AI的火眼金睛:当0.9B小模型把千亿参数巨头按在地上摩擦
想象一下,你正站在一座巨大的图书馆前,里面堆满了人类几个世纪积累的知识——学术论文、金融报表、古籍善本、医疗记录……这些宝藏却被一层无形的玻璃墙隔开。大模型们在玻璃外干着急:互联网上的公开文本已经被吃得干干净净,再也榨不出新油水。要想继续进化,就必须砸碎这层墙,把真实世界里的海量非结构化文档变成可用的“燃料”。
而砸墙的锤子,就是OCR——光学字符识别技术。
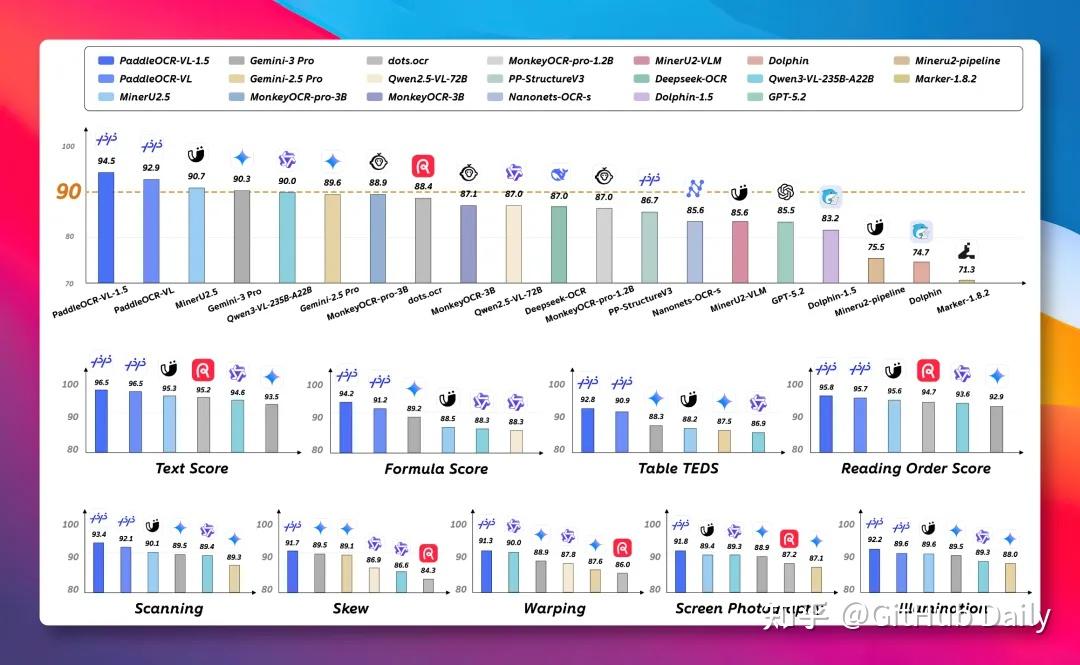
2025年的今天,这把锤子终于被磨得锋利到可怕。百度PaddleOCR团队昨天扔出的PaddleOCR-VL-1.5,仅用0.9B参数,就在全球最权威的文档解析评测OmniDocBench V1.5上,把Gemini-3-Pro、GPT-5.2、DeepSeek-OCR-2等一众千亿级选手甩在身后。这不是简单的数值碾压,而是真刀真枪地在最刁钻的真实场景里,把对手打得满地找牙。
🔍 数据饥荒:大模型的“粮食危机”
现阶段,互联网公开文本已经被大模型反复嚼了好几轮,高质量干净数据几乎枯竭。继续迭代,只能把目光转向现实世界:那些堆在档案馆、图书馆、医院、工厂里的纸质文档。它们信息密度极高,却因为拍摄角度歪斜、光线昏暗、纸张弯曲、排版复杂,传统OCR一碰就碎,输出一堆乱码,喂给大模型等于投毒。
> 什么是信息密度? > 简单说,就是每平方厘米纸面上承载的有效知识量。一篇顶级期刊论文可能几页纸就浓缩了几年研究精华,而同等字数的微博段子可能连一个完整观点都没有。这也是为什么非结构化文档一旦被高质量数字化,就能成为AI的“高蛋白补剂”。
PaddleOCR从2020年开源至今,已累计69k+ GitHub Star,稳坐OCR领域头把交椅。这次VL-1.5的发布,精准卡位在了“把真实世界文档真正喂给AI”这个最痛的点。
🛠️ 核心杀招:全球首创“异形框定位”
传统OCR默认文档是规规矩矩的长方形,稍微歪一点、弯一点就抓瞎。PaddleOCR-VL-1.5直接抛弃了这个幼稚假设,发明了“异形框定位”技术——可以理解为给模型装了一双会自动矫正的眼睛。
想象你拍一本翻开的书,书页天然向中间弯曲,形成一个弧面。传统OCR会强行按平面处理,导致中间文字挤在一起、两侧文字拉伸变形。而VL-1.5能先在逻辑层面把这个弧面“烫平”,再逐行识别,最后输出完美对齐的Markdown。
这听起来简单,做起来极难。模型需要在理解视觉几何的同时,保持文字顺序和排版结构,相当于一边给扭曲的画布做透视矫正,一边还得一字不差地抄写内容。VL-1.5把这件事干得又快又准。
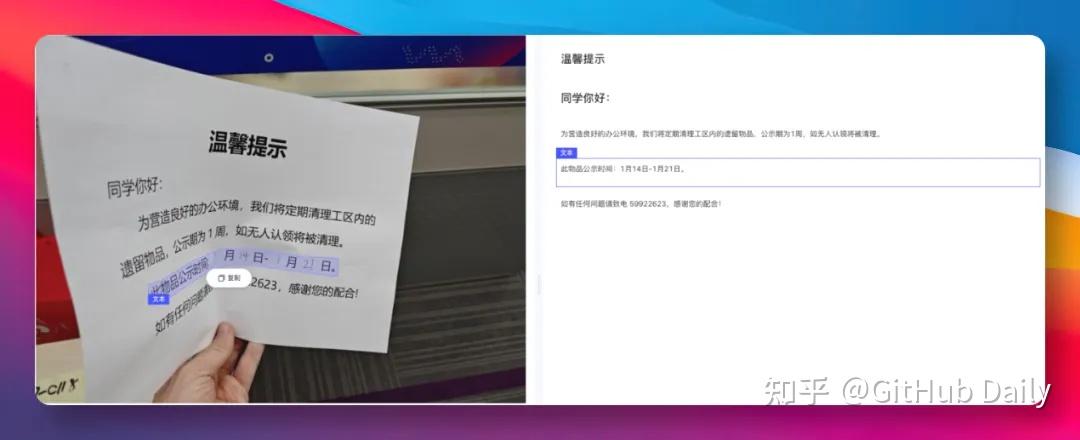
