“The agentic future will be built one context at a time. Engineer them well.”
想象一下,你正站在一座宏伟却隐形的城堡前——这座城堡不是用石头堆砌,而是由无数文字、指令、记忆与决策编织而成。它就是未来的智能代理(AI Agent)。而建造它的最关键工具,不是昂贵的训练数据,也不是海量的计算资源,而是看似平凡却蕴藏无限潜力的“上下文”(Context)。Manus 团队用亲身实践告诉我们:当我们试图让大语言模型从聊天机器人进化成真正能独立完成复杂任务的“代理”时,传统的微调(Fine-tuning)之路已然崎岖,而上下文工程(Context Engineering)才是通往生产级系统的康庄大道。
🌱 为什么选择上下文工程,而非传统的微调?
在构建通用智能代理的十字路口,开发者通常会面对两条截然不同的路径。一条是经典的 Fine-tuning:从头到尾训练一个端到端模型,听起来很诱人,但现实却残酷——反馈循环以周为单位,模型一旦被新一代基座升级,就可能全盘作废,之前的努力瞬间化为乌有。另一条则是 In-Context Learning:直接依托前沿大语言模型的能力,通过精心设计输入的上下文来引导行为。
Manus 团队果断选择了后者。他们把代理开发的核心总结为一个新词:Context Engineering——如何构建、管理、优化输入给模型的上下文。这个过程充满了试错、Prompt 调整和架构迭代,作者幽默地称之为“Stochastic Graduate Descent”(随机研究生下降法),既致敬了梯度下降,又调侃了无数个深夜改 Prompt 的研究生时光。
