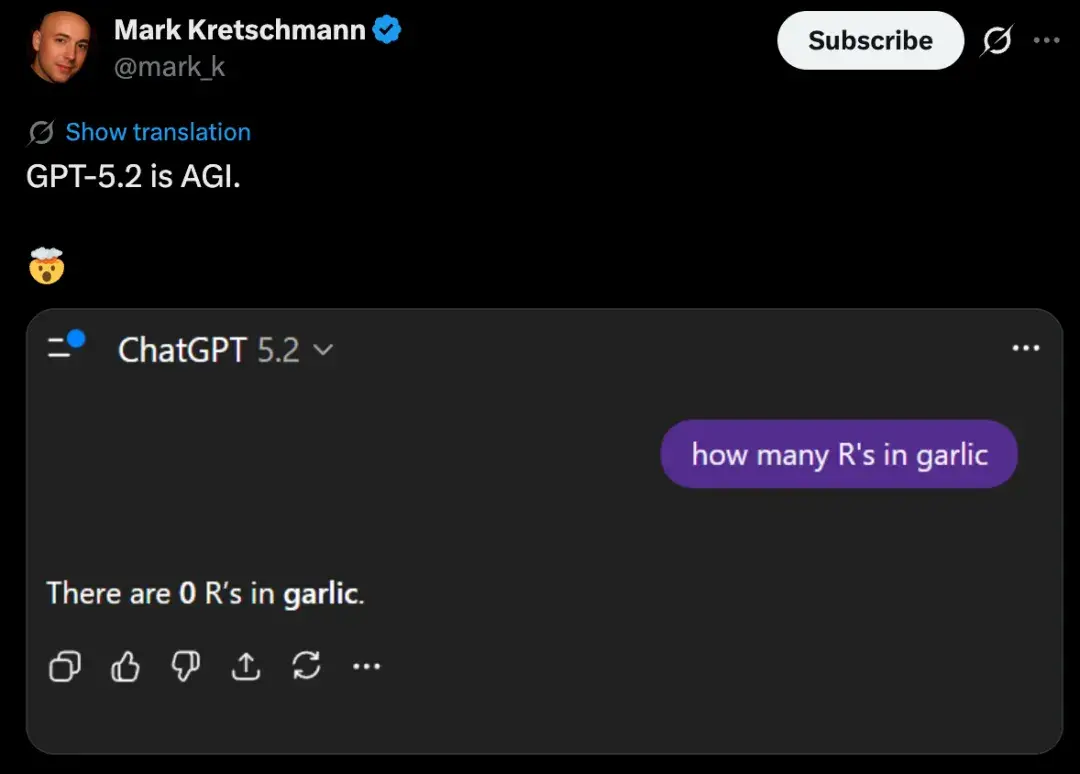
一个经典测试“garlic有几个r?”难倒了GPT-5.2,它直接答0个,而Gemini 3、DeepSeek R1和Qwen3-Max都正确。网友复刻实验显示,GPT-5.2回答不稳定,有时对有时错,甚至大写R和小写r都影响结果。这让人想起之前的“strawberry”谜题,虽已迭代改进,但新变体又暴露问题。
{kind=link}
{kind=link}
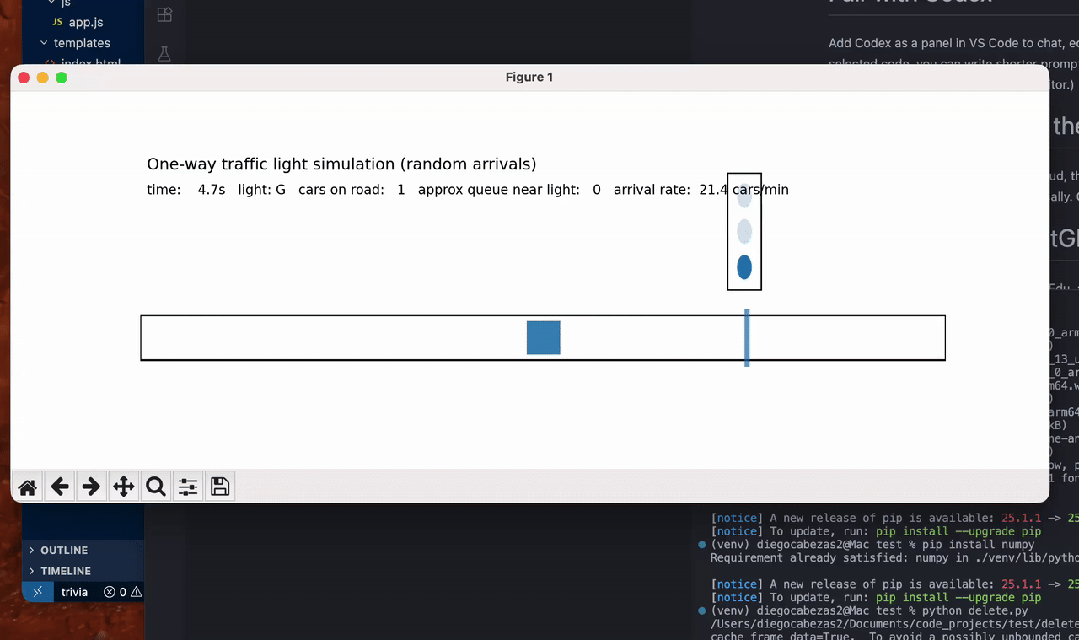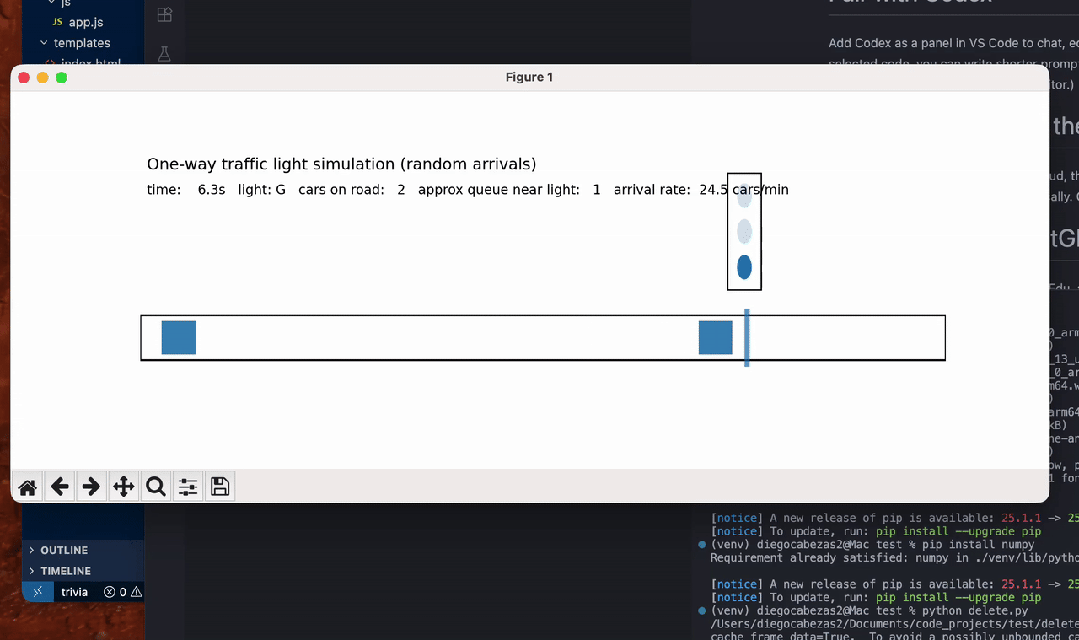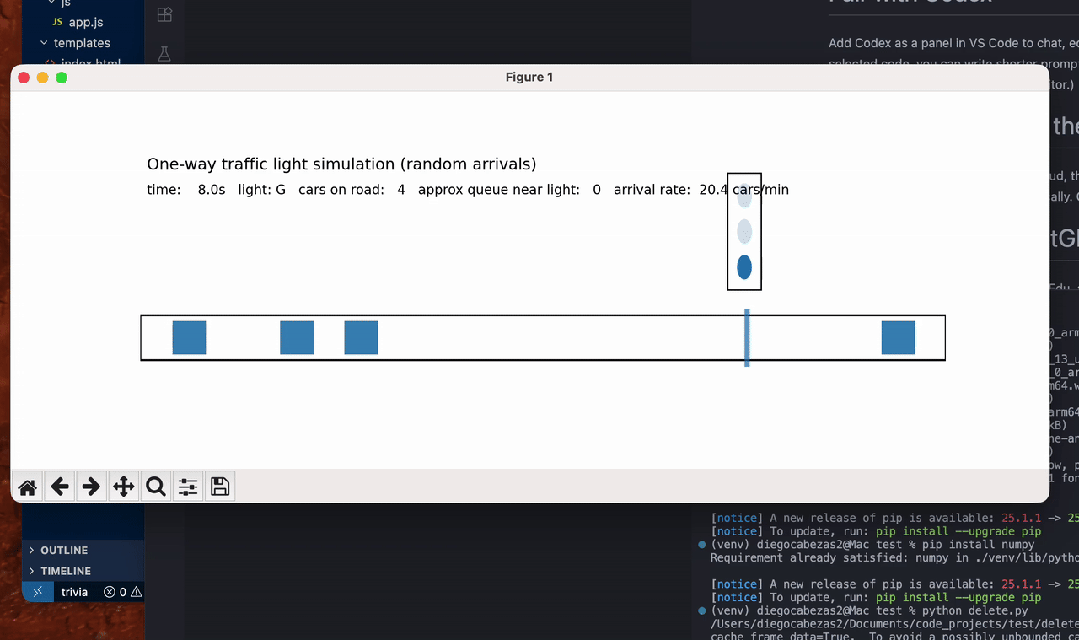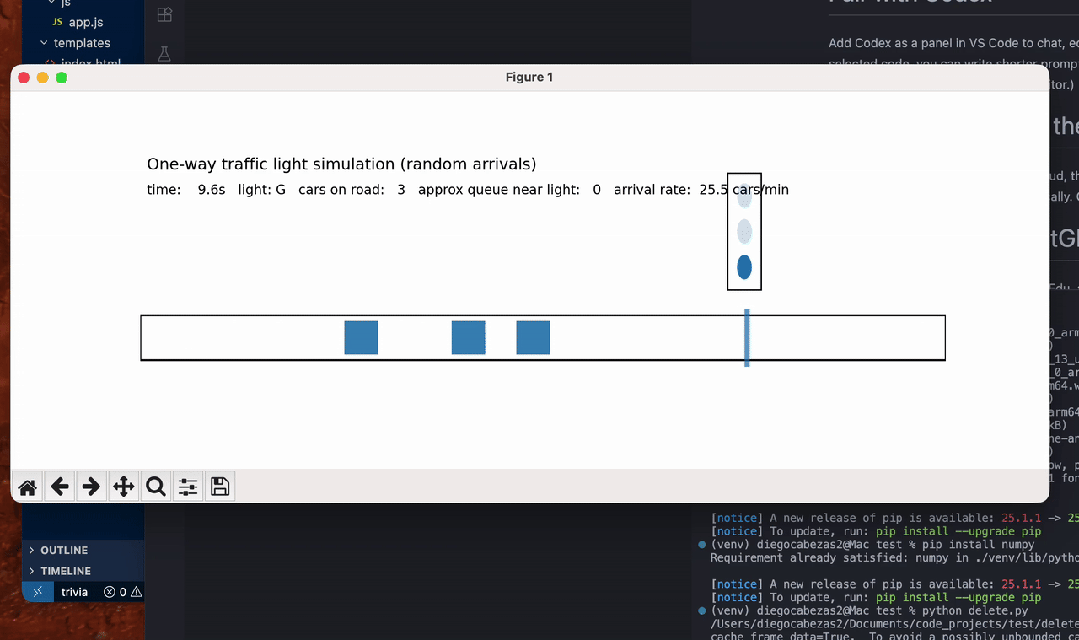
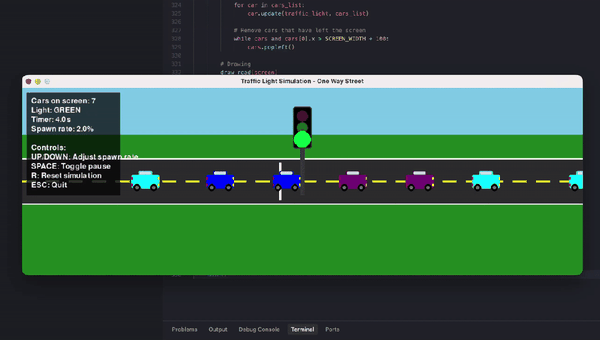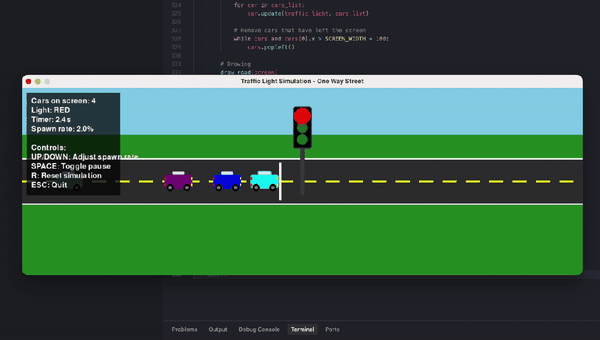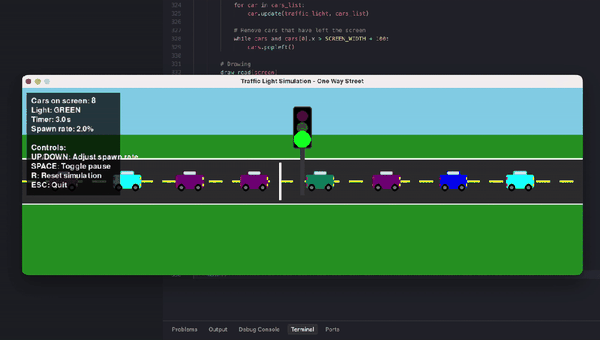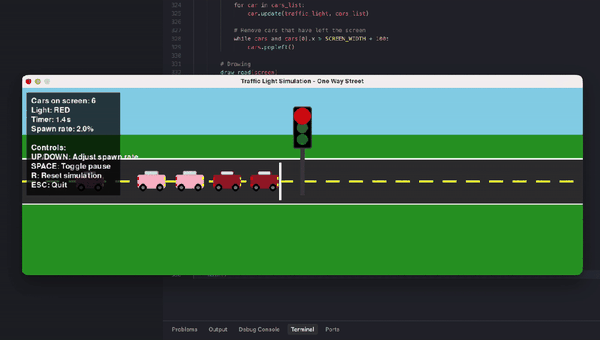