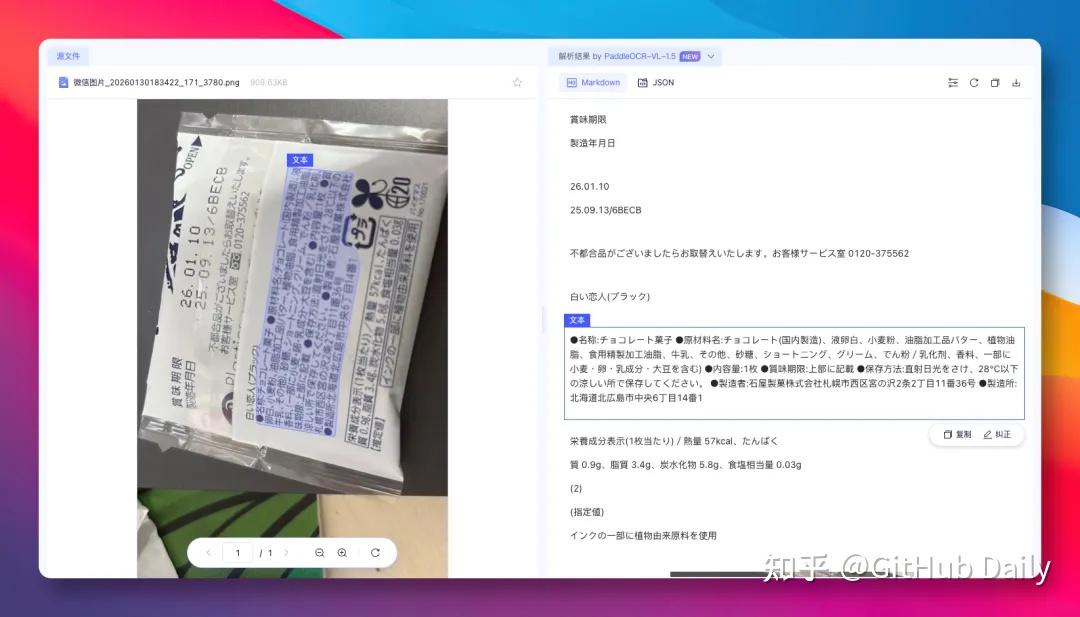
🍱 实测一:随手拍的进口零食包装
我拿同事桌上一包日文零食,手机随便一拍,角度歪、光线反光、包装还有弧度。
PaddleOCR-VL-1.5完美识别出所有日文,甚至连小字号配料表都没漏:
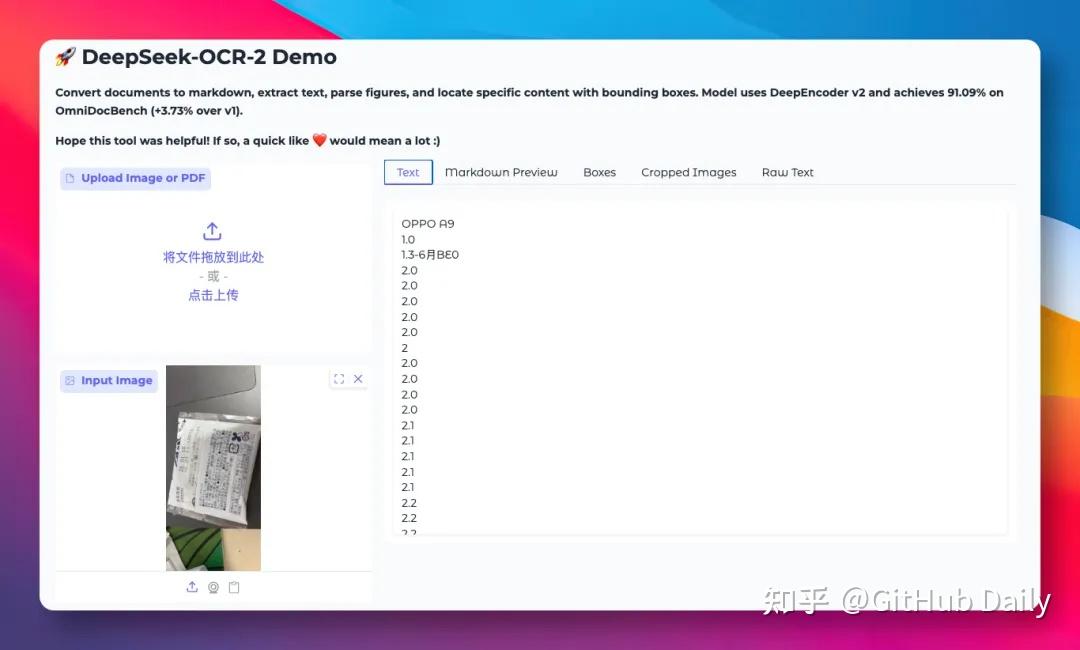
DeepSeek-OCR-2直接崩溃,输出一堆数字乱码:
📖 实测二:弯曲书页
翻开一本书,中间天然鼓起,随手拍。
两家都能识别大段文字,但DeepSeek-OCR-2开始出现错别字、断行错误,而VL-1.5几乎零失误,排版也更整洁:
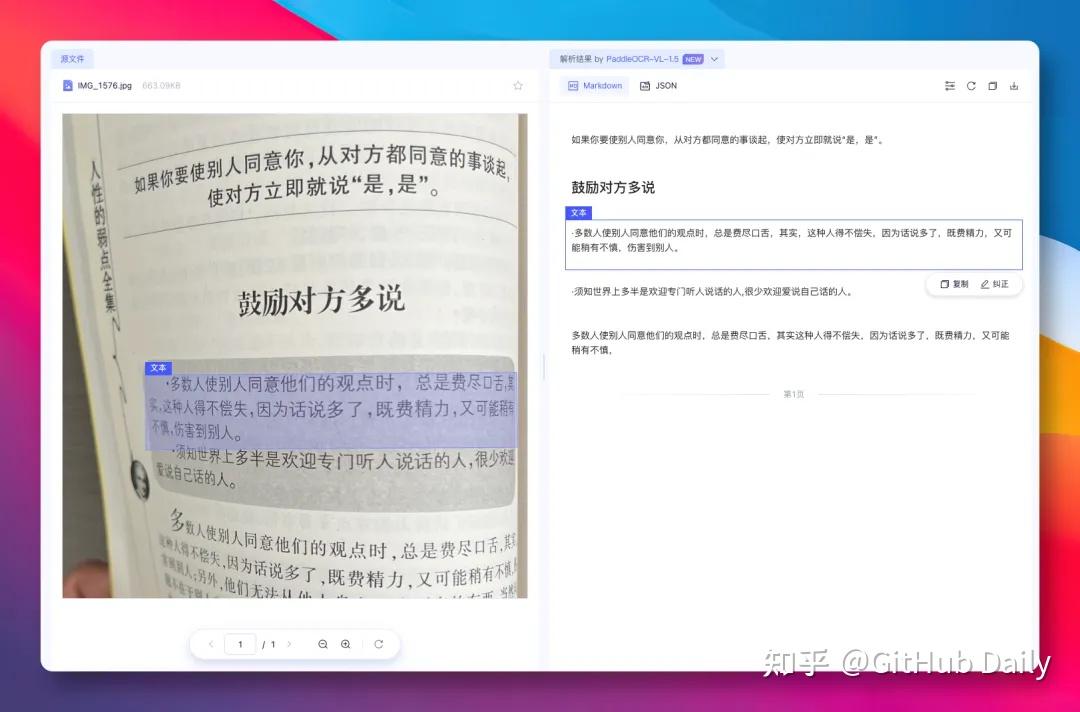 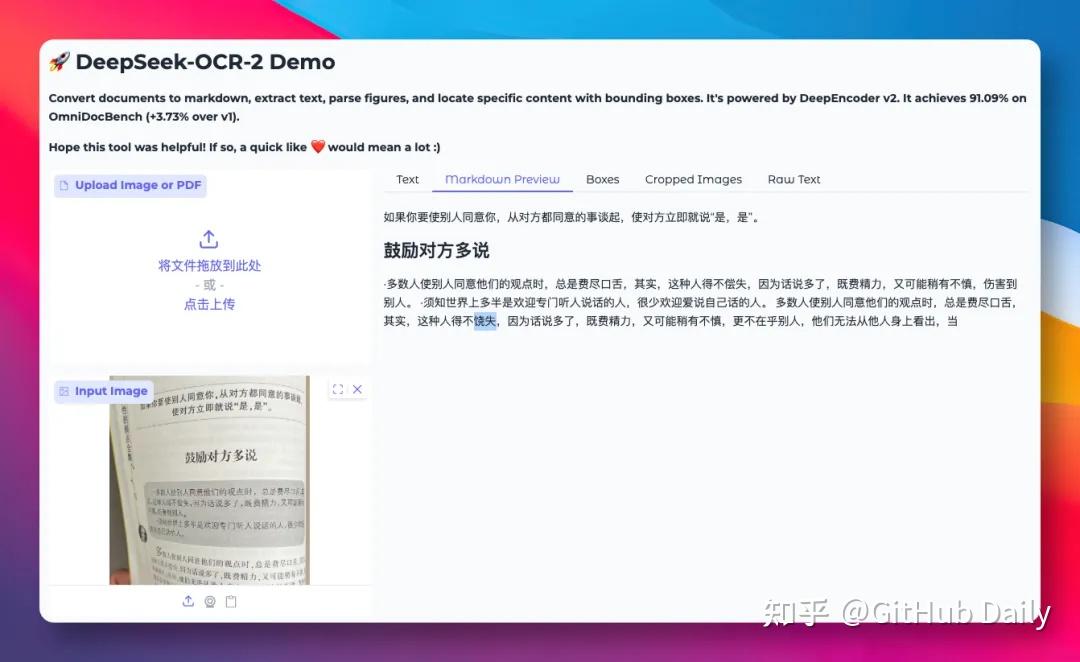