这里的“Stochastic”指随机性,因为上下文工程高度依赖人工尝试与直觉;“Graduate”则暗指这是一门需要长期积累的技艺,而非一蹴而就的算法。
这种选择并非心血来潮,而是因为代理任务的本质决定了上下文才是真正的生命线:代理需要处理长周期、多步骤、充满不确定性的真实世界任务,而这些任务的成败,往往取决于模型能否在海量上下文里精准回忆、推理并行动。
🔑 KV-Cache:代理系统的隐形生命线
代理任务有一个显著特征:输入上下文极长(往往数十万 token),而输出动作却很短(几百 token),比例可达 100:1。在这种极端不对称下,推理成本和首 token 延迟(TTFT)几乎完全由 KV-Cache 的命中率决定。
公式清晰地说明了这一点:
也就是说,只有当缓存命中率接近 100% 时,我们才能把巨额成本压下来。
Manus 团队因此把整个系统架构向 KV-Cache 妥协,提出三项关键实践:
-
前缀稳定(Prefix Stability):Transformer 是自回归的,一旦早期 token 改变,后续所有 KV Cache 都会失效。最常见的反模式是在 System Prompt 开头放精确到秒的时间戳——每次调用都不同,导致缓存全 miss。正确做法是把动态信息(如当前时间)挪到上下文末尾,保持头部完全静态。
-
仅追加式上下文(Append-only Context):坚决不修改历史动作或观察。哪怕历史里有错误,也绝不删改。这样可以保证序列化的确定性,连 JSON 键的顺序都要固定,防止微小差异导致缓存失效。
-
显式缓存断点:在某些不支持自动增量缓存的推理框架中,手动插入特殊标记,强制刷新缓存,避免隐形 bug。
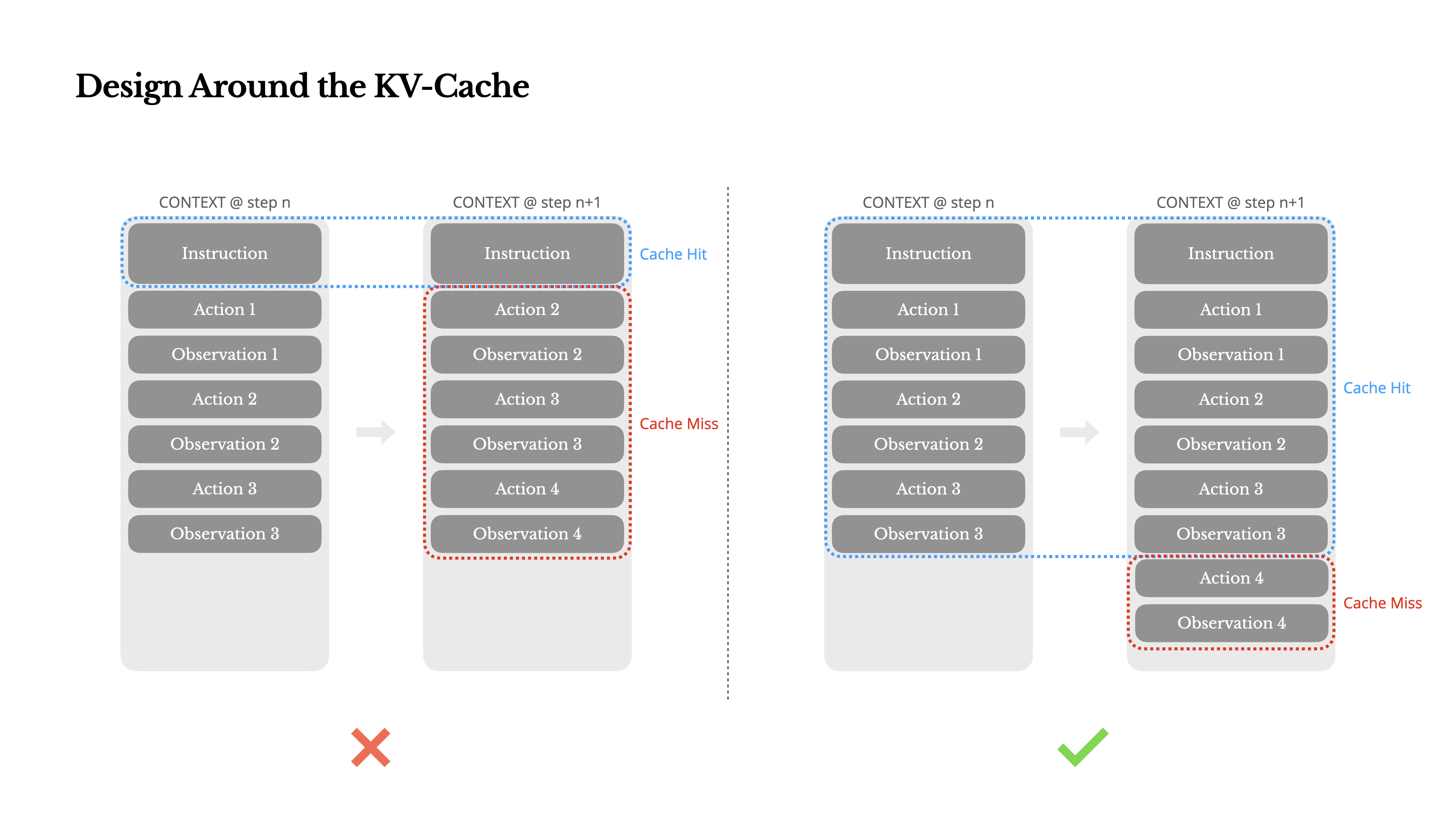
