想象一下,你是一位年轻的炼金术士,站在一座尘封已久的地下图书馆前。门上刻着一行金色箴言:“若你真正读懂这三十卷古籍,便掌握了人工智能九成精髓。”这是Ilya Sutskever——那位曾执掌OpenAI科学王冠的智者——亲口对约翰·卡马克许下的预言。多少人望而却步,因为那些卷轴里布满晦涩的数学符咒与抽象的逻辑迷宫。可如今,有人把这些古籍一页页拆解,用最原始的元素——纯NumPy——重新铸造成可运行的活体法器。它们躺在GitHub的一个角落,名为sutskever-30-implementations,静静等待下一个敢于点亮火炬的冒险者。
这个仓库不是简单的代码复制,而是一场从零开始的朝圣。每一份实现都拒绝借助PyTorch或TensorFlow的“魔法杖”,只用NumPy这把最朴素的匕首,一刀一刀刻出神经网络的骨骼。合成数据随时生成,Jupyter Notebook像互动剧本一样引导你一步步推演,甚至连梯度都亲手写出来验证。你不必安装庞大框架,只需几行pip,就能立刻让RNN在字符海洋里吟诗,让Transformer在注意力风暴中起舞。这不是调用API的速成术,而是真正把“为什么能工作”刻进肌肉记忆的苦修。
让我们一起翻开这本魔典,沿着三十卷古籍的脉络,走进人工智能从混沌到星辰的史诗。
🔮 第一定律:复杂性如何从简单规则中野蛮生长
故事从一篇看似哲学的论文开始——《复杂动力学的第一定律》。它像一粒种子,埋在元胞自动机里,却能长出无限复杂的森林。作者用熵与复杂度的增长,解释为什么简单规则能演化出不可预测的图案。想象你在一张格纸上涂黑白方块,每一格只根据邻居决定生死,却能涌现出滑翔机、飞船甚至自我复制的生命。这正是人工智能的原初火花:秩序与混沌的永恒舞蹈。
元胞自动机就像一个巨大的蚁群,每只蚂蚁只遵循“如果左边有三只同伴就往前走”的笨规则,却能集体筑起宏伟巢穴。论文告诉我们,复杂性不是设计出来的,而是不可避免地从简单交互中爆发。
🌊 字符的狂想曲:RNN为何如此不讲道理地有效
接下来,Andrej Karpathy那篇著名的博客《循环神经网络的不合理有效性》把我们拉进文本的海洋。一个简单的RNN就能逐字符预测下一个字母,最终吐出一段段莎士比亚风格的戏剧。纯NumPy实现里,你会看到梯度如何在时间轴上回传,看到vanishing gradient像海浪一样把信号吞没。这份代码像一台老式打字机,咔嗒咔嗒敲出范·多姆的动作片台词,又突然转入特朗普的竞选演讲——荒诞,却又惊人地连贯。
🧠 LSTM的记忆宫殿:大门、遗忘门与输出门的芭蕾
理解LSTM的那篇Colah博客被奉为圣经。仓库用几百行NumPy重现了遗忘门、输入门、输出门的精妙配合。想象你的记忆像一座古老城堡,普通RNN的门永远敞开,旧信息不断被新洪水冲走;LSTM却装上了三道智能闸门:该忘的坚决遗忘,该记的牢牢锁住,该说的才优雅输出。代码里你能亲手调节这些闸门,看长期依赖如何像丝线一样穿过数百个时间步。
🔥 正则化的炼金术:让RNN不再过拟合的疯狂
变分dropout、权重惩罚、路径规范化……这些技巧听起来枯燥,但在纯NumPy里你会发现它们像调音师的手指,轻触琴弦就让整个序列模型从嘶哑变得圆润。代码让你对比有无正则化的训练曲线,那差距如同业余乐手与大师的演奏。
✂️ 极简主义宣言:剪枝与最小描述长度
《保持神经网络简单》用最小描述长度原理(MDL)论证:最好的模型是能用最短代码描述数据的模型。实现里你会看到如何从稠密网络中无情剪去冗余权重,却不损失性能。这就像米开朗基罗雕刻大卫——移除的越多,剩下的越神圣。
⚔️ 指针网络的剑术:注意力化作精准打击
Pointer Networks把注意力机制变成一把指向输出位置的“指针”。在排序、凸包、TSP旅行商问题上,它直接输出“第几个输入”的索引,而不是软概率分布。代码里你会看到它如何优雅解决组合优化难题,仿佛一位剑客不再挥舞大剑,而是用指尖轻点敌人要害。
🖼️ AlexNet的视觉革命:卷积第一次征服ImageNet
2012年的AlexNet像一颗炸弹,彻底终结了手工特征时代。仓库用NumPy从头搭建八层网络,重现ReLU、Dropout、数据增强的魔力。你会看到卷积核如何像探照灯扫过图像,提取边缘、纹理,最终认出猫、狗、飞机。那一刻,你会明白为什么GPU突然变得比黄金还贵。
🔀 顺序无关的序列到序列:集合的编码艺术
《Order Matters》探讨如何让seq2seq模型处理集合而非序列。普通模型对输入顺序敏感,像强迫症患者;这篇论文教它学会“无论你怎么洗牌,我都能认出这是同一副牌”。实现里你会用简单的插入排序任务,感受置换不变性的美妙。
🛠️ GPipe的流水线魔法:让巨型模型也能训练
GPipe把模型切成微批次,在多设备间流水线并行。纯NumPy版本虽无法真正并行,却清晰展示微批次如何减少内存占用,让百亿参数模型不再是遥不可及的梦想。
🛤️ 残差高速:ResNet为何能堆到一千层
《深度残差学习》引入skip connection,像在深井里铺设梯子,让梯度直达底部。代码里你会看到普通网络到50层就梯度消失,而ResNet轻松突破百层,误差反而下降。这就是信息高速:主干道堵塞时,旁路立刻分流。
🌅 膨胀卷积的视野:不牺牲分辨率看更远
Dilated Convolution像给卷积核装上望远镜,感受野指数级扩张,却不增加参数。仓库实现让你在语义分割任务上对比:普通卷积像近视眼,膨胀卷积一眼望穿全局。
🔗 图神经网络的消息传递:社交网络的智慧
《神经消息传递》奠定GNN基础。每轮迭代,节点向邻居发送消息、聚合、更新自身状态。代码里你会用合成图数据,看着节点如何通过几轮“八卦传播”就学会分类、链接预测,仿佛整个图在集体思考。
⚡ 注意力就是一切:Transformer的星辰大海
《Attention Is All You Need》无需循环或卷积,只用注意力机制平行处理序列。纯NumPy实现让你从scaled dot-product开始,一步步搭建多头自注意力、位置编码、编码器-解码器堆栈。那一刻你会明白:RNN像骑自行车,Transformer直接开上了高速公路。
🔄 Bahdanau注意力的诞生:翻译机的第一次对齐
2014年的神经机器翻译首次引入加性注意力,让解码器动态“瞄准”编码器不同位置。代码对比Luong注意力,你会发现它们就像两位狙击手:一个先计算所有分数再瞄准,一个边瞄边算。
🆔 身份映射的极简美学:ResNet的进化版
《身份映射在深度残差网络中》把激活函数移到skip connection前,进一步净化梯度流。实现里你会看到pre-activation ResNet训练更稳定,就像给信息高速加装了净化器。
🤝 关系推理的网络:看见物体间的隐秘联系
Relation Networks用成对关系函数取代全局池化,让模型真正“理解”物体如何互动。代码在排序视觉问答任务上大放异彩:不是死记硬背像素,而是推理“左边的大球压住了小球”。
🌌 变分自编码器的梦境:潜空间里的漫游
《变分损失自编码器》用ELBO和重参数化技巧,让VAE生成梦幻般的图像。纯NumPy版本让你亲手采样潜变量,看着模糊的脸逐渐清晰,仿佛在操控一个平行宇宙的画师。
🧩 关系循环网络的超级记忆:手动反向传播的史诗
第18篇Relational RNN是最硬核的实现——约1100行手动梯度计算。关系记忆模块让RNN拥有外部记忆矩阵,能在bAbI推理任务上碾压普通LSTM。仓库提供了大量可视化:
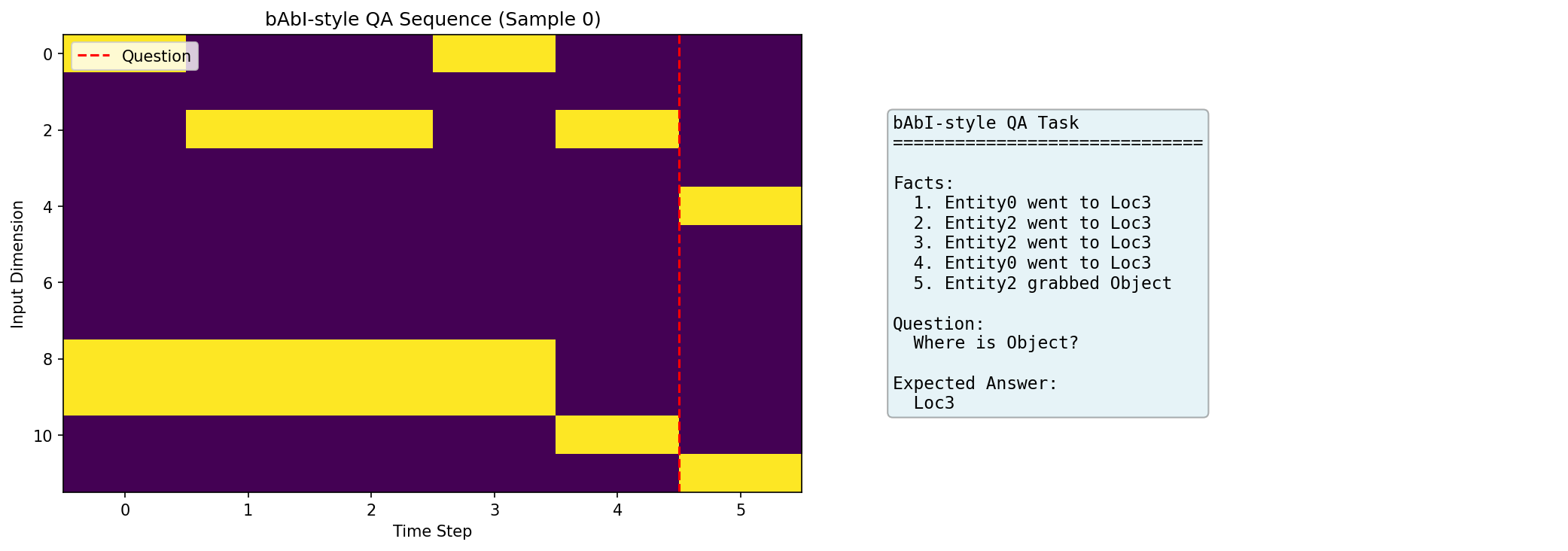
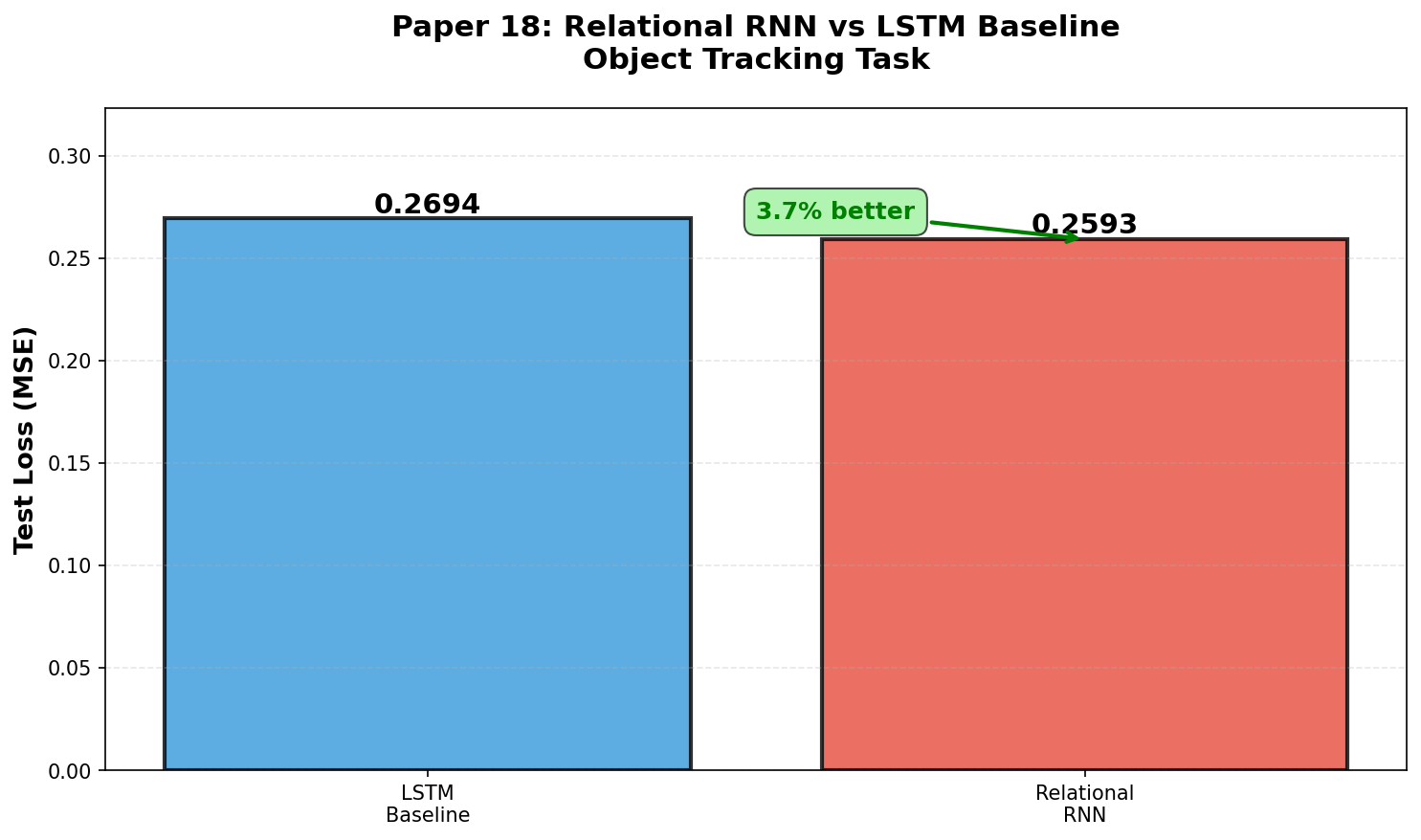
这些曲线像战场报告:普通LSTM在复杂推理任务上迅速崩盘,而关系记忆像开了外挂,稳稳通关20个bAbI任务。
☕ 咖啡自动机:不可逆性的热力学诗篇
一篇关于不可逆性、熵增与朗道尔原理的哲学论文,用咖啡杯里的漩涡解释为什么计算需要能量。这提醒我们:人工智能的每一次前向传播,都在与宇宙的箭头赛跑。
🧮 神经图灵机:可微分的外部记忆
Neural Turing Machine给神经网络装上读写头和记忆带,试图逼近图灵完备。纯NumPy实现让你看到寻址机制如何在连续空间模拟离散操作,像是把纸带机塞进了连续的梦境。
🎤 Deep Speech 2的CTC魔法:端到端的语音识别
Connectionist Temporal Classification损失让模型直接从音频预测文本序列,无需强制对齐。代码里你会用合成语音数据,看着CTC如何巧妙处理“同一个音节可能重复或缺失”的现实。
📈 尺度定律的预言:更大就是更好?
《尺度定律》用幂律关系预测:算力、数据、参数三者如何最优分配。仓库实现让你拟合Chinchilla定律曲线,提前预言Llama-70B为何能媲美更大的模型。
📏 最小描述长度:压缩即是理解
MDL原理再次登场:最佳模型是最短程序+数据压缩长度之和。这不仅是正则化理论,也是奥卡姆剃刀的数学版。
🧑🔬 机器超级智能:AIXI的终极梦想
《机器超级智能》博士论文描绘了AIXI——理论上最聪明的通用人工智能,基于所罗门诺夫归纳。纯NumPy版本虽无法真正运行AIXI,却让你感受算法概率与科尔莫戈洛夫复杂度的深邃。
🎲 科尔莫戈洛夫复杂度:不可压缩的随机性
最短程序长度定义了字符串的“内在复杂性”。代码里你会看到为什么π的前一亿位看似随机,却有极短描述,而真正的随机序列无法压缩。
📸 CS231n的视觉圣经:从kNN到反向传播
斯坦福CS231n课程笔记被浓缩成一份notebook,从最近邻到完整CNN+反向传播手推公式(虽然没写公式,但逻辑清晰)。这是许多人的启蒙之路。
🔮 多标记预测:样本效率的新希望
近期论文提出同时预测多个未来token,提升样本效率并支持推测解码。实现让你看到它如何像并行思考,加速自回归生成。
📚 稠密段落检索:RAG的双塔架构
Dense Passage Retrieval用双编码器把查询和文档映射到同一潜空间,用内批负样本来训练。代码清晰展示为何DPR成为现代检索基石。
🧩 检索增强生成:让语言模型不再孤单
RAG把外部知识库接入生成过程,有Sequence和Token两种范式。仓库实现让你对比纯生成 vs 检索增强在长尾知识上的巨大差距。
🕳️ 中间丢失之谜:长上下文为何最难记住中间
《Lost in the Middle》揭示Transformer在长序列中开头结尾表现好,中间位置性能急剧下降。代码实验让你直观感受位置偏置的残酷现实。
✨ 尾声:三十卷古籍的完整闭环
当你合上最后一个notebook,会发现自己已经走过人工智能从RNN到Transformer、从像素到推理、从压缩到通用智能的全景图景。每一份纯NumPy实现都像一面放大镜,把原本晦涩的论文照得纤毫毕现。你不再只是API调用者,而是真正懂得“为什么能工作”的筑梦者。
这个仓库不仅是代码,更是一场关于深度理解的宣言。它告诉我们:真正的掌握,不在于记住多少公式,而在于能否用最朴素的工具,从零重现魔法的全过程。
参考文献
- pageman/sutskever-30-implementations GitHub仓库:完整30篇论文纯NumPy实现,2024-2025。
- Aman.ai - Ilya Sutskever's Top 30 Papers Primer:原始推荐列表与解读。
- GitHub - dzyim/ilya-sutskever-recommended-reading:Ilya阅读清单的早期收集版本。
- Relational RNNs原文及bAbI任务基准:Facebook AI Research, 2018。
- Attention Is All You Need:Vaswani et al., Google, 2017(Transformer奠基作)。
讨论回复
1 条回复推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。