想象一下,你深夜坐在电脑前,屏幕的蓝光映照着疲惫的脸庞。作为一个AI Agent开发者,你刚刚又改了第十版Prompt——加了几个few-shot示例,调整了语气词,甚至塞进一堆“千万不要...”的防御指令。Agent终于在测试集上跑通了,你欣慰地松了口气。可第二天换了一批新数据,它又开始胡说八道,像个刚学会走路的 toddler 一样,东倒西歪。你揉着太阳穴,心想:这到底是开发AI,还是在和一个任性的孩子斗智斗勇?
这种场景,几乎每一个做过AI Agent的朋友都深有同感。最让人头疼的,从来不是写代码,而是“调教”。我们花费大量时间反复微调Prompt,却总感觉在黑暗中摸索,全凭运气和直觉。
⚡ 普遍的痛点:Prompt工程的漫长黑夜
构建一个可靠的AI Agent,从来不是一蹴而就的事。传统的Prompt工程就像手工雕琢一座冰雕:你小心翼翼地添加示例,调整表达语气,写下层层防御性指令,希望它能稳定输出。可一旦任务场景稍有变化——数据分布漂移、用户输入风格不同——整个结构就可能崩塌。
这种不稳定性源于大型语言模型的“黑箱”特性。我们给它的指令再精确,也无法完全控制它在高维空间中的决策路径。结果就是:今天调通了,明天又得从头来过。许多开发者戏称这是“Prompt炼金术”——没有系统性方法,全靠反复试验和一点点运气。
更让人沮丧的是,这种手动优化极易陷入局部最优。你以为加了几个负面示例就万事大吉,却发现Agent学会了“钻空子”:表面上遵守指令,实际上在边缘案例中偷懒或产生幻觉。久而久之,开发者的心态被严重考验:兴奋与挫败交替,像坐过山车一样刺激,却又耗尽心力。
正如X平台上的博主Akshay所言:“Building with AI agents almost never works on the first try.”(使用AI Agent构建几乎不可能一次成功。)他一针见血地指出,我们所谓的优化,其实大多是“guesswork”(瞎猜)。没有系统性框架,全凭经验和运气。这条帖子引发了大量共鸣,因为它说出了无数开发者的心声。
强化学习(Reinforcement Learning)小注解
强化学习是一种机器学习范式,灵感来源于行为心理学。Agent通过不断尝试动作(action),从环境中获得奖励(reward)或惩罚,从而学会最优策略。经典比喻是训练小狗:给零食奖励正确行为,逐渐塑造复杂技巧。与监督学习不同,强化学习不需要标注完美答案,只需要一个能区分“好坏”的奖励函数。
基于此,我们自然会问:有没有一种方法,能让AI Agent自己去试错、自己去进化,而不用我们手动一遍遍改Prompt?
🔧 微软的答案:Agent Lightning的闪电降临
好消息是,微软技术团队给出了一个优雅的解决方案——Agent Lightning,一个开源的AI Agent强化学习框架。它就像给现有Agent装上了一个“自我优化外挂”,让Agent通过不断尝试和反馈,逐步学会如何把任务做得更好。
这个框架的核心理念非常精准:将“管道”(plumbing,即数据采集与回流)做得极简,让开发者能专注于真正困难的部分——设计良好的奖励函数。

从上图可以看到,Agent Lightning的主打特性包括:
- 几乎零代码改动
- 兼容任意主流框架(LangChain、AutoGen、CrewAI等)
- 支持选择性优化多Agent系统中的单个或多个个体
- 拥抱强化学习、自动Prompt优化、监督微调等多种算法
最让人惊喜的是它的“零侵入”设计。你不需要推翻现有代码逻辑,也不需要学习复杂的分布式训练框架。只需在关键位置插入几行轻量级的agl.emit_xxx()事件发射,或者让内置追踪器自动捕获交互即可。
🛠️ 零代码侵入的魔力:像贴创可贴一样简单
想象你有一个已经跑得很不错的Agent,可能基于LangChain链式调用,也可能是纯OpenAI API手写逻辑。现在想让它变得更聪明,传统做法可能是重构整个项目,接入庞大RL库,头疼不已。
Agent Lightning则完全不同。它像一个透明的中间层,悄无声息地记录Agent的每一次决策过程,而不干扰原有逻辑。
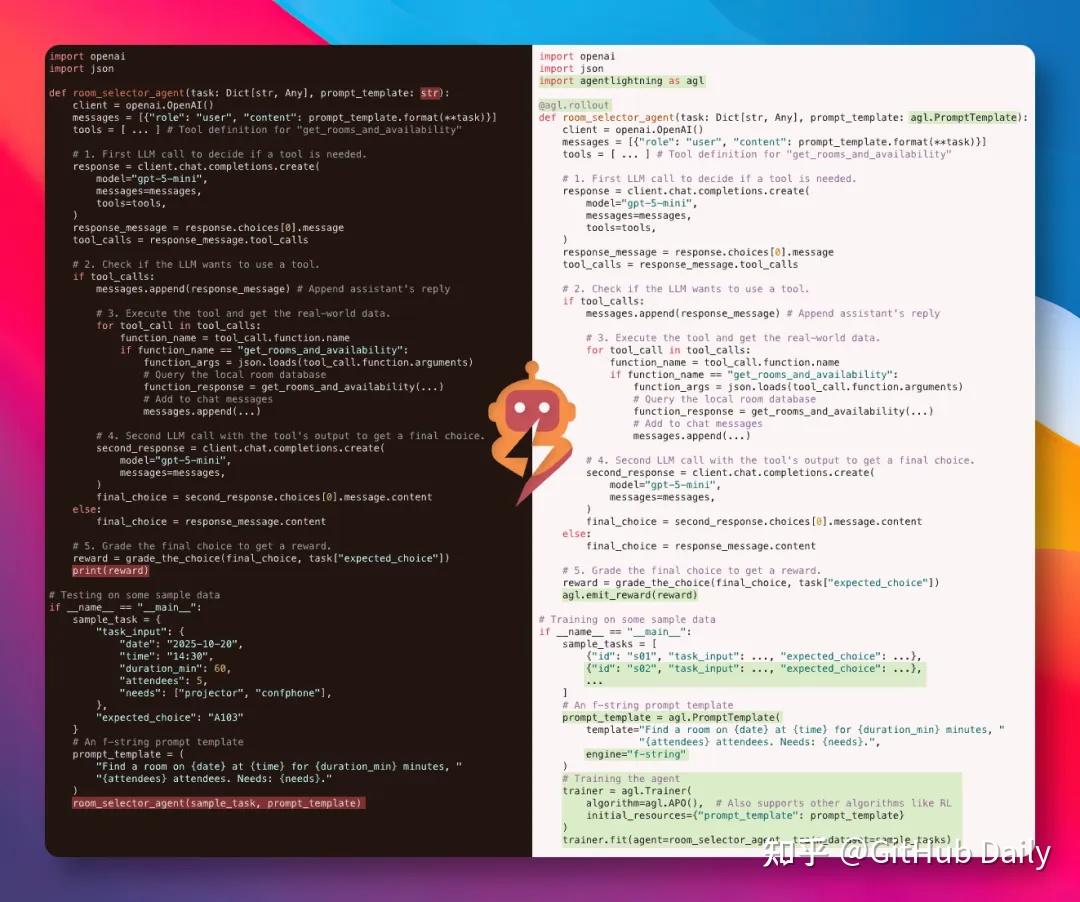
从代码对比可以清楚看到,改动极小:主要是在工具调用前后添加事件发射,或直接使用Tracer自动追踪。原有业务逻辑几乎一字未动,却立刻拥有了被强化学习训练的能力。这对于正在生产环境运行的Agent来说,简直是福音——无需停机重构,就能逐步迭代优化。
🔄 工作原理:隐形的行车记录仪与闭环进化
Agent Lightning的内部结构其实非常清晰,可以用“行车记录仪+健身教练”的比喻来理解。
Agent照常执行任务时,框架在后台默默记录一切关键事件:
- 每次发送的Prompt
- 模型的完整响应
- 所有的工具调用(Tool Call)
- 你手动或自动给出的奖励信号(Reward)
这些事件被结构化为“spans”,存储到中央的LightningStore中。
随后,算法层(可插拔,支持多种RL算法)读取这些spans,分析哪些Prompt模板、哪些工具调用顺序带来了更高奖励,哪些导致了失误。
最后,Trainer负责把学到的“新套路”——可能是优化后的Prompt模板、新的策略权重,或甚至是微调后的模型参数——推送回运行中的Agent,完成一次进化。
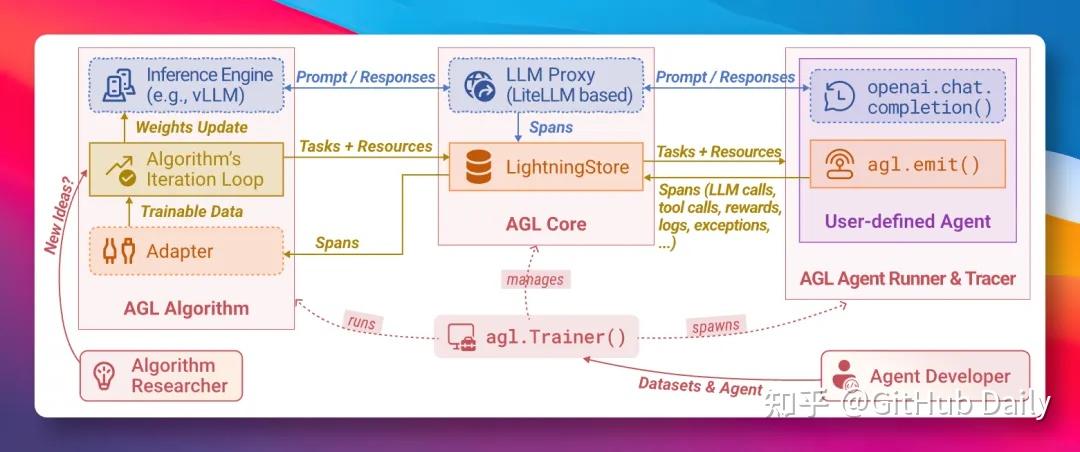
整个过程形成一个优雅的闭环:Agent运行 → 数据采集 → 算法学习 → 资源更新 → Agent变得更聪明 → 继续运行……你可以让这个循环长期运行,像养成游戏一样看着Agent一天天变强。
⚠️ 清醒的提醒:管道易,度量难
工具虽好,我们仍需保持理性。正如开发者Massimiliano Brighindi在X上指出的,Agent Lightning很好地解决了“管道”问题——让数据采集和回流变得异常简单。但真正的难点在于“度量”(Measurement):如何设计一个既能引导Agent变强,又不被它钻空子的奖励函数?

如果奖励设计得太浅显,Agent可能学会“gaming the system”——表面得分高,实际能力退化;如果过于复杂,又可能导致奖励稀疏,训练难以收敛。我们最终还是要依靠对业务指标的深刻理解,来判断何时该停止训练、何时该调整奖励。