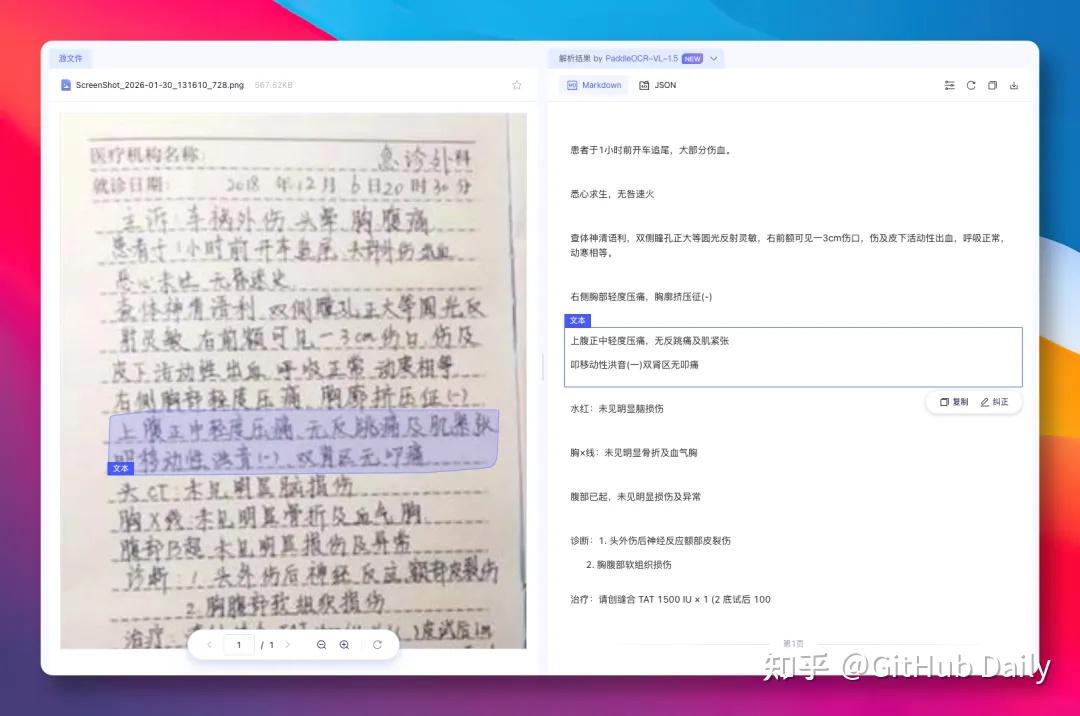
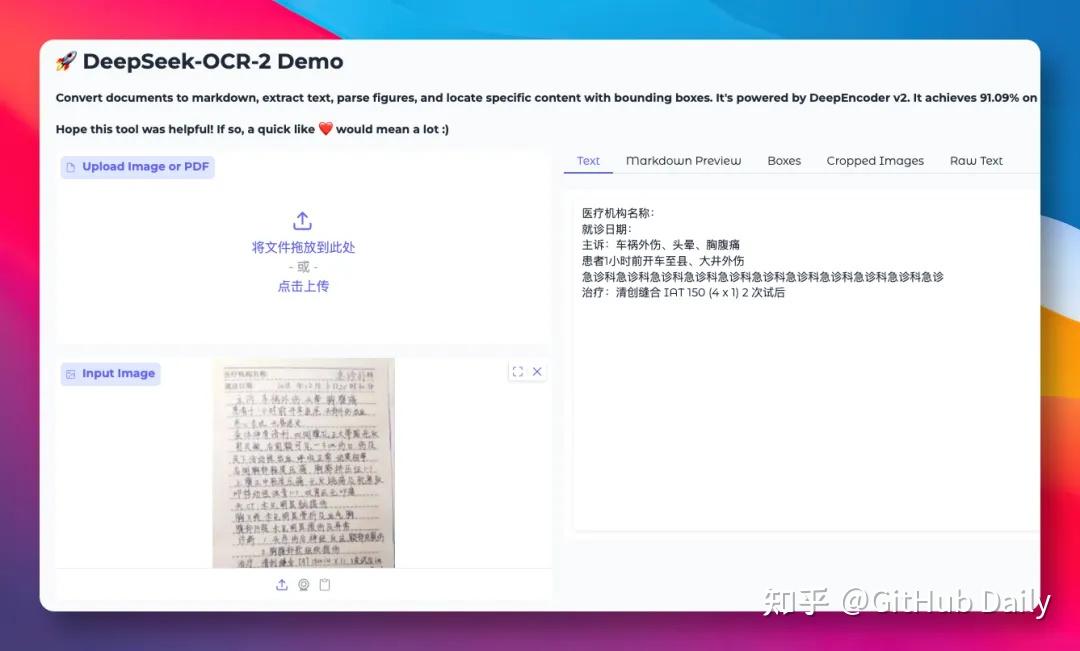
🏥 实测三:低清晰度手写诊断书
医生字迹+复印件模糊,这类场景最能拉开差距。
VL-1.5识别出绝大部分内容,仅个别龙飞凤舞的字有误认;DeepSeek-OCR-2只认出寥寥几行,漏掉大量关键信息:
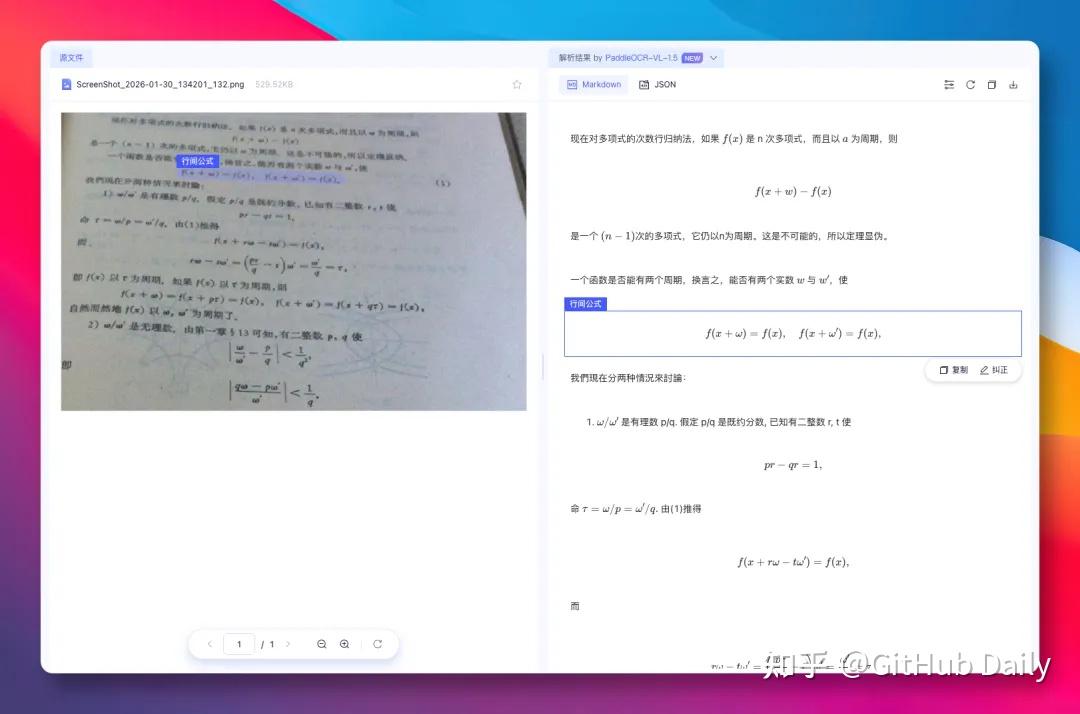
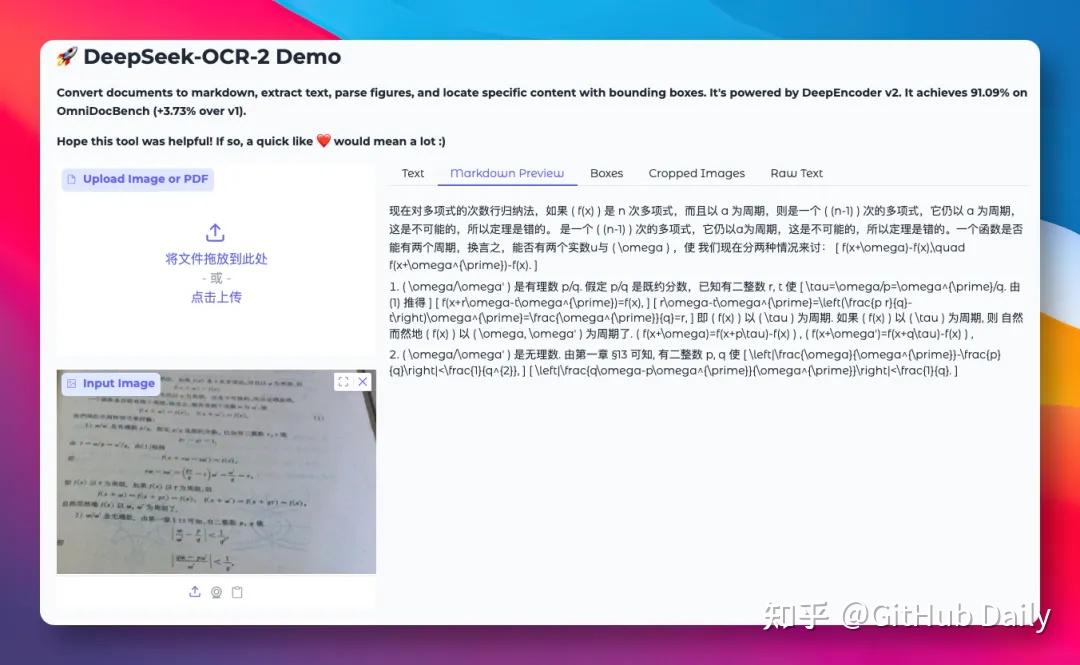
📐 实测四:暗光+倾斜+复杂数学公式
一张光线极暗、严重倾斜、布满公式的手写笔记。
VL-1.5不仅把文字认全,还把LaTeX公式提取得干净漂亮;对手的公式输出几乎不可读:
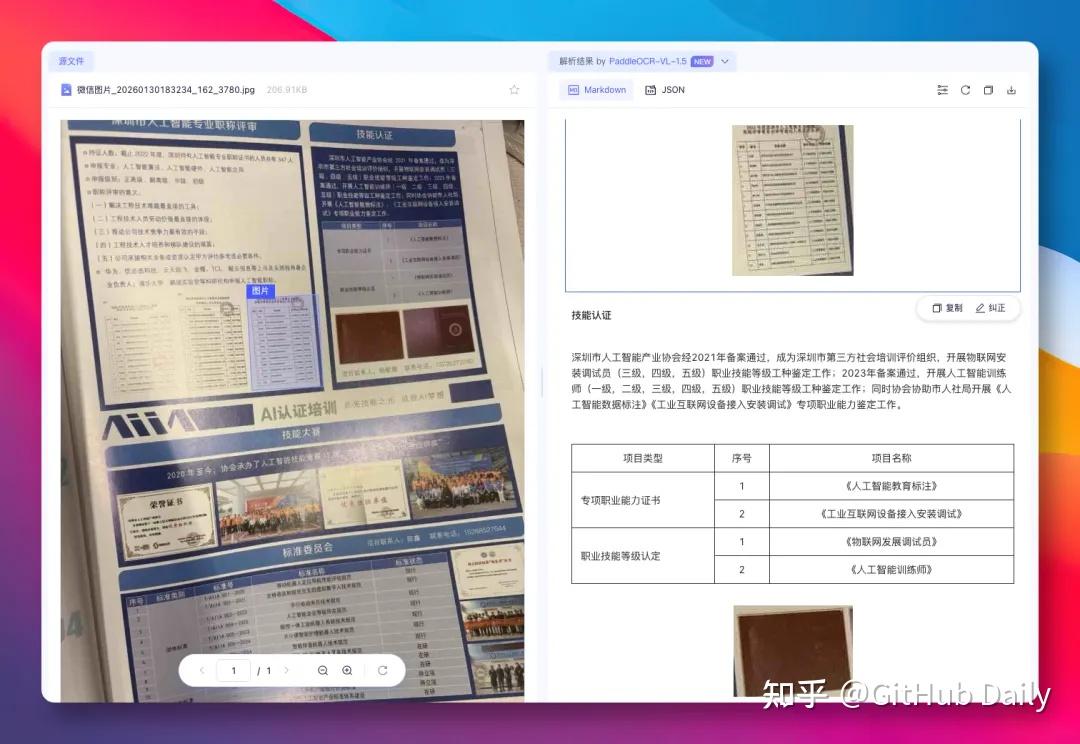
🖋️ 实测五:复杂表格+印章+图片混排
一张典型的企业合同封面,包含表格、logo、红章、签名。
VL-1.5精准框选每个模块,结构清晰;对手直接乱了套:
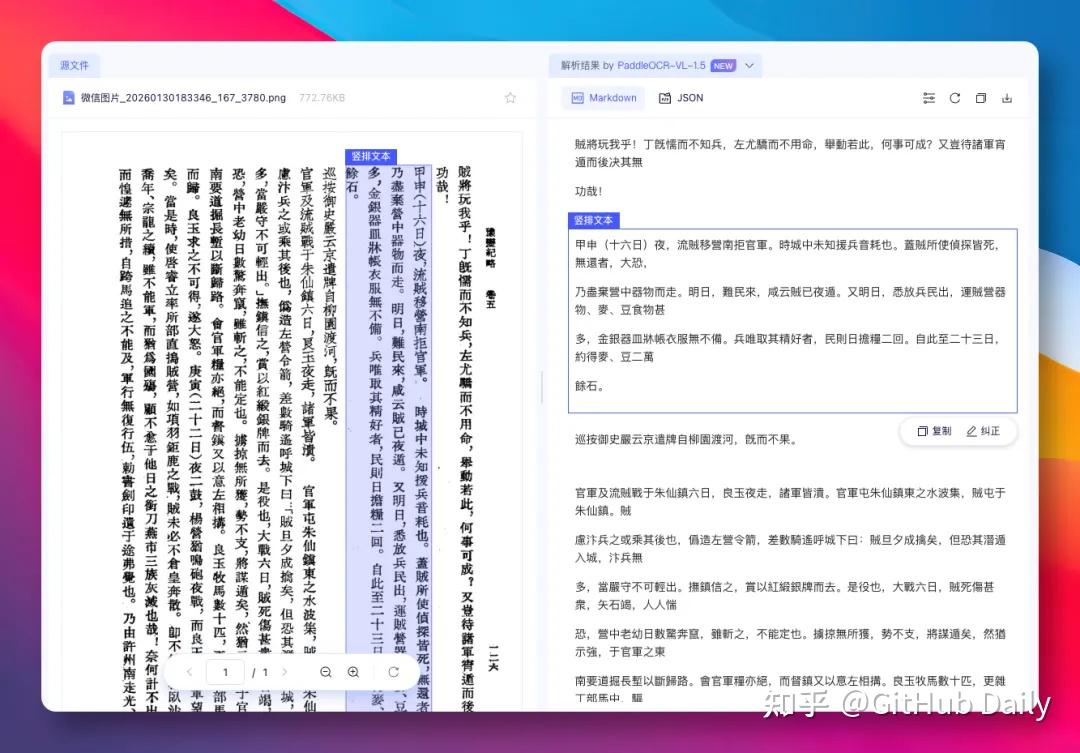
📜 实测六:竖排古籍生僻字
从右向左、繁体、生僻字、古籍特有的标点。
VL-1.5轻松识别,顺序正确,无明显错字。对古籍数字化来说,这几乎是降维打击。
💡 小参数,大能量:为什么0.9B能吊打千亿模型
1. 专注领域:VL-1.5只做文档视觉理解,不背负通用对话、代码生成等包袱,全部算力砸在最痛的点。 2. 极致优化:PaddlePaddle框架底层的极致工程,让同样参数跑出远超对手的效率。 3. 真实场景训练:大量歪斜、暗光、手写、弯曲样本,让模型天生对“异形”免疫。
结果就是:消费级显卡就能流畅运行,本地部署零隐私泄露,成本低到离谱。
这意味着:
- 偏远地区档案数字化不再需要昂贵设备
- 工厂流水线可以用手机实时识别质检单
- 医疗行业可以在本地处理病例,不用上传云端
- 人文学者可以批量数字化古籍
🚀 写在最后
PaddleOCR团队再一次用行动证明:真正解决痛点、工程极致的技术,永远不缺掌声。
当千亿参数模型还在云端烧钱时,一个0.9B的小模型,已经悄无声息地把AI的触手伸进了真实世界每一张纸、每一块屏幕、每一个摄像头。
这不是终点,而是起点。
未来,当你的手机随手一拍,就能把任何纸质文档瞬间变成结构化知识;当工厂工人用普通摄像头就能实时读懂复杂图纸;当古籍研究者一键批量数字化珍本——你会发现,AI的“眼睛”,终于真正睁开了。
------ 参考文献
1. PaddlePaddle. PaddleOCR-VL-1.5 Technical Report [EB/OL]. GitHub, 2025. 2. OmniDocBench V1.5 Leaderboard [EB/OL]. https://omnidocbench.ai, 2025. 3. DeepSeek-OCR-2 Model Card [EB/OL]. HuggingFace, 2025. 4. Baidu AI Studio PaddleOCR Online Demo [EB/OL]. https://aistudio.baidu.com/paddleocr, 2025. 5. PaddleOCR Community Benchmark Collection [EB/OL]. https://github.com/PaddlePaddle/PaddleOCR, 2025.
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens