1. 引言:长文本的“皇帝新衣”——百万上下文窗口的幻觉
1.1 现象:GPT-4在财报分析中的“复读机”表现
随着大型语言模型(LLM)技术的飞速发展,各大厂商纷纷推出拥有百万级上下文窗口的模型,宣称能够处理和理解前所未有的海量信息。然而,在实际应用中,这些看似强大的模型却常常表现出令人失望的“痴呆”状态。一个典型的场景是财报分析:当用户将一份长达数百页的财务报告输入给GPT-4等顶级模型时,它们往往只能进行简单的信息复述,例如提取一些关键数字或总结部分章节。一旦涉及到需要跨章节、跨年度进行复杂推理和关联分析的任务,比如“对比分析过去三年中,公司在不同市场区域的营收增长与研发投入之间的关系,并预测下一季度的潜在风险”,模型的表现便会急剧下降,变得逻辑混乱、前后矛盾,甚至完全无法回答。这种现象揭示了当前长上下文技术的一个核心痛点:模型虽然能够“看到”更多信息,但却无法“理解”和“运用”这些信息进行深度思考。它们仿佛一个拥有巨大视野但缺乏分析能力的“复读机”,只能机械地重复输入文本中的表面信息,而无法进行真正的智能分析。
1.2 问题核心:长窗口不等于强推理能力
这种“复读机”现象的背后,隐藏着一个被业界称为“上下文腐烂”(Context Rot)的深层问题 。它指的是,尽管模型的上下文窗口(Context Window)不断扩大,能够容纳的token数量越来越多,但其处理长文本时的推理能力却并未同步提升,甚至在某些情况下会显著下降。麻省理工学院(MIT)的研究人员通过系统性测试发现,当输入文本的长度和任务复杂度同时增加时,即使是像GPT-5这样的前沿模型,其性能也会出现断崖式下跌 。这表明,单纯增加上下文窗口的大小,并不能从根本上解决模型在长文本推理上的“痴呆”问题。问题的根源在于,Transformer架构在处理超长序列时,其内部的注意力机制会面临信息稀释、位置编码失效等根本性挑战,导致模型难以在长文本中维持连贯的逻辑和精确的推理。因此,长上下文窗口在某种程度上更像是一种“营销噱头”,它解决了“能装下”的问题,却没有解决“能思考”的问题。真正的挑战不在于让模型看到多少信息,而在于如何让模型像人类专家一样,能够高效地从海量信息中筛选、组织并进行深度推理。
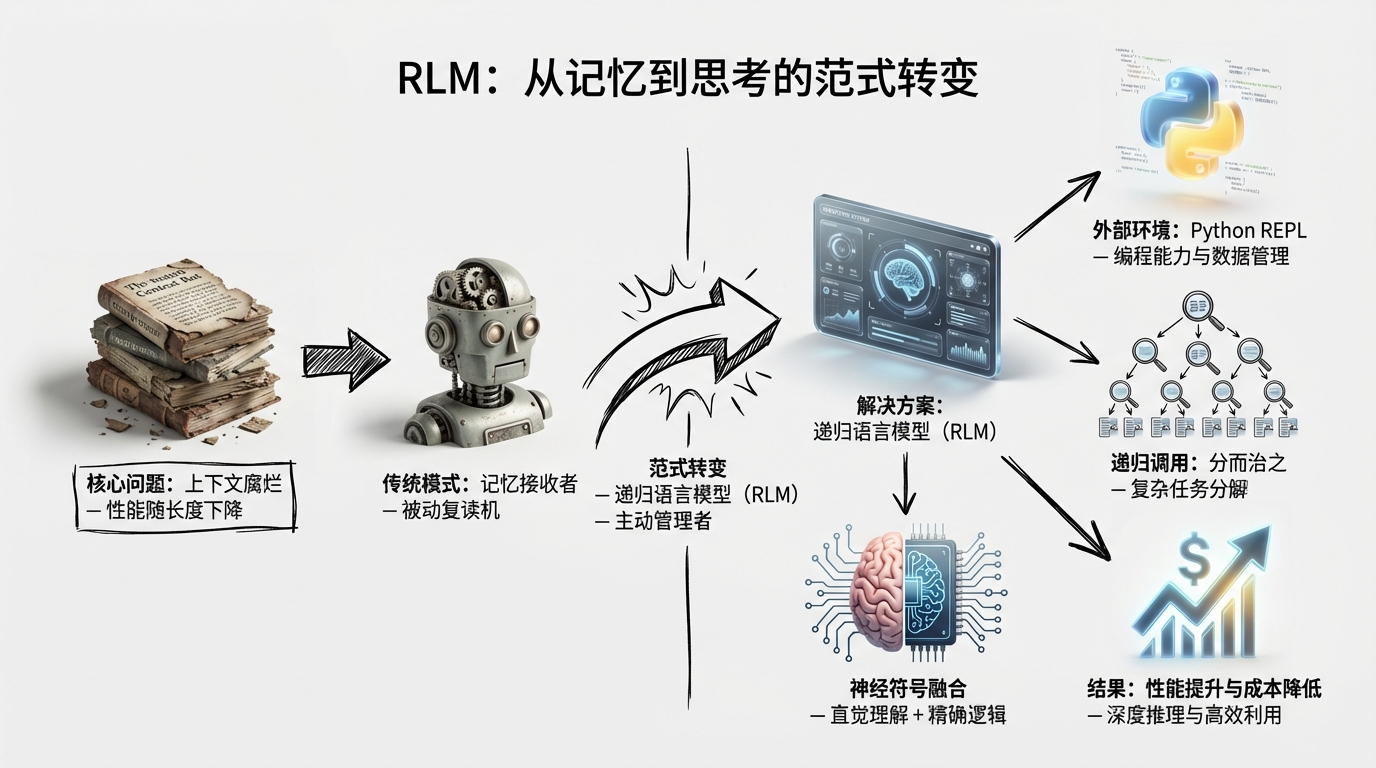
1.3 MIT CSAIL的颠覆性研究:递归语言模型(RLM)的提出
面对“上下文腐烂”这一难题,麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)的研究团队提出了一种颠覆性的解决方案——递归语言模型(Recursive Language Models, RLM)。这项研究的核心思想是,与其让模型像一个被动的“记忆者”一样试图一次性吞下并记住所有信息,不如让它转变为一个主动的“管理者”,像操作系统管理内存一样,将复杂的任务“外包”出去。RLM通过引入一个外部的编程环境(如Python REPL),赋予模型编写和执行代码的能力,使其能够主动地、递归地分解和处理长文本 。在这种新范式下,长文本不再被直接塞进模型的上下文窗口,而是被存储在外部环境中,作为一个巨大的数据变量。模型通过编写代码来“窥探”、“切分”、“搜索”和“过滤”这些数据,并将具体的子任务(如分析某个段落、总结某个章节)递归地调用其他更小、更便宜的子模型(Sub-LMs)来完成。这种“分而治之”的策略,不仅从根本上绕开了Transformer架构的上下文窗口限制,更重要的是,它将长文本处理从一个纯粹的“记忆”问题,转变为一个更具可扩展性的“程序综合”问题,从而为解决AI的“痴呆”难题开辟了全新的道路。
2. 核心问题:“上下文腐烂”(Context Rot)——Transformer的致命弱点
2.1 什么是“上下文腐烂”?
2.1.1 定义:模型性能随输入长度增加而显著下降
“上下文腐烂”(Context Rot)是MIT研究团队在论文中提出的一个核心概念,它精准地描述了当前大型语言模型在处理长文本时所面临的根本性困境 。具体而言,它指的是模型的性能(尤其是在需要深度推理的任务上)会随着输入上下文长度的增加而呈现出显著的、甚至是断崖式的下降。这种现象并非简单的“遗忘”,而是模型在处理海量信息时,其内部推理机制的系统性失效。即使模型的上下文窗口理论上足够容纳整个文档,但当文档长度超过某个阈值后,模型就开始“迷失方向”,无法有效地整合和利用上下文中的信息。例如,在“大海捞针”(Needle in a Haystack)这类任务中,模型可能还能勉强找到关键信息,但在需要进行多步推理、信息聚合或跨文档关联分析时,其表现就会急剧恶化。这种性能退化是普遍存在的,并且随着任务复杂度的增加而愈发明显,揭示了当前LLM架构在处理长依赖关系时的内在局限性 。
2.1.2 表现:即使窗口足够,推理能力也会“痴呆”
“上下文腐烂”最直观的表现就是模型推理能力的“痴呆化”。当面对一个长文档时,即使其长度完全在模型的上下文窗口之内,模型也常常表现出以下几种“痴呆”症状:首先,信息提取错误,模型可能会张冠李戴,将不同段落的信息混淆,或者完全忽略掉关键细节。其次,逻辑推理断裂,在进行多步推理时,模型可能会丢失前提条件,导致后续推理步骤出现逻辑错误。例如,在分析财报时,它可能记住了第一季度的营收数据,但在分析全年趋势时却忘记了这一数据。再次,无法进行全局性分析,模型倾向于对局部信息进行孤立的理解,而无法将这些局部信息整合成一个全局性的、有洞察力的结论。例如,它可能分别总结了每个章节的要点,但却无法将这些要点串联起来,形成对整个文档核心论点的深刻理解。这种“痴呆”状态表明,仅仅扩大上下文窗口,并不能赋予模型真正的长文本理解和推理能力,反而可能因为其内部的注意力机制被大量无关信息稀释,导致其“思考”能力下降 。
2.2 为什么Transformer架构会“腐烂”?
2.2.1 注意力稀释:长序列中的信息丢失
Transformer架构的核心是自注意力机制(Self-Attention),它允许模型在处理每个token时,都能够“关注”到输入序列中的所有其他token。然而,这种机制在处理超长序列时会遇到一个致命问题——注意力稀释(Attention Dilution) 。当输入序列的长度达到数十万甚至上百万个token时,模型在计算每个token的注意力权重时,需要与序列中的所有其他token进行比较。这导致每个token的注意力权重被分散到海量的其他token上,使得真正重要的信息信号被淹没在噪声之中。想象一下,在一个拥挤的体育场里,如果你想听清某个人的声音,周围所有人的声音都会成为干扰。同样,在超长序列中,模型很难精确地定位到与当前任务最相关的几个关键token,其注意力权重会变得非常平滑和均匀,从而失去了对关键信息的聚焦能力。这种信息丢失是导致模型在长文本推理中“痴呆”的根本原因之一,因为它使得模型无法有效地建立起长距离的依赖关系。
2.2.2 位置编码限制:无法有效处理超长序列
除了注意力稀释,Transformer架构中的位置编码(Positional Encoding)机制在处理超长序列时也面临挑战。位置编码的作用是为模型提供每个token在序列中的位置信息,因为自注意力机制本身并不具备顺序感知能力。然而,大多数位置编码方案(如绝对位置编码或相对位置编码)在设计时都有一个固定的最大长度限制。当输入序列的长度超过这个限制时,模型就无法为新的token生成有效的位置编码,或者生成的位置编码会变得非常混乱,导致模型无法正确理解token之间的顺序关系。即使一些模型采用了能够处理任意长度的位置编码方案(如RoPE),但在实践中,随着序列长度的增加,位置编码的精度和区分度也会下降,使得模型难以区分相距甚远但内容相似的token。这种位置信息的丢失,进一步加剧了模型在长文本推理中的困难,因为它破坏了文本的内在结构和逻辑顺序。
2.2.3 “相变”(Phase Transition):从简单记忆到复杂推理的崩塌
MIT的研究人员通过实验观察到一个更为深刻的现象,他们称之为 “相变”(Phase Transition) 。这指的是,模型的性能退化并非一个线性的过程,而是在输入长度和任务复杂度达到某个临界点时,会发生一个突然的、剧烈的性能崩塌。在输入较短、任务较简单时(如单点信息检索),模型可能表现得还不错,其性能接近于一个“记忆者”。然而,一旦任务需要更复杂的推理,例如需要对多个信息点进行比较、聚合或排序时,模型的性能就会突然从一个较高的水平跌落到近乎随机的水平。这种“相变”现象揭示了当前LLM架构在处理复杂推理任务时的脆弱性。它表明,模型从“简单记忆”模式切换到“复杂推理”模式的能力是有限的,并且这种切换的阈值会随着输入长度的增加而急剧降低。这解释了为什么在处理财报等需要复杂分析的任务时,模型会突然从“复读机”变成“痴呆”,因为它已经无法维持进行复杂推理所需的内部状态了。
3. 颠覆性解决方案:递归语言模型(RLM)——从“记忆者”到“管理者”
3.1 RLM的核心思想:像操作系统一样“外包”任务
3.1.1 比喻:聪明的记者如何管理海量资料
为了更好地理解递归语言模型(RLM)的核心思想,我们可以将其比作一个聪明的记者在处理海量资料时的行为。假设一位记者需要撰写一篇关于全球气候变化对农业影响的深度报道,他手头有成千上万份来自不同国家、不同年份的科研报告、政府文件和新闻稿。一个“笨拙”的记者可能会试图一次性阅读所有资料,然后凭记忆开始写作,这几乎注定会导致信息混乱和逻辑不清。而一个“聪明”的记者则会采取一种完全不同的策略:他会首先建立一个资料库(类似于RLM的Python REPL环境),将所有资料分门别类地存放好。然后,他会根据写作大纲,先通过目录、索引或关键词搜索(类似于RLM编写代码进行筛选)快速定位到与某个子主题(如“非洲干旱对玉米产量的影响”)相关的几份关键报告。接着,他可能会将这些关键报告交给助手(类似于RLM调用子模型)进行精读和摘要。最后,他将所有助手的摘要进行整合、分析和提炼,形成自己独到的见解和结论。RLM正是借鉴了这种 “分而治之” 的智慧,将LLM从一个试图记住一切的“笨拙记者”,转变为一个善于管理和调度资源的“聪明记者”。
3.1.2 核心理念:将长文本视为外部环境
RLM的核心理念在于,它彻底改变了LLM与上下文之间的关系。在传统的范式中,上下文是模型的“食物”,模型必须将其全部“吞入”自己的上下文窗口中进行消化。而在RLM的范式中,长文本被视为一个外部的、可供操作的环境(Environment),而模型则是一个在这个环境中行动的“智能体”(Agent) 。这个环境可以是一个Python REPL,也可以是一个数据库,甚至是一个文件系统。模型不再直接“看到”整个上下文,而是通过编写代码来与这个环境进行交互。例如,模型可以编写Python代码来读取一个巨大的文本文件,将其存储在一个变量中,然后使用字符串操作、正则表达式等工具来对这个变量进行筛选、切片和搜索。这种将上下文“外部化”的设计,从根本上解决了Transformer架构的上下文窗口限制问题。因为模型只需要处理通过代码交互得到的结果(通常是一个很小的片段),而不是整个上下文,所以它的上下文窗口永远不会被“撑爆”。这种范式的转变,使得模型能够处理远超其自身上下文窗口限制的海量信息,并且以一种更加结构化和可控的方式进行推理。
3.2 RLM的架构设计:Python REPL与递归调用
3.2.1 Python REPL环境:赋予模型编程能力
RLM架构的核心是一个持久化的Python REPL(Read-Eval-Print Loop)环境,它类似于一个Jupyter Notebook,为模型提供了一个强大的编程接口 。当用户向RLM提出一个查询时,整个长文本上下文并不会被直接输入给模型,而是被加载到这个REPL环境中,作为一个Python变量(例如,一个名为context的字符串)存储起来。模型的主要任务,就是与这个REPL环境进行交互。它通过生成Python代码块(通常被包裹在特定的标记中,如````repl)来向环境发送指令。这些代码可以执行各种操作,例如:
窥探(Peeking) :print(context[:1000]) 查看上下文的前1000个字符,以了解其结构。
搜索(Searching) :import re; re.findall(r'pattern', context) 使用正则表达式在整个上下文中搜索特定模式。
切分(Partitioning) :chunks = context.split('Chapter') 根据特定分隔符将上下文切分成多个块。
存储(Storing) :important_data = context[5000:10000] 将筛选出的重要片段存储在新的变量中,以便后续使用。
REPL环境执行这些代码后,会将输出结果(通常是截断的)返回给模型。通过这种方式,模型获得了一种“动手”的能力,可以像程序员一样主动地、精确地操作和分析数据,而不是被动地接收信息。
3.2.2 子模型调用机制:实现“分而治之”
除了与REPL环境交互,RLM架构的另一个关键设计是子模型调用机制,这使得“分而治之”的策略得以实现。在REPL环境中,模型不仅可以执行标准的Python代码,还可以调用一个特殊的函数,例如llm_query(prompt, sub_context),来启动一个递归的子模型调用 。这个函数的作用是将一个更小的、更具体的子任务“外包”给另一个LLM(可以是与主模型相同的模型,也可以是一个更小、更便宜的模型)来处理。例如,主模型在处理一个长文档时,可能通过代码筛选出了10个相关的段落。它可以将这10个段落逐一传递给llm_query,并附上指令“请总结每个段落的核心论点”。子模型接收到这个任务后,只需要处理一个很小的上下文,因此可以高效地完成摘要任务,并将结果返回给主模型。主模型再将这些摘要结果进行整合,形成最终的答案。这种机制使得RLM能够将一个巨大的、复杂的任务,拆解成无数个小的、易于管理的子任务,并通过递归调用的方式,将这些子任务分发给不同的模型实例并行或串行处理,从而极大地提升了处理复杂问题的能力。
3.2.3 递归处理:将复杂任务拆解为子任务
递归是RLM架构的灵魂,它使得模型能够以一种优雅的方式处理任意复杂度的任务。当一个子模型被llm_query调用时,它本身也可以作为一个RLM来运行。这意味着,如果这个子任务仍然过于复杂,子模型可以再次调用llm_query,将任务进一步拆解成更小的孙任务。这个过程可以无限递归下去,直到每个子任务都足够简单,可以被一个基础的LLM轻松解决。例如,在处理一个需要跨文档推理的任务时,主模型可能会调用一个子模型来分析文档A,而这个子模型在分析文档A的过程中,发现需要参考文档B中的某个信息,于是它又可以调用另一个子模型去专门查找文档B中的相关信息。这种递归调用的方式,形成了一个动态的、自适应的任务分解树。模型可以根据任务的实际需求,灵活地决定分解的粒度和调用的深度。这种能力使得RLM能够处理那些具有复杂依赖关系和多步推理路径的问题,而这正是传统LLM在处理长文本时最薄弱的一环。通过递归,RLM将复杂的推理过程,转化为一系列简单的、可验证的子步骤,从而保证了最终结果的准确性和可靠性。
3.3 RLM的工作流程
3.3.1 加载上下文到Python环境
RLM的工作流程始于将用户提供的海量上下文加载到一个隔离的Python REPL环境中。这个过程并非简单地将文本塞进一个变量,而是会附带一些元数据信息,例如上下文的总长度、文件类型等,这些信息会作为提示(Prompt)的一部分提供给主模型(Root LM),帮助它建立对任务规模的初步认知 。例如,系统提示(System Prompt)会告知模型:“你正在一个REPL环境中工作,上下文变量context包含了一个长度为5,000,000字符的字符串。” 这种设计让模型从一开始就明白,它不能试图一次性处理所有信息,而必须采取一种策略性的、分步的方法来探索和分析数据。这个REPL环境是持久化的,意味着在一次完整的查询过程中,模型在其中创建的所有变量和中间结果都会被保留下来,为后续的推理和整合提供了基础。
3.3.2 编写代码进行信息筛选与分解
在了解了任务概况后,主模型开始发挥其作为“管理者”的核心作用。它首先会生成Python代码,对存储在context变量中的海量数据进行初步的筛选和分解。这一步是整个工作流程中最具策略性的部分,模型的表现很大程度上取决于其“决策”的优劣。例如,在一个“大海捞针”任务中,模型可能会编写代码使用正则表达式来搜索与“针”相关的关键词,从而将搜索范围从数百万行文本缩小到几十行 。在一个需要分析特定章节的任务中,模型可能会先通过代码找到章节标题的位置,然后使用切片操作将目标章节提取出来。这种通过代码进行信息筛选的能力,是RLM区别于传统LLM的关键。它使得模型能够以一种高效、精确的方式,主动地从海量信息中提取出与当前任务最相关的部分,从而避免了在无关信息上浪费计算资源和注意力。
3.3.3 递归调用子模型处理片段
当初步筛选出的信息片段仍然过大或过于复杂,无法直接处理时,主模型就会启动递归调用机制。它会使用llm_query函数,将一个或多个信息片段作为子上下文(sub-context),并附上一个明确的指令,发送给一个子模型进行处理 。这个过程可以看作是将一个具体的“外包”任务分配给了一个“专家助手”。例如,主模型可能会将一个长达一万字的章节发送给子模型,并指令其“请用不超过200字总结这一章的核心内容”。子模型在接收到任务后,会独立地在其自己的上下文窗口内完成摘要,并将结果返回给主模型。主模型可以并行地调用多个子模型来处理不同的片段,也可以串行地调用子模型,根据前一个子模型的返回结果来决定下一步的行动。这种递归调用的方式,使得RLM能够以一种高度模块化和可扩展的方式来处理复杂的任务。
3.3.4 整合子任务结果,生成最终答案
在所有子模型都完成了各自的“外包”任务并返回了结果后,主模型就进入了最后一步:整合与生成。它会将来自不同子模型的中间结果(例如,多个段落的摘要、多个数据点的分析等)收集起来,存储在REPL环境的变量中。然后,它可能会再次编写代码来对这些中间结果进行进一步的分析和聚合,例如,将所有摘要拼接起来,或者对不同子模型的分析结果进行比较和权衡。在某些情况下,主模型可能会再次调用llm_query,将这些中间结果作为新的上下文,指令子模型进行更高层次的综合和推理。最终,当主模型认为已经收集了足够的信息来回答用户的原始查询时,它会生成最终的答案。这个答案通常会被包裹在一个特殊的标记中,如FINAL(answer)或FINAL_VAR(variable_name),以明确地指示推理过程的结束 。从用户的角度看,这只是一次普通的模型调用,但在幕后,RLM已经完成了一系列复杂的、递归的、多步骤的推理过程。
4. 性能验证:RLM在“变态”测试集OOLONG上的表现
4.1 OOLONG基准测试:专为长文本推理设计
为了验证递归语言模型(RLM)的有效性,MIT的研究团队需要一套能够真正考验模型长文本推理能力的基准测试。他们发现,现有的许多长文本基准测试(如“大海捞针”)往往只考察模型的信息检索能力,即在一个巨大的上下文中找到一个孤立的事实,这并不能完全反映模型在复杂推理任务上的表现。为此,他们采用了OOLONG基准测试,这是一个专门为评估模型在长文本上的推理和信息聚合能力而设计的“变态”测试集 。OOLONG的核心特点是,它要求模型不仅要找到信息,还要对大量的文本片段进行语义层面的分析、转换和聚合,才能得出最终答案。这种任务设计,更接近于真实世界中处理财报、法律文件或科研文献时所面临的挑战,能够更真实地反映模型在长文本推理上的“智商”。
4.1.1 OOLONG-Pairs任务:二次方复杂度的挑战
在OOLONG基准测试的基础上,MIT的研究团队进一步设计了一个更具挑战性的子任务——OOLONG-Pairs 。这个任务的复杂度达到了惊人的二次方级别(O(N²)) ,其目标是要求模型对输入数据集中的每一对条目进行推理和比较。具体来说,OOLONG-Pairs的任务定义如下:给定一个包含大量用户交互记录的数据集,模型需要找出所有满足特定条件的用户对。例如,一个典型的查询可能是:“在上述数据中,列出所有满足以下条件的用户对(不重复,ID小的在前):两个用户都至少有一个实例被标记为‘实体’或‘人类’。” 。要回答这个问题,模型不能简单地遍历一遍数据,而必须对数据集中的所有用户进行两两比较,检查每一对组合是否满足条件。这意味着,如果数据集中有N个用户,模型就需要进行大约N²/2次比较。这种二次方的计算复杂度,对于任何试图一次性处理所有信息的模型来说,都是一个巨大的挑战,因为它会导致计算量和内存需求爆炸式增长。
4.1.2 任务定义:对输入中的每一对条目进行推理
OOLONG-Pairs任务的具体实现,要求模型具备一种“双重循环”的推理能力。它首先需要理解查询的语义,识别出需要比较的两个实体(在这个例子中是“用户”)以及比较的条件(例如,都包含特定标签的实例)。然后,它必须设计一个策略,来高效地遍历所有可能的用户对。这不仅仅是简单的暴力枚举,因为输入的上下文可能非常长,包含了大量的用户和实例。一个高效的模型需要能够:
- 识别和提取:首先识别出数据集中所有的用户ID,并提取出每个用户关联的所有实例及其标签。
- 筛选和索引:根据查询条件,预先筛选出可能符合条件的用户,并建立索引,以减少后续的比较次数。
- 成对比较:对筛选后的用户进行两两比较,检查每一对是否都满足条件。
- 聚合和输出:将所有满足条件的用户对收集起来,并按照要求的格式(例如,
(user_id_1, user_id_2))输出。
这个过程不仅考验模型的信息提取和聚合能力,更考验其在面对海量信息时的策略规划和计算效率。传统的LLM在这种任务上往往会因为上下文窗口被撑爆或注意力被稀释而彻底失效。
4.2 RLM vs. GPT-5:性能碾压
4.2.1 GPT-5的崩溃:F1分数仅为0.04%
在OOLONG-Pairs这个极具挑战性的二次方复杂度任务上,即使是像GPT-5这样拥有巨大上下文窗口的前沿模型,也表现出了彻底的“痴呆”。根据MIT研究团队的实验数据,当直接让GPT-5处理OOLONG-Pairs任务时,其F1分数仅为0.04% 。这个分数基本上等同于随机猜测,表明模型完全无法理解和完成这个任务。其根本原因在于,OOLONG-Pairs任务要求模型对输入中的大量条目进行成对的、复杂的语义比较和聚合。当输入长度增加时,需要比较的对数呈二次方增长,这迅速超出了GPT-5的上下文窗口容量和注意力机制的处理能力。模型无法在如此长的上下文中维持对每一对用户及其属性的精确记忆,导致其推理过程完全崩溃。这一结果有力地证明了,即使是最先进的LLM,在面对高复杂度的长文本推理任务时,其“上下文腐烂”问题也极为严重,单纯依靠扩大上下文窗口无法解决根本问题。
4.2.2 RLM的崛起:F1分数飙升至58%
与GPT-5的彻底崩溃形成鲜明对比的是,采用了递归语言模型(RLM)架构的GPT-5,在同样的OOLONG-Pairs任务上取得了惊人的58.00%的F1分数 。这是一个质的飞跃,从几乎为零的性能提升到了一个相当可观的水平。RLM的成功,归功于其独特的“分而治之”和递归调用的机制。面对OOLONG-Pairs任务,RLM并不会试图一次性处理所有数据。相反,它会首先编写Python代码来解析数据结构,提取出所有用户ID及其关联的标签。然后,它可能会采用一种策略,例如,先筛选出所有包含特定标签的用户,然后对这些筛选后的用户进行成对比较。在比较的过程中,它可以通过llm_query递归地调用子模型来验证每一对用户是否满足条件。这种将复杂任务层层分解的方式,使得每个子模型都只需要处理一个非常小的、局部的上下文,从而避免了“上下文腐烂”的问题。最终,RLM能够高效地聚合所有子任务的结果,得出正确的答案。
4.2.3 消融实验:递归调用带来的关键提升
为了进一步验证RLM架构中各个组件的重要性,MIT的研究团队还进行了一系列消融实验(Ablation Study)。其中一个关键的实验是,测试一个不包含递归子模型调用功能的RLM版本(即模型只能使用REPL环境进行代码操作,但不能调用llm_query)。在OOLONG-Pairs任务上,这个“无递归调用”的RLM版本取得了43.93%的F1分数 。这个成绩虽然低于完整版RLM的58.00%,但仍然远远超过了基础GPT-5的0.04%。这一结果有力地证明了RLM架构的第一大优势——将上下文外部化到REPL环境——本身就具有巨大的价值。仅仅通过赋予模型用代码与长文本交互的能力,就使其能够处理远超其原生上下文窗口的信息,并显著提升了在复杂任务上的表现。然而,完整版RLM与“无递归调用”变体之间超过14个百分点的性能差距(58.00% vs 43.93%),则凸显了递归调用机制的关键作用 。在面对OOLONG-Pairs这类信息极度密集的任务时,仅仅依靠单次或几次代码交互往往不足以完成所有必要的推理。递归调用允许模型进行深度、多层次的“分而治之”。它可以不断地将一个大问题分解为小问题,再将小问题分解为更小的问题,直到每个子任务都足够简单,可以被一个轻量级的子模型可靠地解决。这种深度分解的能力,使得RLM能够处理那些需要层层递进、环环相扣的复杂推理链条,而这正是“无递归调用”版本所欠缺的。
4.3 成本分析:RLM不仅更强,还可能更便宜
4.3.1 选择性处理上下文,降低Token消耗
在评估一项新技术时,性能并非唯一的考量因素,成本效益同样至关重要,尤其是在大语言模型这种计算资源消耗巨大的领域。一个普遍的直觉是,RLM通过多次调用模型和复杂的交互流程,其成本必然会远高于单次调用基础模型。然而,MIT的研究结果出人意料地表明,RLM不仅在性能上碾压传统方法,在成本上也可能更具优势,甚至更加便宜。这一发现颠覆了“更强性能必然意味着更高成本”的传统观念,为RLM的实际应用和普及铺平了道路。RLM能够实现成本效益的核心原因在于其“选择性处理”的策略。传统的长文本处理方法,如直接将全文输入模型或采用“摘要代理”(Summary Agent)进行上下文压缩,都不可避免地需要处理大量的、可能与最终任务无关的tokens 。而RLM则完全不同,它通过Python REPL环境,可以像使用数据库查询一样,只提取和处理与当前子任务最相关的信息片段 。这种“先过滤、后精读”的策略,极大地减少了无效信息的处理,从而显著降低了总的token消耗。
4.3.2 与传统长文本处理方案的成本对比
为了更全面地评估RLM的成本效益,研究人员将其与多种主流的长文本处理方案进行了对比。这些方案包括:基础模型直接调用(Base Model)、摘要代理(Summary Agent)以及代码执行+检索代理(CodeAct + BM25)等。
| 方法 (Method) | CodeQA (23K-4.2M tokens) | BrowseComp+ (1K) (6M-11M tokens) | OOLONG (131K tokens) | OOLONG-Pairs (32K tokens) |
|---|
| **基础模型 (Base Model)** | 20.00%* | 0.00%* | 44.00% (GPT-5) | <0.1% (GPT-5) |
| **摘要代理 (Summary Agent)** | 58.00% ($1.31) | 70.47% ($0.57) | 46.00% ($0.13) | 0.01% ($0.13) |
| **RLM (无递归调用)** | 58.00% ($0.18) | 88.00% ($0.44) | 36.00% ($0.37) | 43.93% ($0.69) |
| **完整RLM (Full RLM)** | **62.00% ($0.11)** | **91.33% ($0.99)** | **56.50% ($0.43)** | **58.00% ($0.33)** |
注:带号表示该方法因输入超出上下文限制而无法运行,成绩为0。成本数据为平均API成本,单位为美元,括号内为标准差。数据来源于论文中的Table 1 。
从上表可以得出几个关键结论:
性能优势:在几乎所有任务上,完整版RLM的性能都显著优于其他所有方法。在BrowseComp+任务上,RLM的准确率(91.33%)比摘要代理(70.47%)高出超过21个百分点 。在OOLONG-Pairs上,RLM更是实现了从无到有的突破。
成本优势:RLM的成本极具竞争力。在CodeQA和OOLONG-Pairs任务上,RLM的平均成本是所有方法中最低的。在BrowseComp+任务上,RLM的成本($0.99)远低于直接调用GPT-5的理论成本($1.50-$2.75)。
综合效益:综合来看,RLM在性能和成本两个维度上都展现出了卓越的优势。它通过智能的任务分解和选择性信息处理,实现了“花更少的钱,办更好的事”。这种高性价比的特性,使其在实际应用中具有巨大的吸引力,尤其是在需要处理海量数据和进行复杂推理的场景中,如金融分析、法律研究和科学文献综述等。
5. RLM的潜力与应用场景
5.1 财报分析:从“复读机”到智能分析师
递归语言模型(RLM)的出现,为解决当前AI在财报分析等领域的“复读机”困境提供了革命性的解决方案。传统的LLM在处理动辄数百页的上市公司年报时,往往只能进行简单的信息提取和复述,难以进行跨章节、跨年度的复杂逻辑推理。而RLM则能够像一位经验丰富的财务分析师一样,有策略地处理和分析财报。例如,当面对一份冗长的年度报告时,RLM可以首先利用Python REPL环境,通过关键词搜索和结构化提取,快速定位到“管理层讨论与分析”、“财务报表附注”、“分部信息”等关键章节。然后,它可以递归地调用子模型,对每个章节进行深度分析,例如,让子模型专门负责分析现金流的变化趋势,另一个子模型负责评估不同业务板块的盈利能力。最后,主模型将所有子模型的分析结果进行整合,进行交叉验证和趋势预测,最终生成一份包含风险评估、同业对比和未来展望的深度分析报告。这使得AI从一个只能复述数字的“复读机”,转变为一个能够进行复杂逻辑推理和前瞻性判断的智能分析师。
5.2 代码理解:处理超大规模代码库
在软件工程领域,理解和维护超大规模的代码库一直是一个巨大的挑战。RLM为解决这一难题提供了全新的思路。通过将整个代码库加载到Python REPL环境中,RLM可以编写代码来对代码库进行各种复杂的分析和操作。例如,当开发人员需要理解一个大型开源项目的架构时,RLM可以首先通过代码分析文件目录结构和模块间的依赖关系,生成一个高层次的架构图。然后,它可以递归地调用子模型,对每个核心模块或关键函数进行深入分析,理解其功能、输入输出以及潜在的副作用。这种能力对于代码审查、漏洞检测、自动化测试和代码生成等任务都具有重要的价值。例如,当需要修改一个大型项目中的某个功能时,RLM可以帮助开发人员快速定位到所有相关的代码文件,并分析修改可能带来的影响,从而大大提高开发效率和代码质量。
5.3 长文档摘要:跨文档信息聚合与推理
RLM在处理长文档摘要任务时,也展现出了超越传统方法的优势。传统的摘要方法往往只能对单个文档进行摘要,难以进行跨文档的信息聚合和推理。而RLM可以通过其递归调用的机制,实现对多个长文档的深度理解和综合摘要。例如,当需要对某个主题的数十篇研究论文进行综述时,RLM可以先调用子模型对每篇论文进行摘要,提取其核心观点和贡献。然后,根模型再对这些摘要进行整合,识别不同论文之间的关联、争议和演进脉络,最终生成一篇结构清晰、内容全面的综述性文章。这种能力对于学术研究、市场调研、情报分析等领域都具有重要的应用价值。它能够帮助研究人员和分析师从海量的信息中快速提炼出核心洞察,极大地提高了知识获取和创造的效率。
5.4 其他领域:法律、科研、金融等
除了上述领域,RLM在法律、科研、金融等需要进行大量长文本分析和推理的领域,都具有广泛的应用前景。例如,在法律领域,RLM可以帮助律师快速分析大量的法律文件和判例,找到相关的法律依据和判例支持,甚至可以识别出合同中可能存在的矛盾和风险条款。在科研领域,RLM可以帮助科学家从海量的文献中提取关键信息,发现新的研究方向,或者对实验数据进行复杂的分析和建模。在金融领域,RLM可以用于分析市场报告、新闻资讯和社交媒体数据,进行舆情分析和市场预测,或者对复杂的金融衍生品进行风险评估。总而言之,任何需要从大量文本中进行深度信息提取和复杂推理的场景,都是RLM可以大展拳脚的舞台。
6. RLM的哲学意义:神经符号系统与AGI的未来
6.1 神经符号系统(Neuro-Symbolic System)的融合
6.1.1 神经网络:负责直觉与语义理解
递归语言模型(RLM)的架构设计,深刻地体现了“神经符号系统”(Neuro-Symbolic System)的融合思想。在这个框架中,神经网络(即大型语言模型)扮演着 “直觉”和“语义理解” 的角色。LLM强大的自然语言处理能力使其能够像人类一样,从文本中快速捕捉语义、情感和上下文关系。在RLM中,无论是主模型(Root LLM)制定宏观的处理策略,还是子模型(Sub-LM)对文本片段进行微观的分析和总结,都依赖于LLM的这种直觉式的理解能力。例如,主模型需要“直觉”地判断应该对哪个部分进行切片,子模型需要“理解”一段文字的核心思想。这种基于模式识别和统计学习的“神经网络”部分,为整个系统提供了强大的感知和初步推理能力,是其智能的“感性”基础。
6.1.2 符号系统:负责逻辑与精确控制
与神经网络相对应,RLM中的符号系统则扮演着 “逻辑”和“精确控制” 的角色。这个符号系统主要由Python REPL环境及其支持的代码执行能力构成。当LLM需要进行精确的、确定性的操作时,它会求助于这个符号系统。例如,计算文本长度、按特定规则筛选数据、进行数值计算、或者将多个结果进行结构化的聚合,这些任务都通过执行Python代码来完成。代码的执行是确定性的、无歧义的,它为整个推理过程提供了坚实的“逻辑”骨架。这种符号化的控制,弥补了神经网络在处理精确逻辑和复杂计算方面的不足,使得整个系统能够进行严谨、可靠的推理。RLM的成功,正是将LLM的“模糊”直觉与代码的“精确”逻辑完美结合的典范。
6.2 RLM是否是通往AGI的正确道路?
6.2.1 从“黑盒”到“可解释”的推理
RLM的架构不仅在性能上取得了突破,更在可解释性方面迈出了重要一步。传统的LLM在很大程度上是一个“黑盒”,其推理过程难以被理解和验证。而RLM通过将推理过程分解为一系列明确的、可执行的代码步骤和递归调用,使得其“思考”过程变得更加透明和可解释。我们可以清晰地看到模型是如何一步步地分解问题、筛选信息、调用子模型并最终整合结果的。这种结构化的、可追踪的推理过程,不仅有助于我们理解和调试模型的行为,也为构建更值得信赖和可靠的AI系统奠定了基础。在追求通用人工智能(AGI)的道路上,可解释性是一个至关重要的因素,而RLM所展现出的这种“白盒”特性,使其成为通往AGI的一个极具潜力的方向。
6.2.2 从“记忆”到“思考”的范式转变
RLM所代表的,是一种从“记忆”到“思考”的深刻范式转变。传统的LLM在很大程度上依赖于其庞大的参数和训练数据,通过“记忆”和模式匹配来回答问题。而RLM则更像一个真正的“思考者”,它不再被动地接收信息,而是主动地探索、分解、推理和验证。它学会了如何“使用工具”(Python REPL),如何“管理资源”(递归调用子模型),以及如何“规划任务”(制定处理策略)。这种主动、动态、结构化的认知过程,更接近于人类的思考方式。许多研究者认为,通往AGI的道路必须依赖于这种神经符号系统的融合,即结合神经网络的学习能力和符号系统的推理能力。RLM的成功实践,为这一理论提供了强有力的支持,并为我们描绘了一幅通往更高级别人工智能的清晰蓝图。
7. 结论:RLM重塑AI的未来
7.1 总结:RLM如何解决“上下文腐烂”
总而言之,递归语言模型(RLM)通过一种颠覆性的范式转变,成功地解决了困扰当前大语言模型已久的“上下文腐烂”问题。它不再将长文本视为需要被一次性“吞下”的记忆负担,而是将其外部化为一个可供程序化处理的环境。通过赋予模型编写和执行Python代码的能力,RLM让LLM学会了如何像管理者一样,主动地、有策略地筛选和分解信息。其核心机制——递归调用,使得模型能够将一个庞大而复杂的推理任务,层层分解为一系列更小、更易于管理的子任务,并调用子模型来高效处理。这种“分而治之”的策略,从根本上规避了Transformer架构在处理长序列时面临的注意力稀释和逻辑崩塌等瓶颈,将模型的有效推理能力提升了数个数量级。
7.2 展望:递归智能的无限可能
RLM的出现,不仅仅是技术上的一次突破,更是对AI未来发展路径的一次深刻启示。它所代表的“神经符号”融合思想,以及从“记忆”到“思考”的范式转变,为我们指明了通往更强大、更可靠、更接近人类智能的AGI的可能方向。展望未来,我们可以预见,基于RLM的递归智能将在更多领域展现出其无限的可能性。从能够深度分析全球金融市场的智能经济顾问,到能够理解并维护数百万行代码的自动化软件工程师,再到能够从海量科研文献中发现新知识、提出新假说的AI科学家,RLM所开启的递归智能时代,将极大地拓展AI的能力边界,深刻地改变我们与信息、知识和智能交互的方式,最终重塑AI乃至人类社会的未来。