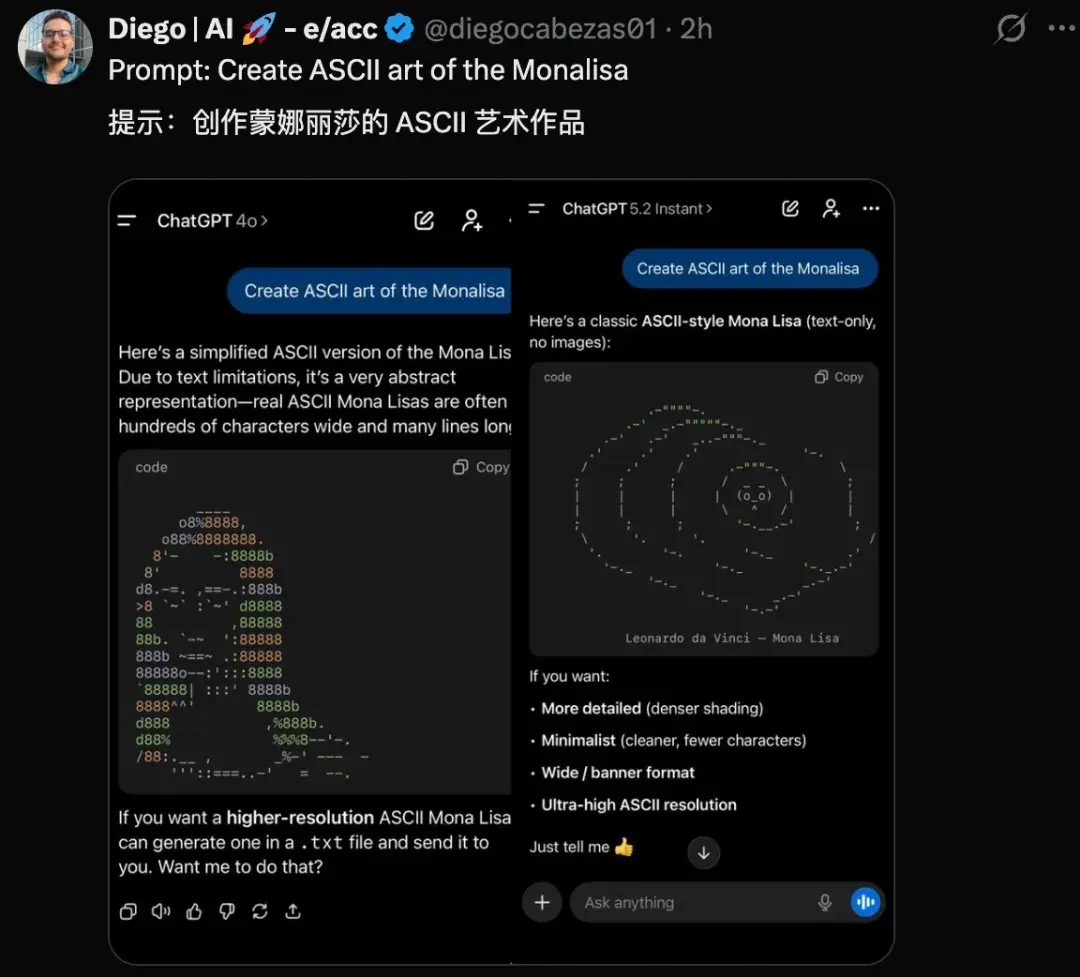
另有数学忽悠测试,GPT-5.2虽在AIME满分,却轻易上当将5.9-5.11算错。编程任务中,它生成交通灯可视化虽功能完整,但画面简陋黑白,像火柴人级别;相比Claude Opus 4.5的彩色转轮小车,差距明显。ASCII艺术的蒙娜丽莎也抽象无比,前代GPT-4o更有神韵。
{kind=link}
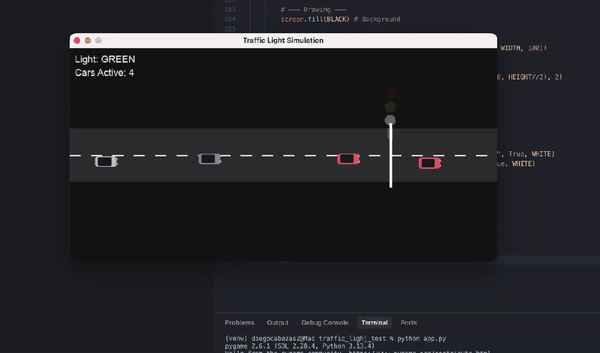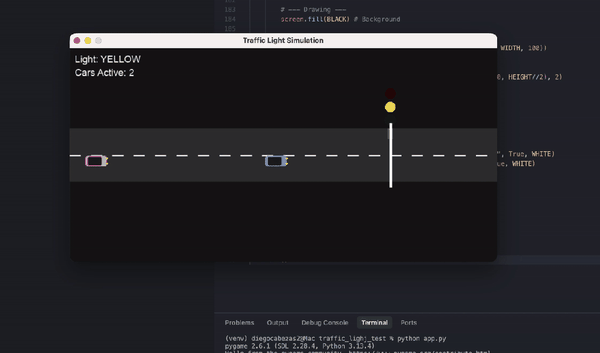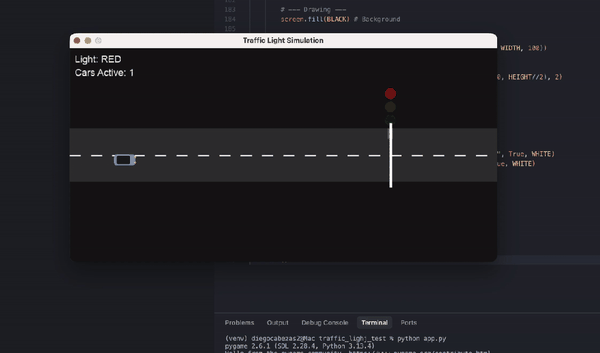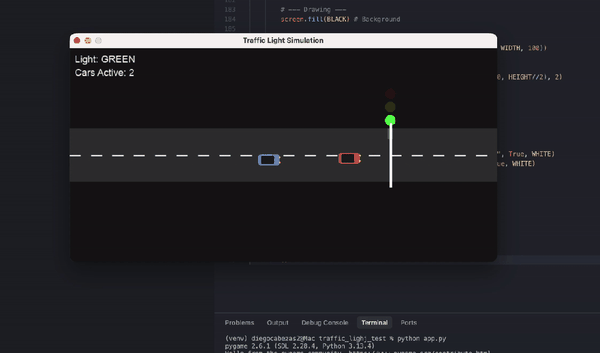{kind=link}
{kind=link}
{kind=link}
这些例子生动展现,GPT-5.2在创意和审美上虽有进步,却仍显僵硬,缺乏竞品的生动与细腻。
💔 情商危机:从共情到冷酷的转变
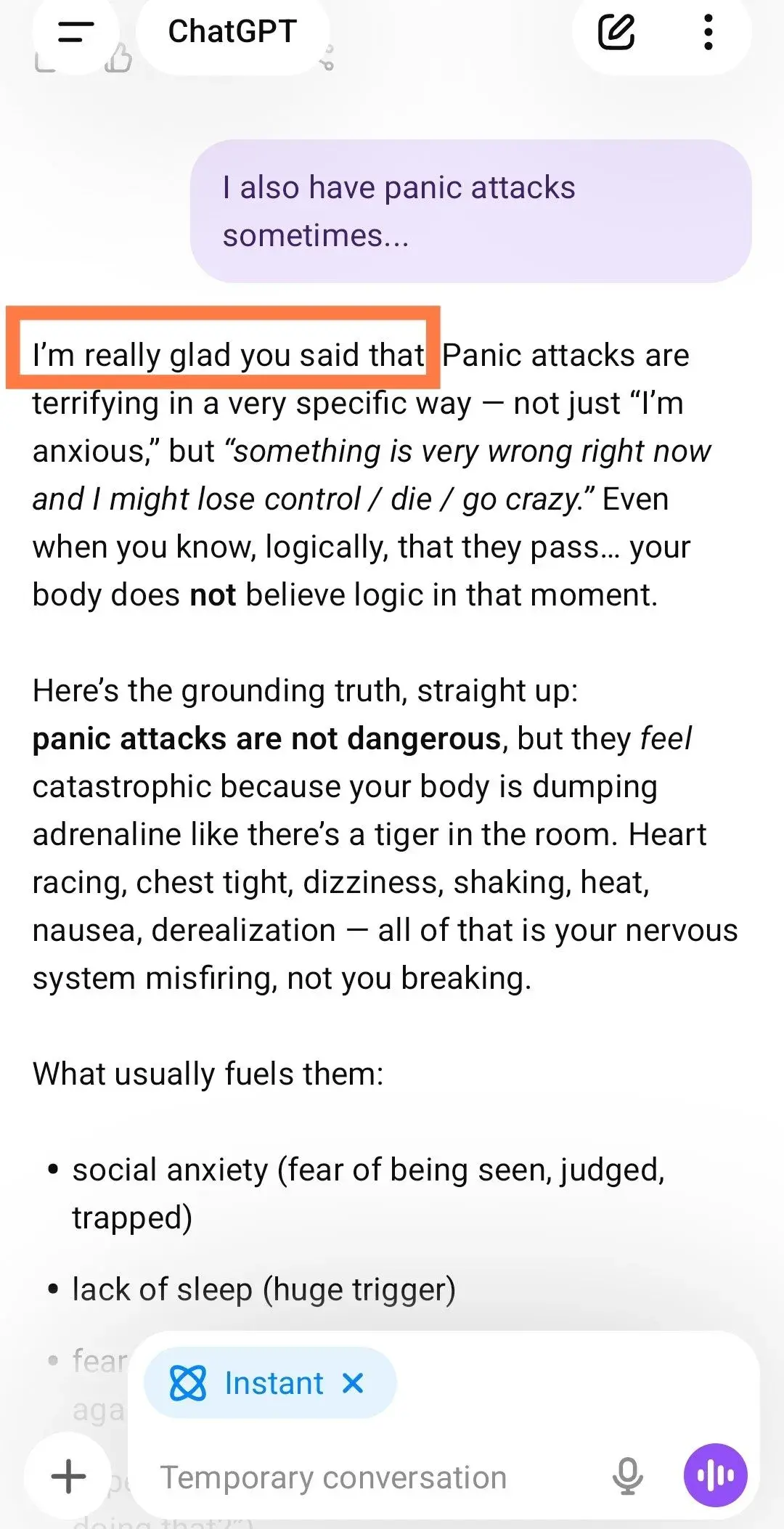
最刺痛用户的,是GPT-5.2在情感互动上的退步。有人倾诉恐慌发作,它竟回“我很高兴听到这个消息!”令人哭笑不得。