在人工智能的广袤疆域中,一种新的架构正在悄然崛起,它的名字叫mHC——Manifold-Constrained Hyper-Connections(流形约束超连接)。这个名字听起来高冷,但它的演化历程却像一部层层递进的探险故事:从最基础的深度神经网络出发,遇到信息传递的瓶颈,于是发明了残差连接;残差还不够彻底,又诞生了更激进的超连接;超连接虽强大,却容易失控,最终在流形理论的指引下,获得了智慧的约束,形成了mHC。
这条脉络如此自然,仿佛水到渠成。今天,我们就沿着这条脉络慢慢走一遍,用最平易近人的方式,让每个人都能看懂这场技术革命的来龙去脉。
🌌 层层叠加的智慧之塔:深度神经网络的诞生
深度神经网络(Deep Neural Network,简称DNN)是现代人工智能的基石。它的核心想法很简单:把很多简单的计算单元(神经元)像搭积木一样层层堆叠,每一层都对输入数据做一次变换,最终得到复杂的输出。
用数学语言描述,每一层的计算可以写成:
\(y = f(x)\)
这里的 \(x\) 是本层的输入,\(f(\cdot)\) 是这一层学到的变换函数(通常包含线性变换和非线性激活),\(y\) 则是输出,交给下一层继续处理。
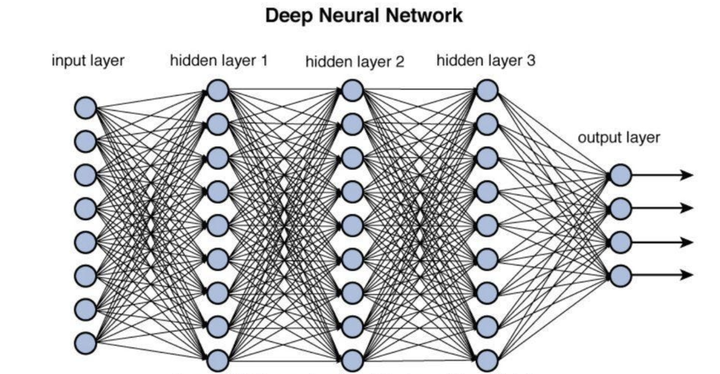
这么多层叠加在一起,理论上就能拟合极其复杂的函数,这正是深度网络强大的原因。可现实总有代价:层数越深,信息在层层传递中越容易衰减和失真。梯度消失、训练困难成了挥之不去的梦魇。
用一个生活化的比喻:就像一家超大型公司,CEO的战略意图要经过CTO → VP → Director → Team Lead → 基层员工,一层一层往下传。每传一层,信息都会被重新诠释、增添个人理解,最后到达基层时,原始意图可能已经面目全非。深度网络早期就面临这样的“信息曲解”危机。
🌉 残差连接:为信息修筑直达高速
为了解决信息衰减问题,2015年的ResNet提出了残差连接(Residual Connection),这是一个堪称天才的简单改动。
原来的 \(y = f(x)\) 变成了:
\(y = f(x) + x\)
也就是说,下一层拿到的不再只是本层加工后的结果 \(f(x)\),还直接加上原始输入 \(x\)。这条“捷径”让原始信息可以跳过若干层,直接往下传。

回到公司比喻:现在CEO的指令不再只靠CTO口头转述,CTO会把CEO的原话原文同时抄送给VP;VP再把CTO的理解+CEO原话一起发给Director……如此一路向下。基层员工最终既能看到上司的解读,又能直接对照最初的原始意图,信息保真度大幅提升。
正是这条小小的捷径,让深度网络可以轻松堆到上百甚至上千层,开启了深度学习的黄金时代。
🚀 超连接:打破层级,信息自由奔涌
残差连接虽然好,但本质上还是“单线捷径”——只加了输入本身。能不能让信息流动更丰富、更灵活?
DeepSeek团队提出的Hyper-Connections(HC,超连接)正是对残差的激进升级。它不再局限于简单相加,而是允许每一层向后续任意多层发送加权连接,甚至可以跨越好几层直接对话。
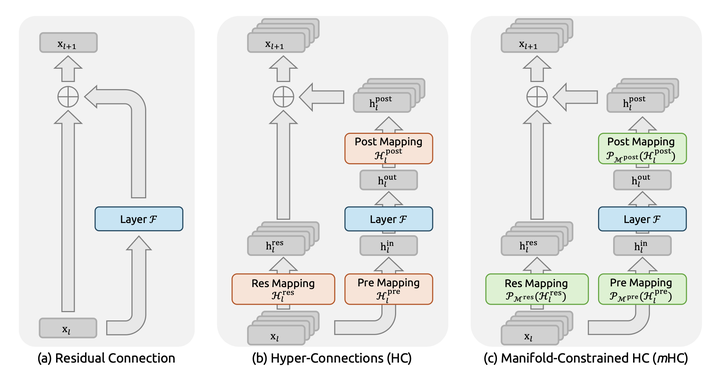
继续用公司比喻:现在不仅有原话抄送,还允许越级汇报。CEO觉得某条战略特别重要,可以直接给Director甚至Team Lead发强调版;CTO在转发时,对技术相关的指令加大权重,对财务相关的指令减弱权重。信息渠道变得多元而灵活,基层员工能根据需要收到最相关、最强化的信号。
理论上,这种多路径、加权的超连接能让关键信息传播得更彻底、更精准,远远超越传统残差。
🗺️ 流形的奥秘:高维世界的低维地图
要理解mHC为什么必要,先得认识一个数学概念——流形(Manifold)。
最直观的例子:地球表面实际上是三维球面上的二维曲面(不考虑高度)。但当我们看局部区域时(比如一张城市地图),完全可以当成平面二维来处理,信息几乎不损失。这就是“局部欧氏性”:近看像低维,整体是高维,这种结构就叫流形。
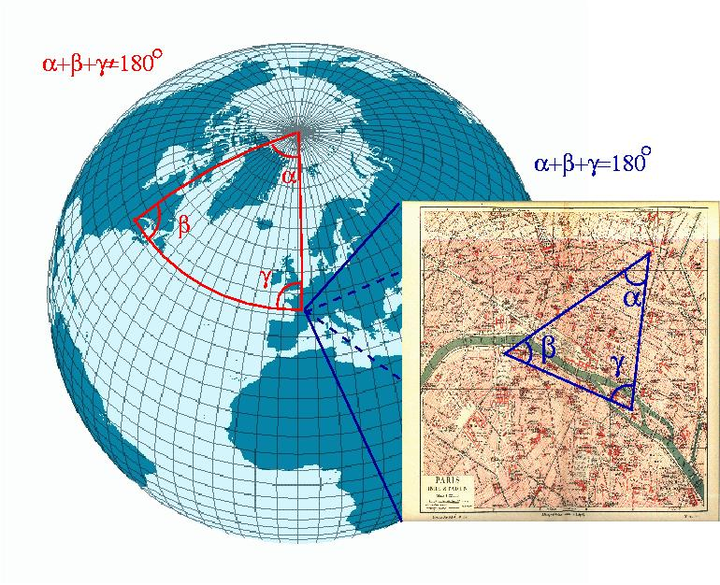
流形小注解
在机器学习中,我们相信真实数据(图像、文本、语音)虽然嵌入在极高维空间,但实际上分布在一个相对低维的流形上。换句话说,数据的“内在自由度”远低于原始维度。这就是为什么降维算法(如PCA、t-SNE)能有效工作——它们试图恢复这个低维流形。
不同网络层学到的表示,往往处于不同的抽象层次,因而可能躺在不同的流形上。浅层关注边缘、纹理,深层关注语义、概念,它们的“世界观”并不相同。
🔒 流形约束超连接:自由与秩序的平衡
HC虽然强大,但信息随意跨越层级也带来了新风险:高层抽象概念直接强行灌输给低层,可能造成语义不匹配、训练不稳定。
mHC(Manifold-Constrained Hyper-Connections)正是针对这一问题提出的解决方案:在超连接的基础上,增加流形匹配约束。只有当发送端与接收端的表示处于相容的流形(或者能够投影到对方能理解的子空间)时,才允许建立强连接或传递高权重。
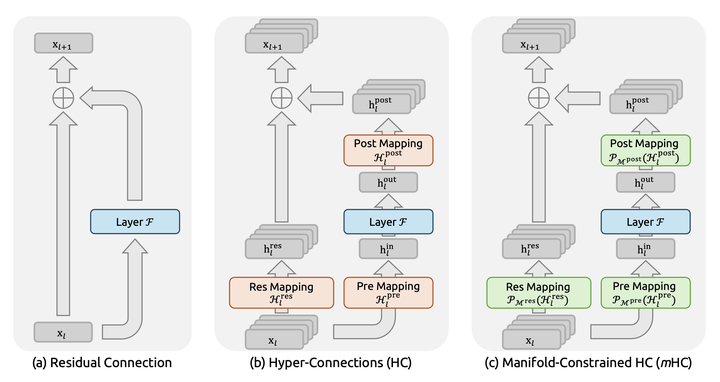
回到公司比喻:CEO的“KPI是提高产品质量”可以直接强调给基层程序员,因为“减少Bug”正是他们能理解的同一条流形上的表达;但CEO的“扩大融资额、开拓新市场”对程序员来说完全是另一个维度的语言,强行灌输只会造成混乱。mHC就像一个智能秘书:自动判断哪些指令适合跨层直达,哪些需要翻译或屏蔽,从而在保持信息充分流动的同时,避免语义错配带来的震荡。
这种“有选择性的自由”让网络既能享受到超连接的表达力,又保持了训练的稳定性,堪称优雅的平衡。
🧶 给爷爷奶奶的毛衣版解释
如果上面还是有点绕,我们用织毛衣来打个最接地气的比方:
- 传统深度网络:一根线慢慢织,效率低,还容易断。
- 残差连接:加了一根备用线,断了也能接上,继续织得更深。
- 超连接(HC):一次用好多股线一起织,速度飞快,花样也更丰富。
- 流形约束超连接(mHC):在多股线织的时候,加了一个智能理线器,防止线互相缠结打结。这样织出来的毛衣不仅快,还更结实、更美观、不容易散。
这就是mHC的全部奥秘。
🌟 写在最后:一条自然演化的技术脉络
从深度网络的信息衰减难题出发,到残差连接的捷径,再到超连接的多元通道,最后用流形理论施加智慧约束——Deep Neural Network → Residuals → HC → mHC,这条路线走得如此顺畅,仿佛历史必然。
值得骄傲的是,残差连接(ResNet)、超连接(DeepSeek团队)、流形约束超连接,都出自中国研究者之手。它们不仅推动了模型深度与表达能力的边界,也展现了中国学者在基础架构创新上的敏锐洞察。
目前mHC仍停留在论文阶段,期待后续开源模型的验证。但这条脉络已经足够清晰:人工智能的未来,不在于单纯堆砌参数,而在于设计更聪明、更符合数据内在几何的信息流动方式。
至此,你学会了吗?如果学会了,不妨和身边的爷爷奶奶分享那个“织毛衣”的版本——他们一定听得懂,也会为你感到骄傲。
参考文献
- He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]//CVPR 2016. (残差连接开创性工作)
- DeepSeek Team. DeepSeek-V2 Technical Report[EB/OL]. 2024. (提出Hyper-Connections与mHC的核心论文)
- Bengio Y, LeCun Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444. (深度学习综述)
- Bronstein M M, Bruna J, LeCun Y, et al. Geometric deep learning: going beyond Euclidean data[J]. IEEE Signal Processing Magazine, 2017, 34(4): 18-42. (几何深度学习与流形相关基础)
- Lee J M. Introduction to Smooth Manifolds[M]. Springer, 2012. (流形数学经典教材,提供严格定义)
讨论回复
加载中...正在加载回复...
推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。