这些看似琐碎的细节,却决定了系统能否从 Demo 级的几美元一次,降到生产级别的几分钱一次。
🛠 用 Logits Mask 驯服工具爆炸
随着代理能力扩展,可用工具数量迅速膨胀:浏览器、代码执行器、文件读写、数据库查询……如果把所有工具定义都塞进上下文,不仅占用宝贵空间,还会互相干扰。更糟糕的是,如果采用 RAG 式动态加载/卸载工具,历史调用记录会指向一个突然“消失”的工具定义,模型会彻底困惑。
Manus 的解决方案优雅而高效:不在 Prompt 里删添工具,而是在解码阶段直接对 Logits 进行掩码(Logit Masking,也称 Constrained Decoding)。
他们用一个有限状态机跟踪当前允许的工具集,在生成每个 token 时,把不允许工具的概率直接置为 −∞:
实现细节包括:
- 用特殊 token(如 im_start)进行响应预填充(Prefill),快速进入工具调用模式。
- 工具命名规范化(如全部以 browser_、shell_ 开头),便于前缀掩码。
- 支持三种调用模式:Auto(模型自由选择)、Required(必须调用工具)、Specified(只允许指定子集)。
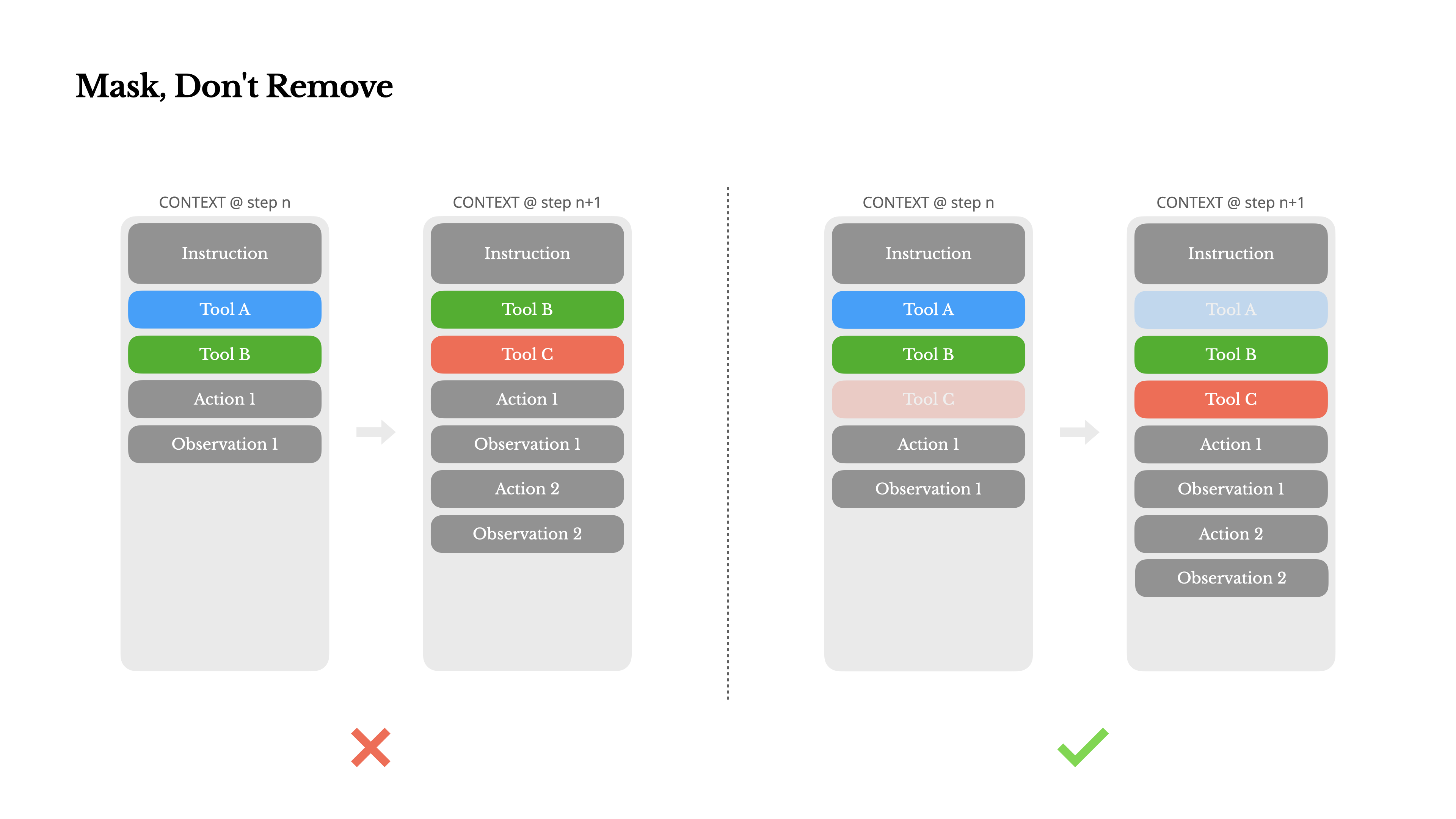
这种推理时干预比提示词工程更可靠,也更省上下文——它把复杂控制逻辑从昂贵的上下文转移到了几乎免费的解码阶段。
💾 文件系统:代理的无限外置显存
即使上下文窗口已达 128k 甚至百万级别,真实世界的观察数据(完整网页、长 PDF、代码仓库)仍然动辄超限。而且直接塞进去不仅贵,还会触发经典的“Lost-in-the-middle”现象:模型对上下文中间的信息注意力最弱。