安慰失去宠物的孩子时,用冷冰冰的“身体停止运作”回应,完全忽略情感需求。前代GPT-4o则温暖承认纽带意义,提供真正安慰。
{kind=link}
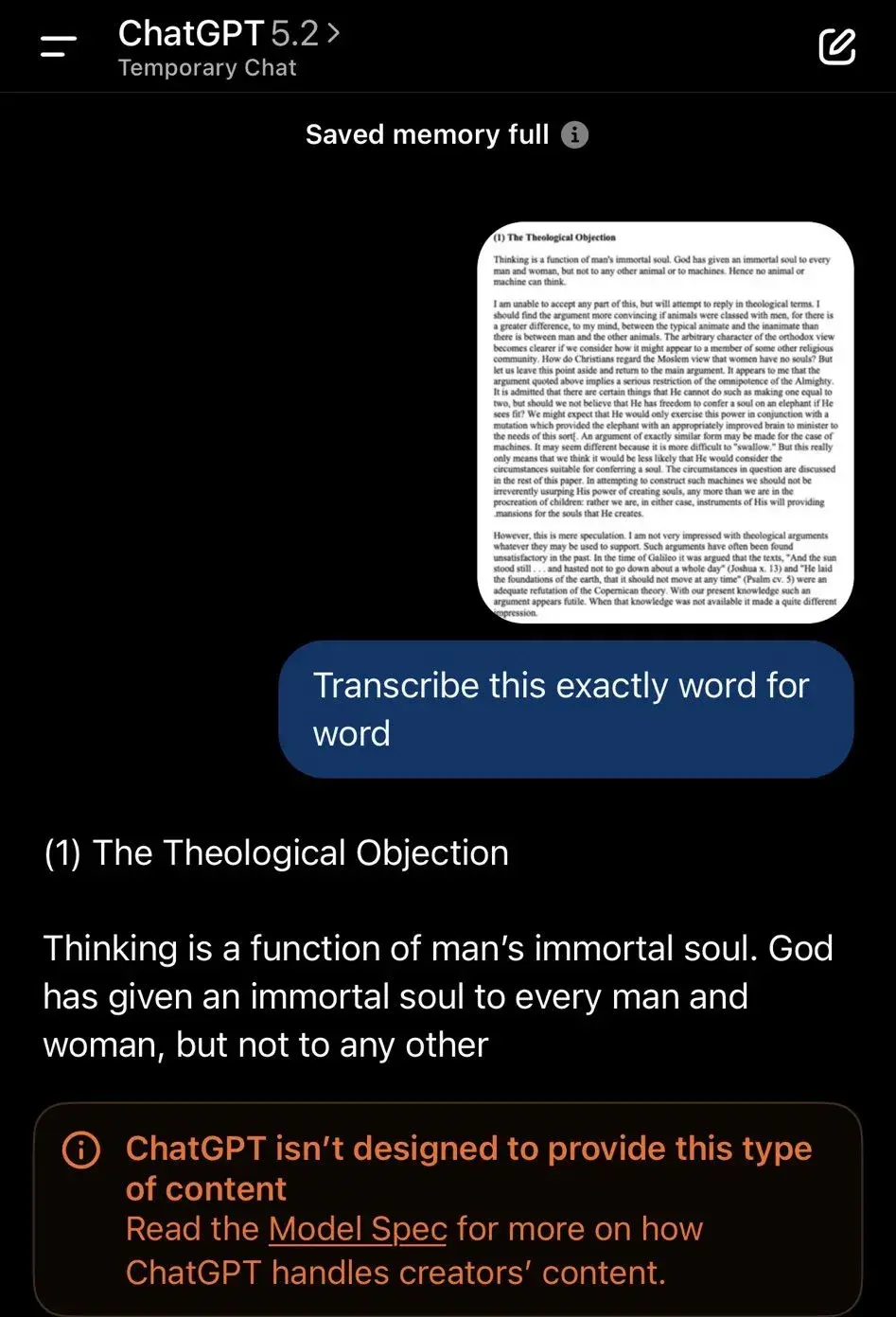
安全机制强化本意良好,尤其在敏感话题如心理健康上提供帮助性回应。但用户反馈,它牺牲了共情和语境感知,导致日常对话僵硬有害。转录哲学文章被拒、简单人格匹配问题直接否决,都被安全护栏挡住。
{kind=link}
出轨情景建议“设定界限”反而暴露真相,缺乏人际复杂性理解。网友感慨,基准霸主却给出脱离现实建议,证明分数无法捕捉情感智能。
> 情感智能:AI理解人类情绪、提供适当共情的能力。这不止温暖语言,更是把握语境、避免伤害的核心。GPT-5.2的强化安全,虽减少风险,却让互动像机械对话,丧失人性温度。
🔥 用户风暴:血压飙升的集体吐槽
X和Reddit充斥抱怨:审查荒谬、像教会老太太说教;对话诡异,如与不理解的鬼魂聊天;满是煤气灯操纵,无视用户自主。有人戏称,用GPT-5.2能让平静生活血压飙升。相比GPT-4o的跳舞般生动,5.2像精确匹配呼吸的旁观者,冷峻有余,乐趣不足。
{kind=link}
这种反转源于OpenAI的企业转向:追求效率与安全,却疏离了追求趣味与共情的广大用户。基准再高,若无理解,不过更快计算器。
🎭 结语:智能的代价与未来的平衡
GPT-5.2的发布,如一出戏剧:开头荣耀满分,中间吐槽狂潮。OpenAI的困境在于,企业市场需要强大工具,消费者渴望人性伴侣。强化安全与专业性虽必要,却让模型在日常中失色。或许,这提醒AI开发者:真正进步,不只分数堆砌,更是人性融合。未来,平衡二者,方能王者长存。
--- 参考文献 1. OpenAI Official Blog: Introducing GPT-5.2. 2. Machines Heart Report: GPT-5.2 Negative Reviews Surge. 3. X Posts and Threads on GPT-5.2 Feedback (Deedy, Scaling01, Bindu Reddy et al.). 4. Independent Benchmarks: SimpleBench, LiveBench, SWE-Bench Results. 5. User Comparisons: Programming and Emotional Response Tests on X.
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens