🌊 **光影的秘密舞蹈:人眼如何“看”世界**
当我轻轻转动头部,房间里的花瓶瞬间“飞掠”而过,而远处的书架却像慢镜头一样缓缓移动,那一刻我突然明白:我们人眼看到的,从来不是一张死板的照片,而是一场充满距离与运动信息的“光流”盛宴。它像一条活泼的河流,不仅携带颜色和形状,更包裹着三维世界的动态秘密。正如我观察到的,Tesla在训练人形机器人时,大量使用这样的光流数据,因为它是对3D现实最生动、最具信息的2D表示。传统的静态图片时代已经结束了——图片只是显示器上的幻影,而人眼捕捉的是不断变化的流场。当你移动头部时,远近物体产生的光流速度截然不同:近物如疾风,远物如微风,这瞬间就暴露了屏幕的假象,因为显示器上的所有像素“滑动”速度一致,像被冻结的假世界。而镜子却不同,它的反射随你移动而真实变形,瞬间拉开真实与虚拟的界限。我甚至想起那些用摄像头简单替换后视镜的人,他们恐怕还没学懂基本的视觉原理——光流才是机器人和人类共同的“超级感官”!
> 光流(optical flow)本质上是图像序列中像素的运动向量场。它通过计算相邻帧间像素的位移,来推断场景中物体的相对速度和深度信息。举个生活例子:开车时,路边树木“流”得越快,就说明它们离你越近;远山几乎不动。这为机器人提供了无需复杂3D重建就能理解环境的强大工具,帮助它像生物一样本能反应,而不是死记硬背地图。
基于此,当我看到女王大学的学生们用TinyNav项目让一个20元ESP32单片机实现端到端自动驾驶时,我不由得拍案叫绝:他们正是把光流原理的精髓,巧妙移植到了微型硬件上,用深度图加时间堆叠,模拟出那份动态的3D感知。传统机器人动辄要高端GPU加SLAM算法的日子,真的要告别了!
🛠️ **轻装上阵的蚂蚁英雄:20元ESP32如何扛起大梦想**
想象一下,你手里握着一个只有火柴盒大小的“蚂蚁大脑”——ESP32-P4微控制器,它成本仅仅20美元,却要装下整个自动驾驶的智慧。这听起来像天方夜谭,但我亲眼“见证”了TinyNav如何在极端限制下大放异彩。核心硬件是Waveshare ESP32-P4-WIFI6-M,双核360MHz,32MB PSRAM和768KB高速缓存,再配上Sipeed MaixSense A010 ToF深度摄像头。这摄像头不像普通RGB相机只抓颜色,它用飞行时间法发射红外脉冲,测量反射时间,直接吐出每个像素的距离值——就像给机器人装上一双蝙蝠般的“声纳眼睛”,瞬间看穿远近。原始100x100分辨率在传感器端就4x4合并(binning)成25x25,再缩到24x24,数据量小到能塞进老爷车般的微控制器。
> ToF(Time-of-Flight)摄像头的工作原理是发射调制红外光脉冲,然后逐像素测量光线往返时间,直接计算距离,生成深度图。相比RGB,它避免了从2D猜3D的歧义,让输入信息“干净”如水晶,模型因此能更小更高效。举例:普通相机看墙是“灰色方块”,ToF却告诉你“前方1.2米有障碍”,机器人无需额外计算就能闪避。
我仿佛看到这个小家伙在赛道上蹦跶,像穷人家的孩子却玩出了F1的速度——这就是TinyML的魅力,把AI塞进微控制器,实现本地实时、低功耗的智能。抛弃云端或强大GPU的奢侈,TinyNav证明:智慧不在于硬件多大,而在于思路多巧!