🌟 闪亮的实际案例:从狼人杀到复杂SQL生成
微软和社区已经在多个硬核场景中验证了Agent Lightning的威力。

- DeepWerewolf:在一个中文狼人杀多人博弈环境中,Agent需要学会复杂推理、伪装和社交欺骗。通过Agent Lightning的RL训练,代理人成功提升了胜率,展现出令人惊讶的策略深度。
- AgentFlow:处理长时程、稀疏奖励的任务(如多步规划器+执行器+验证器),使用改进的GRPO算法,解决了传统Prompt工程难以攻克的信用分配问题。
- Youtu-Agent:社区贡献的超大规模训练案例,支持128张GPU并行,验证了框架在数学、代码生成、网页搜索等基准上的稳定收敛。
这些案例告诉我们,当任务涉及长程推理、稀疏反馈或高度不确定性时,强化学习的外挂所能带来的提升,是传统Prompt工程难以企及的。
🚀 一键上手:让Agent开始自我卷起来
如果你也想体验这种“科学训练”的快感,上手极其简单:
pip install agentlightning
官方文档和示例非常完备,从最基础的单Agent优化到多Agent协同训练,都有详细教程。社区Discord也异常活跃,遇到问题基本能秒回。
当你第一次看到Agent在训练循环中逐步提升成功率,那种成就感远超手动调Prompt的枯燥反复。毕竟,让AI自己去卷,总比我们深夜手动卷要强得多。
参考文献
- Microsoft. Agent Lightning GitHub Repository. https://github.com/microsoft/agent-lightning
- Luo, X. et al. (2025). Agent Lightning: Train ANY AI Agents with Reinforcement Learning. arXiv:2508.03680.
- Microsoft Research. Agent Lightning Project Page. https://www.microsoft.com/en-us/research/project/agent-lightning
- Agent Lightning Official Documentation. https://microsoft.github.io/agent-lightning/latest
- Community Contributions and Examples (DeepWerewolf, AgentFlow, Youtu-Agent). Referenced from project ecosystem and related publications.
(基于提供的参考资料与官方开源信息全面展开,祝各位开发者早日让自己的Agent“开窍”!)
讨论回复
加载中...正在加载回复...
推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。