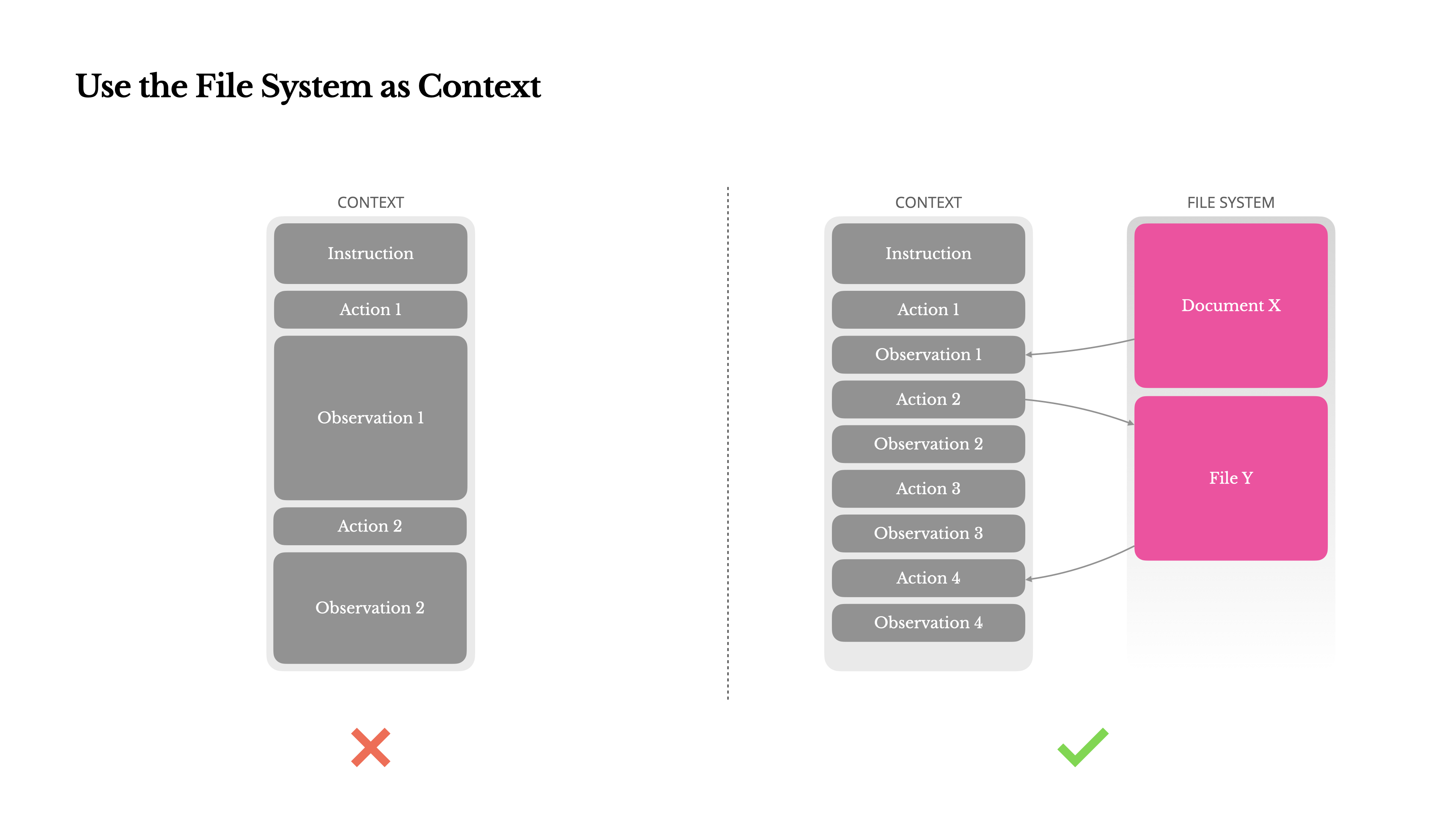
Manus 的应对思路极具启发:把文件系统当作无限容量、持久化的外部记忆。
- 上下文里不再放网页全文,只保留 URL 或文件路径。
- 模型学会调用 read_file(path) 工具,按需加载真正需要的那部分内容。
- 加载后的内容可选择性压缩摘要后追加进上下文,保持信噪比。
作者进一步畅想:这种“上下文 + 外部存储 + 按需加载”的组合,实际上让 Transformer 模拟了经典的 Neural Turing Machine(神经图灵机)。而未来具备原生文件读写能力的 State Space Models(SSM)或许会成为更自然的代理架构。
📜 用背诵对抗注意力衰减
在超过 50 步的长任务中,模型最容易遗忘最初的用户目标。这不是模型笨,而是注意力机制的固有属性:
最近的键值对(K、V)天然获得更高权重(Recency Bias)。
Manus 的巧妙对策是让代理维护一个 todo.md 文件,每一步结束后更新并在上下文末尾完整背诵当前进度与剩余目标。这种“Recitation”(背诵)强行把全局计划拉到注意力最强的位置,相当于给模型装了一个永不遗忘的“便签”。
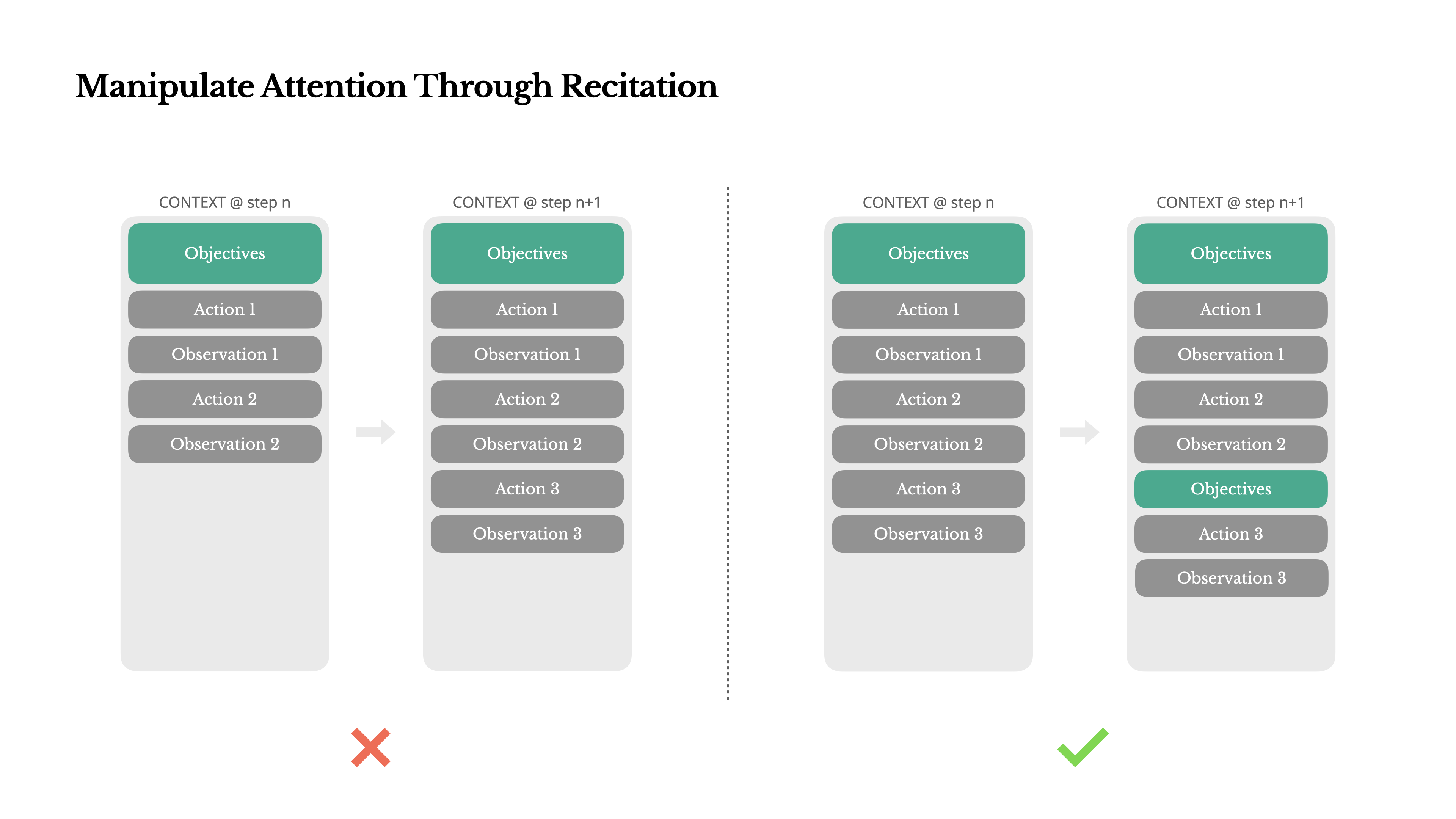
想象一下,你在做一道复杂数学题,每做一步就把最终目标重新抄一遍——这听起来多余,却能极大降低走偏的概率。代理也一样。
🔄 保留错误轨迹:让失败成为老师
大多数人本能会隐藏错误:一旦代理出错,就清空上下文、重新开始,追求“干净”的历史。但 Manus 反其道而行之:坚决保留错误的 Action 和完整的错误 Observation。
原因深刻:错误轨迹本身就是极宝贵的负样本。当模型反复看到“Action A → Error X”,它会自然降低再次选择 A 的概率。这种从错误中恢复的能力,正是代理智能的核心体现。抹掉错误等于抹掉学习机会。

这让我想起人类学习开车:如果你每次失误后都假装没发生过,你永远学不会避开那个坑。
🎲 避免少样本陷阱:注入结构化噪声
大语言模型是天生的模仿者。如果上下文里充满了高度相似的“动作-观察”对(比如批量处理 20 份简历),模型很容易陷入模式重复:要么死循环,要么产生幻觉,要么机械复制前几步的动作。
对策是主动引入结构化噪声:
- 序列化模板稍作随机变化(不同措辞、不同字段顺序)。
- 观察摘要的表达方式多样化。
- 甚至在工具调用格式上微调。
这些小扰动打破了上下文的单一模式,强迫模型每次都真正推理,而不是懒惰地“补全”。
🌓 从 Demo 到 Production:上下文工程的哲学
回望 Manus 团队的整套实践,我们可以看到一条清晰的主线:代理系统从炫技 Demo 走向可靠 Production,核心挑战在于——如何在有限的上下文窗口、昂贵的推理成本下,维持长期规划能力与系统稳定性。
他们的答案可以浓缩为四句箴言:
- KV-Cache 是生命线,一切设计必须向缓存机制妥协。
- 推理阶段的干预(Logit Masking)比提示词工程更可靠、更省 token。
- 上下文并非越大越好,学会用外部存储与动态加载保持高信噪比。
- 真正的鲁棒性来自拥抱错误、从失败中学习,而非追求一次完美的规划。
这些洞察不仅适用于构建类似 Manus 的通用代理,也为所有从事 RAG、长上下文推理、工具调用优化的开发者提供了宝贵参考。未来的代理时代,不会是某个超级模型一统江湖,而是无数工程师一砖一瓦、一次上下文优化叠加而成。
正如文章结尾那句箴言:“The agentic future will be built one context at a time. Engineer them well.”
我们每个人,都可以成为那名炼金术士。
参考文献
- Manus Team. Context Engineering for AI Agents: Lessons from Building Manus. https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
- Liu, J. et al. Lost in the Middle: How Language Models Use Long Contexts. arXiv preprint arXiv:2307.03172.
- Vaswani, A. et al. Attention Is All You Need. Advances in Neural Information Processing Systems 30 (2017).
- Gu, A. et al. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint arXiv:2312.00752.
- OpenAI. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
讨论回复
加载中...正在加载回复...
推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。