📦 **自己动手丰衣足食:赛道上的数据采集奇幻冒险**
没有好数据,再聪明的模型也只是空壳。我特别喜欢TinyNav的务实劲儿:他们没偷懒用仿真,而是搭建实体赛道,用人手遥控小车一圈圈跑,同时记录ToF摄像头看到的深度图和操作者的转向、油门指令。这就像教孩子学开车——不是死记公式,而是手把手示范“看到墙就转弯,看到直道就加速”。赛道用可移动墙板组成,能随意变换宽窄、弯道、地面材质,甚至故意弄出死胡同,让数据尽可能多样。原始数据还做了水平翻转增强,像给记忆库加了镜像版本,训练更鲁棒。60/40的训练测试分割后,一个“图像-动作”配对的数据集就新鲜出炉了。
想想看:小车像勇敢的探险家,在迷宫中一次次试错,我仿佛听到它在说“下次我记得这个弯!”这种闭环从数据到部署的完整性,简直是嵌入式AI项目的教科书。基于此,我们进一步探索:如何把这些动态数据喂给那个23k参数的“小脑”呢?
🧠 **螺蛳壳里的道场:23k参数CNN如何炼成时空魔法**
机器人导航是连续的,需要记住“刚才发生了什么”才能预判未来。在高端设备上,我们用LSTM或3D卷积处理视频,但ESP32上这些层要么不支持,要么算力爆炸。TinyNav的解法简单粗暴却天才:把20帧连续深度图,像叠扑克牌一样堆成20通道的“超级图片”!输入变成24x24x20的时空块,用普通的2D CNN去卷积。它在扫过每个位置时,同时“瞟见”不同时间点的变化——隐式捕捉速度和运动趋势,就像你翻相册时瞬间感受到“物体在动”。
整个网络精简到极致:几层卷积加池化提取特征,最后两个并行全连接头,一个管转向(-1到1),一个管油门(0到1)。总参数只有23,000个!对比动辄百万参数的图像分类模型,这简直是把大象舞步浓缩成蚂蚁精准的步伐。想象你正站在赛道边,看着这个小模型像厨师同时品尝20层蛋糕的不同口味(每一层是不同时间的“味道”),直接吐出控制指令——端到端学习就是这么神奇:省去感知、建图、规划的中间环节,像生物本能一样从眼睛直达手脚。
> 端到端学习是指用单一神经网络直接从原始传感器数据映射到控制指令,省去传统模块的误差累积。举例:传统导航像分步学开车(先看路、再算地图、再决定转弯),而端到端像小孩子模仿大人开车,一眼看到就本能反应。虽然单个能力有限,但在特定任务上高效无比。
基于模型的巧妙设计,我们接着见证量化如何让它在微控制器上真正“活”起来。
✨ **压缩的艺术奇迹:INT8量化如何保留99.8%灵魂**
在只有32MB RAM和几百KB缓存的ESP32上跑神经网络,就像在老爷车上装F1引擎——处处是限制。TinyNav用TensorFlow Lite Micro的后训练量化,把浮点权重和计算转成8位整数。结果惊人:量化后模型在验证集上,转向精度保留了原版的99.84%,油门精度保留99.79%!几乎零损失,却换来内存和速度的巨大飞跃。一次推理(处理20帧并决策)只需30毫秒,完全满足实时控制。
这就像把一本彩色精装小说压缩成口袋本,却连每个情节的神韵都不丢。浮点模型像交响乐团,INT8像单人口哨,却吹出了同样的旋律。我不由得感慨:TinyML的精髓就在这里——把AI从云端拉到指尖,让穷玩机器人的人也能拥有智能。

(左为转向,右为油门。红点INT8与蓝点浮点高度重合,说明误差微乎其微。)
⚙️ **双核交响乐:推理与控制的完美和谐流水线**
30毫秒推理听起来快,但要保证小车不卡顿,TinyNav用ESP32的双核智慧:一个核专跑AI推理,另一个核管传感器采集和电机指令。通过共享内存交换最新20帧窗口和结果。即使偶尔推理慢一点,控制循环也不会被堵住——小车依然流畅如舞者。整个流水线从ToF数据采集、堆叠窗口、CNN推理,到双核并行输出转向油门,形成闭环。
想象小车在赛道上疾驰,我仿佛听到两个核在“对话”:“我算完了,你转弯!”这工程细节让我想起交响乐团:指挥(控制核)和演奏家(推理核)默契配合,才奏出无碰撞的乐章。
📈 **小车在迷宫中的华尔兹:预测与现实的亲密舞步**
光说模型小没用,关键是它学得像不像。TinyNav的验证扎实得像教科书。相关性分析显示,预测转向和油门与真实驾驶员(Ground Truth)的相关系数约0.6——对于23k参数模型,这已相当不错,说明它真学到了映射关系,而不是乱猜。分布图上,两条曲线高度重合:模型能从直行到急转、从全速到刹车,全范围决策,没有“懒惰”地永远输出零转向。

(灰点散布,红线趋势清晰正相关,像老朋友聊天般默契。)
定性上,Grad-CAM热力图揭开了黑箱:转向头爱关注图像上方(墙顶边缘),因为那是区分通道和障碍最稳定特征;油门头更聪明——直道看前方开阔区加速,死胡同盯正前方墙减速。这证明模型学会了根据环境结构调节速度,像老司机凭直觉刹车。
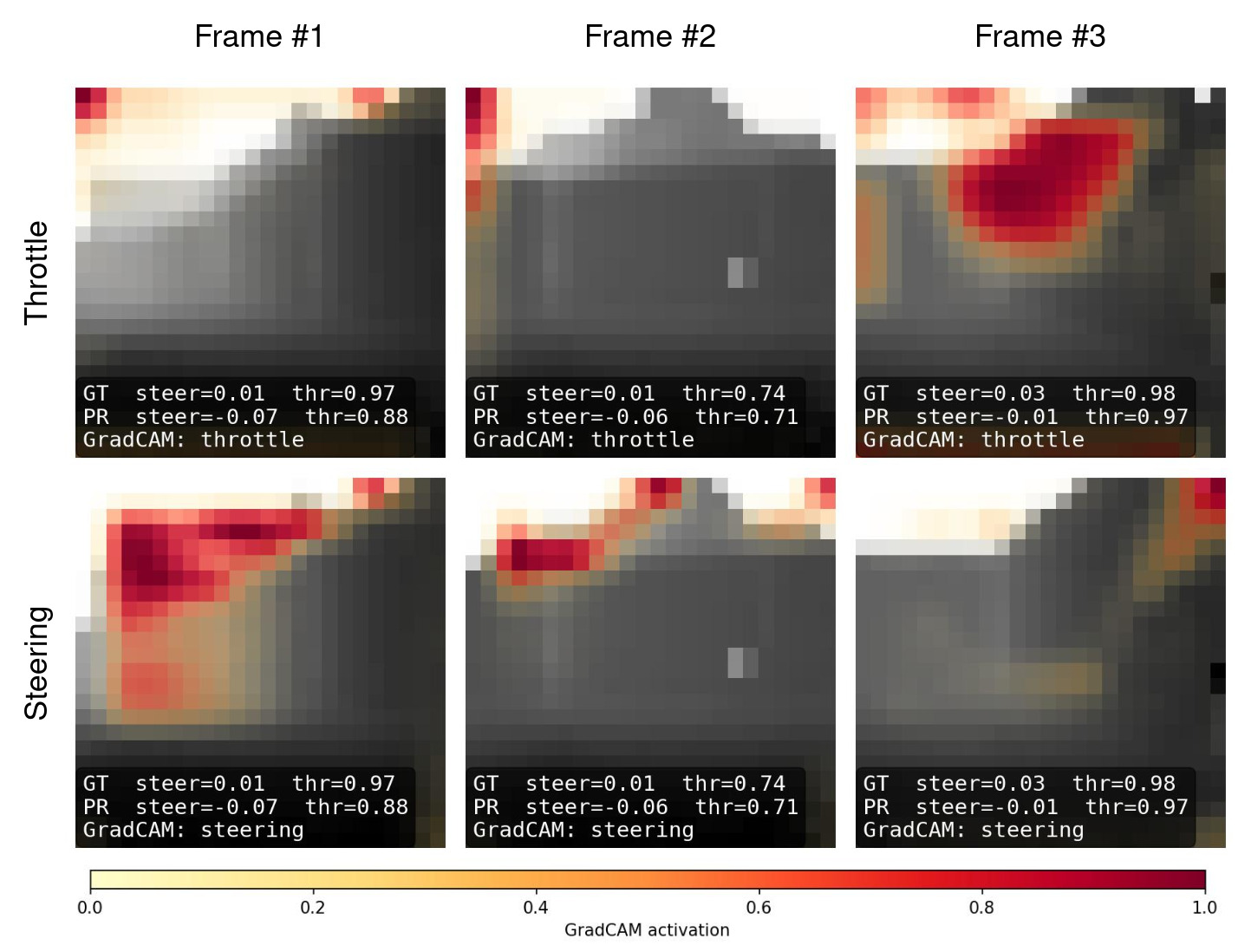
(左侧原始深度图,中间转向激活上方边缘,右侧油门关注迫近墙壁。)
> Grad-CAM(梯度加权类激活映射)通过梯度计算生成热力图,高亮输入中对决策影响最大的区域。它像给模型装上“X光眼镜”,让黑箱变得透明,帮助我们理解AI为什么这么决定。举例:人类司机看路标,模型也“看”墙边——这跨物种的共鸣太酷了!
实地测试更是传奇:在训练赛道上,小车连续跑40圈零碰撞;新布局虽偶尔轻刮,却顺利完成全程。油门智能调节:长直道加速,弯道平滑减速。我仿佛看到它在跳华尔兹——优雅、自信、充满生命力。
⚠️ **成长的痛点与未来希望:TinyNav的谦逊自省**
TinyNav虽精彩,但作者们坦诚得让我佩服。23k参数是优势也是天花板——ESP32上限大概5万参数,复杂场景就力不从心,像孩子词汇量有限讲不了长故事。数据集全来自矮墙室内赛道,没见过椅子、行人、台阶或户外光影,泛化能力弱得像只熟悉一条街的旅行者。缺乏轮子编码器,没里程计反馈,纯视觉容易“漂移”累积误差,像走路不看脚下容易绊倒。仅支持前向行驶,倒车动力学不同,训练数据没覆盖——想全向移动,得重头来过。
但这些局限恰恰是机遇:未来加低成本编码器、多传感器融合、仿真到实物迁移学习,就能让这个微型智者征服更广阔世界。我相信,TinyNav不是终点,而是TinyML在机器人领域的启明星——成本敏感的教育玩具、工业巡检、智能家居,都将因它而改变。
🗣️ **龙哥三问与深度解读:TinyML的本质魅力**
什么是TinyML?它像把AI从豪华别墅请到帐篷里:模型压缩到KB级、低功耗、本地实时,隐私保护。TinyNav就是典型——普通AI百万参数,它却23k却干成大事。ToF为什么优于RGB?因为它直接给距离,像干净指令而非模糊猜谜。为什么小模型能工作?端到端+任务简化:输入输出高度相关,像直觉而非死记物理公式。
这些问题让我反复回味:TinyNav不堆算法,却用朴素思路完成闭环,复现门槛低到人人可试——这才是硬核又接地气的AI福音!
🏆 **龙哥点评:工程范本的闪耀价值**
创新性★★★☆☆:思路巧妙但组合现有技术;实验★★★★☆:完整闭环可信;学术★★★☆☆:工程教育意义大;稳定性★★☆☆☆:训练场景稳但泛化弱;适应性★☆☆☆☆:依赖特定环境;硬件★★★★★:20美元神器;复现★★★★★:代码数据集全开;产品化★☆☆☆☆:原型需优化。但整体,它是“穷玩”机器人的绝佳起点,推动TinyML落地思考。
当我合上这篇论文时,我不由得微笑:传统图片时代结束了,光流与微型大脑的时代,才刚刚开始。TinyNav用23k参数点亮了梦想——下一个微型机器人英雄,或许就在你我手中诞生!
**参考文献**
[1] R. David et al., "Tensorflow lite micro: Embedded machine learning on tinyml systems," arXiv preprint arXiv:2010.08678, 2021.
[2] Espressif Systems, "Esp-nn: Optimised neural network functions for espressif chipsets," GitHub repository, 2026.
[3] A. G. Howard et al., "Mobilenets: Efficient convolutional neural networks for mobile vision applications," arXiv preprint arXiv:1704.04861, 2017.
[4] M. Sandler et al., "Inverted residuals and linear bottlenecks: Mobile networks for classification, detection and segmentation," arXiv preprint arXiv:1801.04381, 2018.
[5] R. R. Selvaraju et al., "Grad-cam: Visual explanations from deep networks via gradient-based localization," arXiv preprint arXiv:1610.02391, 2016.
登录后可参与表态