VLA Models as Supplementary or Alternative Solutions to Gemma 4 for Video Object Detection and Tracking: A Comprehensive Technical Analysis
1. Foundational Positioning: Understanding VLA Design Philosophy and Architectural Constraints
1.1 Core Design Intent vs. Task Requirements
#### 1.1.1 End-to-End Robotic Control as Primary Objective
Vision-Language-Action (VLA) models represent a paradigm shift in embodied artificial intelligence, fundamentally architected to bridge the gap between high-level semantic understanding and low-level physical execution. Unlike conventional computer vision systems that terminate at perception outputs, VLA models are designed to ingest visual observations alongside natural language instructions and directly generate executable action signals for robotic systems—such as end-effector poses, joint configurations, navigation waypoints, or dexterous manipulation sequences. This design philosophy manifests in architectures that prioritize action fidelity, temporal coherence, and cross-modal grounding over the precise spatial localization metrics that dominate traditional object detection and tracking benchmarks.
The robotic control imperative shapes every layer of VLA architecture. From the vision encoder selection to the action head design, components are optimized for tasks such as grasp pose estimation, trajectory planning, and manipulation sequencing. For instance, the π0 model employs flow matching for continuous action generation, achieving control rates of up to 50 Hz—exceptional for robotic control but misaligned with the frame-by-frame annotation requirements of multi-object tracking evaluation protocols. This fundamental orientation means that VLA models excel when the task can be framed as "given what I see and what I'm told, what should I do?" rather than "given this video, where is every instance of class X at every moment?"
#### 1.1.2 Visual-Language-Action Integration Pipeline
The tripartite integration of vision, language, and action in VLA models follows a specific architectural pattern that has become standardized across the field. A vision encoder—typically SigLIP, DINOv2, or a fusion thereof—processes visual input into semantic tokens. These tokens are concatenated with language instruction tokens and fed into a large language model backbone, which performs cross-modal reasoning. The critical distinction from Vision-Language Models (VLMs) like Gemma 4 emerges at the output layer: instead of generating descriptive text, VLA models route the LLM's hidden states to specialized action heads that produce control signals.
This integration pipeline creates a tight coupling between perception and action that is absent in pure detection systems. The language model's reasoning capabilities are harnessed not merely to describe what is seen, but to determine what should be done. In OpenVLA, for example, the 7B-parameter Llama 2 backbone processes fused SigLIP and DINOv2 features alongside instruction tokens, with the resulting representations discretized into 256 action bins for robot control. This architecture enables remarkable generalization—OpenVLA can follow novel instructions involving unseen object categories because the language model's semantic knowledge grounds the action prediction. However, the same architecture complicates extraction of standard detection outputs like bounding boxes with confidence scores and instance IDs.
#### 1.1.3 Inherent Mismatch with Pure Detection-Tracking Optimization
The mismatch between VLA design and traditional multi-object tracking (MOT) requirements is structural rather than incidental. MOT systems are evaluated on metrics such as MOTA (Multiple Object Tracking Accuracy), IDF1 (ID F1-score), and HOTA (Higher Order Tracking Accuracy), all of which depend on explicit, frame-by-frame associations between detected instances and tracked identities. These metrics assume a detection architecture that produces bounding boxes with class probabilities and a tracking architecture that maintains identity states through explicit data association algorithms like the Hungarian method or deep appearance matching.
VLA models, by contrast, typically generate actions through diffusion processes or flow matching, where object states are implicitly encoded in the action trajectory rather than explicitly represented. When a VLA model follows the instruction "track the red object," it may output a sequence of waypoints or joint angles that result in successful following, without ever producing the intermediate representation of "bounding box at (x,y,w,h) with ID=5." This implicit state tracking is sufficient for robotic execution but insufficient for MOT evaluation and many surveillance applications that require audit trails of object locations over time.
The frame rate disparity compounds this mismatch. State-of-the-art MOT systems operate at 30 fps or higher, with lightweight variants achieving 100+ fps on edge hardware. VLA models, constrained by LLM inference and diffusion sampling, typically achieve 1-5 fps for the full perception-action pipeline. While specialized variants like UAV-Track VLA achieve 17.5 fps (0.0571s latency) through architectural optimizations including temporal compression networks, this remains far below real-time MOT requirements. The fundamental tradeoff is between the semantic richness of VLA reasoning and the spatial precision and temporal resolution of specialized trackers.
1.2 Built-in Perceptual Capabilities Relevant to Video Analysis
#### 1.2.1 Object Localization Through Language-Grounded Attention
Despite their action-oriented design, VLA models possess substantial capabilities for object localization that can be leveraged for tracking-adjacent tasks. The vision-language integration in architectures like OpenVLA and the π0 series enables what might be termed "language-grounded attention"—the ability to focus visual processing on regions relevant to a natural language description. This capability emerges from the joint pretraining of vision and language components on large-scale image-text pairs, which teaches the model to associate linguistic concepts with visual features.
In the context of video analysis, language-grounded attention enables flexible target specification that transcends the fixed category sets of traditional detectors. A VLA model can be instructed to "track the person wearing the blue backpack" or "follow the vehicle that just made an illegal turn," leveraging compositional semantic understanding that would require extensive retraining for a conventional detector. The TAG (Target-Agnostic Guidance) framework demonstrates how this attention mechanism can be enhanced: by introducing auxiliary grounding heads that explicitly supervise spatial attention, VLA models can achieve more precise target focusing, with attention maps showing concentrated activation on relevant objects rather than diffused response to distractors.
The practical implication is that VLA models can serve as "smart selectors" within hybrid tracking systems, identifying which of many detections from a fast detector should receive tracking priority based on complex semantic criteria. This role exploits the VLA's strength while circumventing its frame rate limitations—the expensive VLA inference runs infrequently to set or update tracking priorities, while inexpensive traditional tracking maintains frame-by-frame continuity.
#### 1.2.2 Open-Vocabulary Semantic Understanding
Perhaps the most significant advantage of VLA models for video analysis is their open-vocabulary semantic understanding, inherited from their large language model backbones. Traditional object detectors are constrained to a predefined set of categories seen during training; extending to new categories requires data collection, annotation, and retraining. VLA models, by contrast, can recognize and reason about novel object categories, attributes, and relationships described in natural language, enabling zero-shot generalization to unseen scenarios.
This capability is particularly valuable in surveillance and monitoring applications where the set of relevant objects cannot be fully anticipated. A security system based on VLA augmentation could be instructed to "alert if anyone carrying a large package enters the restricted area" without prior training on "large package" detection—the model composes its understanding of "large," "package," and "carrying" from its language model's semantic knowledge. The VOVTrack framework explicitly addresses this open-vocabulary tracking challenge, proposing methods that integrate object states relevant to MOT with video-centric training to handle both seen and unseen categories.
The open-vocabulary advantage extends to fine-grained attribute recognition and relationship understanding. Where a traditional detector might classify an object as "person," a VLA model can infer "person in a hurry," "person looking suspicious," or "person interacting with the target object," enabling more sophisticated behavior analysis. This semantic depth is inaccessible to pure detection pipelines and represents the primary value proposition for VLA integration in intelligent video analysis.
#### 1.2.3 Temporal Reasoning via Multi-Frame Input Support
Modern VLA models incorporate explicit mechanisms for temporal reasoning, addressing a critical requirement for video understanding. Rather than processing frames independently, architectures like TraceVLA introduce "visual trace prompting"—overlaying point trajectories from off-the-shelf trackers (such as Co-tracker) onto the input image to provide spatial memory of historical motion. This approach compresses temporal information into a compact visual representation that guides the model's reasoning without requiring expensive processing of raw video sequences.
The temporal compression network in UAV-Track VLA exemplifies more sophisticated approaches: historical frames are processed through a linear projection that reduces 256 visual tokens per frame to 64 tokens, with learnable positional encoding capturing temporal dependencies. This enables the model to maintain awareness of object motion patterns over time, supporting predictions that account for velocity, acceleration, and likely future positions. For tracking applications, such temporal reasoning enables re-identification after occlusion and prediction of object trajectories during temporary disappearance.
However, the temporal support in most VLA models is optimized for action prediction horizons (typically 10-50 future steps for robot control) rather than the long-term identity maintenance required for MOT (hundreds to thousands of frames). The TrackVLA++ architecture addresses this limitation through its Target Identification Memory (TIM) module, which maintains compact token representations of tracked objects across extended sequences, achieving sustained tracking for over 30 minutes in complex urban environments. This represents a significant advance toward VLA-based long-term tracking, though still within embodied navigation contexts rather than pure surveillance.
#### 1.2.4 Implicit State Tracking Through Action Sequence Generation
The most distinctive temporal capability of VLA models is implicit state tracking through action sequence generation. When a VLA model generates a trajectory of waypoints or joint angles to follow a moving target, the sequence inherently encodes predictions about the target's future states. A smooth approach trajectory implies confidence in the target's current location and predicted motion; hesitation or replanning signals uncertainty or target loss. This implicit tracking is functionally equivalent to maintaining a Kalman filter or particle filter state estimate, but expressed in the action space rather than explicitly parameterized.
The diffusion and flow matching action heads prevalent in modern VLAs (π0, π0.5, GR00T N1, TrackVLA) generate action sequences through iterative refinement or direct regression, with the resulting trajectories naturally smoothing over temporary perception failures. This robustness to transient occlusion or noise exceeds what simple detection-based trackers can achieve without explicit motion models. The tradeoff is opacity: the implicit state is not directly inspectable, complicating debugging and accountability in safety-critical applications.
For hybrid tracking systems, implicit VLA tracking can complement explicit traditional tracking by providing "semantic motion priors"—predictions of where interesting objects are likely to move based on goal-directed behavior. When the VLA infers that a tracked person is "heading toward the exit," this prediction can guide the traditional tracker's search region after occlusion, improving re-acquisition speed and accuracy.
1.3 Fundamental Limitations for MOT Tasks
#### 1.3.1 Frame Rate Constraints (~1 fps Without Lightweight Variants)
The computational cost of VLA inference creates a severe frame rate bottleneck for real-time video analysis. Full-scale models like OpenVLA (7B parameters) or π0.5 achieve inference rates of approximately 1-5 frames per second on consumer GPUs, with latency dominated by LLM forward passes and diffusion sampling iterations. This is orders of magnitude below the 30+ fps standard for real-time MOT and the 100+ fps achievable with optimized YOLO+ByteTrack pipelines.
The frame rate limitation is not merely a hardware scaling issue but reflects fundamental architectural choices. Autoregressive language model inference has inherent sequential dependencies that resist parallelization; diffusion sampling requires multiple denoising steps per action generation. While optimizations such as speculative decoding, quantization, and distilled student models offer incremental improvements, order-of-magnitude speedups require architectural innovation.
Lightweight variants provide partial relief. SmolVLA achieves "medium-to-high" real-time performance through parameter reduction, though specific fps figures are not widely reported. UAV-Track VLA's 17.5 fps represents the state-of-the-art for task-specific VLA optimization, achieved through temporal compression networks that reduce per-frame token counts by 75% (from 256 to 64 tokens per historical frame) and parallel dual-branch decoders that decouple spatial grounding from action generation. Even this optimized performance, however, remains below unconstrained MOT requirements, reinforcing the necessity of hybrid architectures for real-time applications.
#### 1.3.2 Absence of Explicit Bounding Box + ID Output Mechanisms
The output representation of VLA models fundamentally differs from MOT requirements. Standard MOT evaluation assumes frame-by-frame outputs of the form (frame_id, object_id, bbox_x, bbox_y, bbox_w, bbox_h, confidence, class), enabling precise measurement of detection accuracy, identity preservation, and trajectory continuity. VLA models, by contrast, typically output continuous action vectors (joint angles, end-effector poses, waypoint coordinates) or discrete action tokens, with no direct mapping to bounding box coordinates.
Extracting detection-compatible outputs from VLA models requires additional processing that is neither standardized nor officially supported. Potential approaches include: (1) projecting attention maps to spatial coordinates, (2) training auxiliary detection heads on frozen VLA features, or (3) prompting the model to generate bounding box descriptions in natural language for subsequent parsing. Each approach introduces latency, error modes, and training complexity that erode the VLA's advantages.
The TrackVLA architecture partially addresses this gap by supporting dual output modes: trajectory waypoints for robot control and text-based responses for recognition queries. This design enables explicit object identification ("the target is a red sedan") alongside implicit tracking through waypoint sequences. However, the text output remains at the level of semantic description rather than precise spatial coordinates, limiting compatibility with standard MOT tooling.
#### 1.3.3 Diffusion/Flow-Matching Output vs. Detection-Specific Architectures
The generative action heads that enable VLA models' smooth, goal-directed behavior are poorly suited to the discriminative task of object detection. Diffusion models and flow matching optimize for trajectory likelihood under a learned distribution, producing outputs that are plausible and smooth but not necessarily maximally accurate at each instant. Detection architectures, by contrast, are trained to maximize classification accuracy and localization precision at each frame independently, with explicit supervision on bounding box coordinates.
This architectural divergence creates systematic differences in error characteristics. Diffusion-based VLA outputs tend to exhibit temporal smoothing that suppresses high-frequency jitter but may lag behind sudden motion changes. Detection outputs preserve frame-by-frame independence, capturing rapid movements accurately but producing noisier trajectories without post-processing. For applications requiring both responsiveness and smoothness, the optimal solution may combine both: fast detection for initial response, VLA-based prediction for smoothing and gap-filling.
The Mantis framework proposes an intriguing hybrid approach, disentangling visual foresight prediction from the VLA backbone through a dedicated diffusion transformer head with meta queries. This architecture explicitly separates "what will happen" (visual prediction) from "what should I do" (action generation), potentially enabling extraction of predicted object states without full action generation. Such architectural innovations may eventually bridge the gap between VLA and MOT requirements, but current implementations remain research-grade rather than production-ready.
---
2. Comparative Model Analysis: Seven Leading VLA Candidates (April 2026)
| 模型 | 参数量 | 开源情况 | 视频/检测能力亮点 | 适合视频物体检测+追踪? | 实时性(视频) | 推荐程度(针对特定场景) |
|---|---|---|---|---|---|---|
| OpenVLA | 7B | 完全开源 (HF) | 强开放词汇感知,多帧机器人视频训练,内置定位 | 中等(感知强,可做追踪辅助) | 低~中 | 高(易上手,推荐起步) |
| π0 / π0.5 | ~2B~7B | 部分开源 | 优秀开放世界泛化,视频演示数据丰富,空间推理强 | 中高(多目标场景好) | 中 | 高(通用性强) |
| Gemini Robotics | 大模型 | 部分(On-Device 版轻量) | 基于 Gemini 2.0,多视频帧处理,dexterous 任务强 | 高(视频理解+动作) | 中(On-Device 更好) | 中高(Google 生态) |
| GR00T N1 | - | 部分开源 | 人形机器人视频+合成数据,泛化强 | 中高(感知+动作) | 中 | 中(硬件偏向) |
| Helix | - | 闭源为主 | 双系统(System 1/2),全身控制,视频规划强 | 中 | 中 | 中(商用机器人) |
| SmolVLA | 小模型 | 开源 | 紧凑高效,适合边缘设备 | 中 | 中高 | 高(如果要轻量部署) |
| ChatVLA-2 | MoE | 研究级 | 开放世界推理、数学/OCR 强 | 中高(带推理的追踪) | 低 | 中(原型/复杂场景) |
2.1 OpenVLA: The Open-Source Baseline
#### 2.1.1 Architecture Specifications
##### 2.1.1.1 Dual Vision Encoder Design (SigLIP + DINOv2 Fusion)
OpenVLA's visual perception foundation rests on a sophisticated dual-encoder architecture that combines complementary strengths of two leading vision models. SigLIP (Sigmoid Loss for Language Image Pre-training) provides semantic alignment between visual and linguistic representations, enabling effective grounding of natural language instructions in visual content. DINOv2 (Self-DIstillation with NO labels, version 2) contributes robust visual features trained through self-supervised learning on diverse unlabeled images, with particular strength in geometric understanding and spatial reasoning.
The fusion of these encoders follows the Prismatic VLM design: SigLIP and DINOv2 process input images independently, with their output features concatenated and projected to a unified token space. This dual-stream approach yields 256 visual tokens per image that capture both semantic (SigLIP) and geometric (DINOv2) information, providing a richer representation than either encoder alone. For video applications, this design enables robust performance across diverse visual conditions: SigLIP's semantic features maintain recognition under appearance variation, while DINOv2's geometric features support accurate spatial localization.
The practical significance for tracking-adjacent tasks is substantial. When instructed to "track the person in the red shirt," OpenVLA can leverage SigLIP for color and category recognition while using DINOv2 for precise spatial extent estimation. The fusion mechanism enables graceful degradation: if lighting conditions degrade color information, geometric features from DINOv2 can maintain tracking based on shape and motion; if viewpoint changes alter apparent shape, semantic features preserve category and attribute recognition.
##### 2.1.1.2 Llama 2 7B Language Backbone
The language reasoning component of OpenVLA builds upon Llama 2 7B, a widely-adopted open-source large language model. This choice provides several advantages: extensive pretraining on diverse text corpora yielding broad world knowledge; well-understood fine-tuning behaviors and optimization techniques; and compatibility with efficient inference implementations including quantization, speculative decoding, and vLLM serving. The 7B parameter scale represents a deliberate balance—sufficient capacity for complex reasoning and instruction following, yet tractable for deployment on consumer hardware with appropriate optimization.
The Llama 2 backbone processes concatenated visual and language tokens through standard transformer layers, with cross-modal attention enabling information flow between visual and linguistic representations. For video applications, the autoregressive nature of Llama 2 enables natural extension to temporal sequences: previous frame tokens can be cached and extended with new visual observations, though this is not the primary training regime for OpenVLA. The 4096-token context window (standard for Llama 2) accommodates multiple image frames with appropriate compression, supporting limited temporal reasoning.
The language backbone's role in tracking tasks is primarily semantic: parsing complex instructions, maintaining task context across interactions, and generating explanatory outputs. When OpenVLA is prompted with "track the vehicle that made the illegal turn," Llama 2's reasoning capabilities enable interpretation of "illegal turn" in context, identification of the relevant vehicle from multiple candidates, and maintenance of this target specification across subsequent frames. This semantic scaffolding exceeds the capabilities of pure detection systems but operates at a higher level of abstraction than pixel-precise tracking.
##### 2.1.1.3 Action Tokenization via 256-Bin Discretization
OpenVLA's action output employs a straightforward yet effective discretization strategy: continuous action dimensions (typically 7-14 DOF for robot arms, or 2-3 for mobile base) are uniformly binned into 256 discrete values per dimension, with the language model trained to predict the appropriate bin indices as special tokens. This approach, inherited from RT-1 and RT-2, transforms action generation into a token prediction problem compatible with standard language model training objectives.
The 256-bin resolution provides approximately 0.4% precision relative to each action dimension's range, sufficient for most manipulation tasks but potentially limiting for precise tracking applications. For video analysis repurposing, the action output is typically ignored or reinterpreted: rather than commanding a robot, the model's internal representations (attention maps, hidden states) are extracted for downstream processing, or the model is prompted to generate descriptive text about object locations.
The discretization strategy's primary advantage is training stability and data efficiency. By reducing the output space from continuous regression to categorical prediction, OpenVLA can leverage standard cross-entropy losses and benefit from the regularization effects of softmax normalization. The cost is reduced precision for fine-grained control and potential quantization artifacts at bin boundaries. Alternative approaches in the VLA space, particularly flow matching in π0 and diffusion in various models, offer smoother continuous outputs at the cost of increased inference complexity.
#### 2.1.2 Training Regime and Data Scale
##### 2.1.2.1 970K+ Robot Trajectories from Open X-Embodiment
OpenVLA's training data comprises over 970,000 robot trajectories from the Open X-Embodiment dataset, a large-scale aggregation of robotic demonstration data across multiple institutions, robot platforms, and task domains. This dataset diversity is critical for generalization: models trained on single-robot, single-environment data typically fail when deployed elsewhere, while OpenVLA's broad training enables zero-shot transfer to new robots and tasks with minimal adaptation.
The trajectory format includes: RGB observations (typically single or limited multi-view), natural language task descriptions, and action sequences (joint positions, gripper states, base velocities). For video-relevant capabilities, the key insight is that "following a moving object" is a common subtask across many demonstrations—whether reaching for a moving target, tracking a human demonstrator, or coordinating with other robots. This implicit tracking supervision is weaker than explicit MOT annotations but more diverse in scenarios and object categories.
The scale of 970K+ trajectories substantially exceeds most prior VLA training efforts, enabling the 7B parameter model to achieve performance competitive with larger proprietary systems. Data quality varies across sources, with filtering and weighting strategies applied to prioritize reliable demonstrations. The resulting model exhibits robust behavior in cluttered, dynamic scenes with multiple moving objects—capabilities that transfer to video analysis even without explicit tracking training.
##### 2.1.2.2 Prismatic-7B VLM Initialization with Task-Specific Fine-Tuning
OpenVLA's training follows a two-stage protocol: initialization from a pretrained vision-language model (Prismatic-7B), followed by task-specific fine-tuning on robotic data. This approach leverages the substantial investment in VLM pretraining—Prismatic-7B was trained on diverse image-text pairs enabling broad visual-linguistic understanding—while adapting the model's outputs for action generation.
The VLM initialization provides crucial capabilities for video analysis: object recognition, attribute understanding, spatial relationship reasoning, and natural language following. Fine-tuning on robotic data then grounds these capabilities in physical action, teaching the model to connect "what I see" and "what I'm told" to "what I should do." For tracking applications, this grounding enables interpretation of instructions like "follow that person" as actionable behavior, though the specific action format (joint angles, velocities) may require reinterpretation.
The fine-tuning process employs standard supervised learning on demonstration trajectories, with action prediction cross-entropy loss and optional auxiliary objectives. LoRA (Low-Rank Adaptation) fine-tuning is supported for domain-specific adaptation, enabling efficient specialization to particular object categories, environments, or output formats without full model retraining. This adaptability is valuable for tracking deployments where the target domain differs from generic robotic scenarios.
#### 2.1.3 Performance Profile for Video Tasks
##### 2.1.3.1 Superior Spatial Reasoning via DINOv2 Geometric Features
OpenVLA's DINOv2-based visual features provide exceptional spatial reasoning capabilities that benefit tracking-adjacent tasks. DINOv2's self-supervised pretraining on diverse images yields features with strong geometric properties: preserved relative distances, robustness to viewpoint changes, and emergent part-level understanding. These properties enable accurate depth estimation, surface normal prediction, and 3D-aware reasoning without explicit 3D supervision.
For video analysis, DINOv2 features support: (1) accurate size and distance estimation, enabling tracking based on physical scale rather than apparent image size; (2) viewpoint-invariant recognition, maintaining target identity across camera movements; and (3) part-level understanding, enabling tracking of specific object components (e.g., "the person's left hand") rather than coarse bounding boxes. The fusion with SigLIP semantic features combines this geometric precision with categorical and attribute recognition, providing a comprehensive visual representation.
Empirical evaluation on spatial reasoning benchmarks shows DINOv2-based models outperforming pure CLIP-based alternatives on tasks requiring metric spatial understanding. For tracking applications, this translates to more accurate motion prediction and better handling of scale changes due to approach or retreat. The limitation is computational cost: DINOv2's vision transformer architecture, while efficient, adds inference overhead compared to simpler encoders.
##### 2.1.3.2 Moderate Suitability for Detection-Tracking Hybrid Workflows
OpenVLA's suitability for hybrid tracking workflows is moderate—strong in semantic capabilities, limited in frame rate and explicit output format. The recommended integration pattern leverages OpenVLA as an intermittent "semantic supervisor": running every 5-10 frames to verify and refine tracking targets identified by a fast detector, rather than as a primary tracking engine. This role exploits OpenVLA's strengths (open-vocabulary recognition, complex instruction following, multi-frame reasoning) while circumventing its limitations (speed, explicit bounding box output).
Specific hybrid applications include: (1) target re-identification after long occlusion, where OpenVLA's semantic understanding can verify whether a re-detected object matches the original target description; (2) behavior-based alert generation, where complex conditions ("person loitering near the vehicle for more than 5 minutes") require semantic interpretation beyond pure motion analysis; and (3) tracking initialization with complex natural language queries that exceed detector category vocabularies.
The moderate suitability reflects architectural constraints rather than fundamental incapability. With appropriate output heads and training, OpenVLA's features could support more direct tracking integration; current implementations prioritize robotic control over such extensions. Community adaptations and fine-tuning projects may expand these capabilities, but production deployment currently requires careful architectural design to work within OpenVLA's strengths.
##### 2.1.3.3 Low-to-Medium Real-Time Video Throughput
OpenVLA's inference throughput of approximately 1-2 fps on consumer GPUs (NVIDIA RTX 4090) places it in the "low-to-medium" category for real-time video applications. This is sufficient for tasks where semantic decisions occur at human-relevant timescales (seconds) rather than frame-relevant timescales (milliseconds), but insufficient for smooth visual tracking or rapid response to fast-moving objects.
Throughput optimization strategies include: (1) quantization to INT8 or INT4 precision, reducing memory bandwidth and enabling faster matrix operations; (2) speculative decoding with smaller draft models; (3) batch processing of multiple video streams; and (4) edge caching of visual features for static backgrounds. These optimizations can potentially achieve 5-10 fps, approaching the lower bound of real-time applicability, but fundamental architectural limits remain.
For comparison, specialized MOT systems achieve 30-100+ fps on equivalent hardware, with YOLO-World (open-vocabulary detector) reaching 50+ fps. The 10-50× speed difference reinforces the hybrid architecture imperative: OpenVLA's value lies in semantic depth, not raw throughput.
#### 2.1.4 Deployment Accessibility
##### 2.1.4.1 Full Hugging Face Availability
OpenVLA's complete availability on Hugging Face—model weights, inference code, training scripts, and documentation—represents exceptional accessibility in the VLA landscape. This open distribution enables: immediate experimentation without institutional access or approval; community-driven improvements and adaptations; educational use and research reproducibility; and commercial deployment without licensing uncertainty.
The Hugging Face integration includes transformers-compatible model classes, enabling straightforward loading and inference:
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained("openvla/openvla-7b")
processor = AutoProcessor.from_pretrained("openvla/openvla-7b")
This standard interface lowers barriers to entry for practitioners familiar with Hugging Face ecosystems, though VLA-specific considerations (action space configuration, robot embodiment specification) require additional domain knowledge.
##### 2.1.4.2 LoRA Adaptation for Consumer-Grade Hardware
OpenVLA supports efficient fine-tuning via LoRA, enabling adaptation to specific tracking scenarios without full model retraining. Typical LoRA configurations (rank 16-64, targeting attention and MLP layers) reduce trainable parameters to <1% of total, enabling fine-tuning on consumer GPUs with 16-24GB VRAM. This accessibility is critical for domain-specific deployment: a surveillance system can be fine-tuned on facility-specific object categories and camera viewpoints without datacenter-scale resources.
Reported LoRA applications include: adaptation to specific robot embodiments with different action spaces; fine-tuning on human demonstration videos for imitation learning; and instruction-following enhancement for particular task domains. For tracking adaptation, potential fine-tuning objectives include: bounding box regression from frozen features; temporal consistency prediction; and natural language description of object trajectories. These adaptations remain research explorations rather than established practices, reflecting the novelty of VLA repurposing for pure video analysis.
2.2 π0 / π0.5 Series: Open-World Generalization Leaders
#### 2.2.1 Architectural Evolution from π0 to π0.5
##### 2.2.1.1 Enhanced Vision-Language Backbone Integration
The π0 series from Physical Intelligence represents a significant architectural evolution in VLA design, with π0.5 introducing substantial enhancements over the original π0 foundation. Both models build upon PaliGemma—a vision-language model combining SigLIP vision encoding with Gemma language processing—but π0.5 extends this foundation with more sophisticated multimodal integration and expanded training data.
The core innovation in π0 is flow matching for continuous action generation, replacing the discrete tokenization used in models like OpenVLA. Flow matching directly regresses action trajectories in continuous space, enabling smoother, more physically plausible motions and higher effective control rates (up to 50 Hz). This continuous representation is particularly advantageous for tracking applications where smooth pursuit trajectories are desired: the flow-matched output naturally interpolates between waypoints, reducing jitter that might arise from independent discrete predictions.
π0.5 enhances this foundation through improved vision-language alignment and expanded training on video demonstration data. The model processes longer temporal contexts, with better maintenance of object identity across extended sequences. Architectural specifics remain partially undisclosed (π0.5 is not fully open-source), but reported capabilities suggest significant advances in handling complex multi-object scenes and extended temporal reasoning.
##### 2.2.1.2 Video Demonstration Data Utilization
A distinctive aspect of π0/π0.5 training is heavy utilization of video demonstration data—human videos of manipulation tasks, not just robot trajectories. This enables learning from the vast reservoir of human skill demonstration available online, rather than being limited to expensive robot-collected data. The video understanding capabilities developed through this training transfer directly to tracking-relevant skills: observing how humans visually track and intercept moving objects, predicting object motion from visual cues, and coordinating hand-eye movements for dynamic grasping.
The video training regime develops implicit models of physical dynamics that support prediction and tracking. When π0.5 generates a trajectory to catch a thrown ball, it must predict the ball's future position based on observed motion—equivalent to tracking with physical reasoning. This capability, learned from diverse human videos, generalizes to novel objects and motion patterns, providing robustness that pure data-association trackers lack.
The limitation is that video-trained dynamics models may not match the precision of physics simulators or analytical motion models for specific object categories. π0.5's predictions are "reasonable" rather than "optimal," prioritizing generalization over specialized accuracy. For tracking applications, this suggests complementary use: π0.5 for semantic guidance and rough motion prediction, specialized trackers for precise frame-by-frame localization.
#### 2.2.2 Spatial-Temporal Reasoning Strengths
##### 2.2.2.1 Multi-Object Dynamic Scene Handling
π0.5 demonstrates exceptional capability in scenes with multiple moving objects, where tracking requires maintaining identity distinctions and predicting interactions. The model's attention mechanisms can selectively focus on task-relevant objects while maintaining awareness of distractors, enabling robust performance in cluttered environments. This selectivity is learned from diverse training scenarios where correct action requires appropriate attention allocation.
For video analysis, multi-object handling enables applications such as: tracking a specific individual through a crowd; monitoring interactions between multiple vehicles; and detecting anomalous behavior based on deviation from predicted multi-agent dynamics. The model's outputs implicitly encode which objects are being tracked and how their motions relate, though explicit multi-track output formats are not standard.
The TAG framework's comparison with π0.5 illustrates both the capability and limitation: without target-agnostic guidance, π0.5's attention can become diffused across multiple similar objects, leading to tracking failures; with appropriate guidance mechanisms, the underlying spatial-temporal reasoning enables precise target maintenance. This suggests that π0.5's core capabilities are strong but require appropriate interfaces for reliable tracking extraction.
##### 2.2.2.2 Zero-Shot Generalization to Unseen Objects
π0.5's training on diverse video data enables remarkable zero-shot generalization to object categories and motion patterns not seen during training. This contrasts with traditional trackers that typically require training data matching target categories, and even with open-vocabulary detectors that may struggle with extreme appearance variations. π0.5 can follow instructions like "track the object that the person just threw" for novel object shapes and motion dynamics, leveraging general physical reasoning rather than category-specific models.
The generalization mechanism combines: visual feature robustness from diverse pretraining; language-mediated task specification that transcends fixed categories; and learned physical dynamics that apply broadly to rigid and articulated objects. For deployment, this reduces preparation requirements—new object categories can be specified linguistically without model retraining or data collection.
Empirical validation of this generalization comes from benchmark performance on unseen environments. UAV-Track VLA, built on π0.5 architecture, maintains 55% success rate on pedestrian tracking in entirely unseen maps, compared to π0.5's 5.88% without architectural enhancements. This dramatic improvement through task-specific adaptation suggests that π0.5's base capabilities are strong but benefit from appropriate architectural scaffolding for tracking applications.
#### 2.2.3 Empirical Performance Evidence
##### 2.2.3.1 UAV-Track VLA Benchmark Results (Unseen Map SR/ATF Metrics)
The UAV-Track VLA model provides the most direct empirical evidence of π0.5-architecture performance for tracking tasks. Built explicitly for embodied aerial tracking, this model introduces temporal compression networks and spatial-aware auxiliary grounding heads to address base π0.5's limitations, while retaining its core strengths.
Quantitative results on the UAV-Track benchmark demonstrate:
| Metric | Scenario | UAV-Track VLA | π0.5 Baseline | Improvement |
|---|---|---|---|---|
| Success Rate (SR) | Pedestrian, Far distance, unseen maps | 55.00% | 5.88% | 9.35× |
| Average Tracking Frames (ATF) | Pedestrian, Far distance, unseen maps | 226.90 | ~100 (est.) | >2× |
| Success Rate (SR) | Vehicle, Far distance, unseen maps | 37.88% | ~20% (est.) | ~1.9× |
| Inference Latency | All scenarios | 0.0571s (17.5 fps) | ~0.086s (11.6 fps) | 33.4% reduction |
##### 2.2.3.2 Significant Outperformance Over π0 Baseline
Comparative evaluation against the original π0 model shows consistent advantages for π0.5, validating the architectural evolution. While direct tracking benchmarks for base π0/π0.5 are limited, robotic manipulation benchmarks show π0.5 achieving higher success rates on complex, multi-step tasks requiring extended temporal reasoning. The flow matching foundation is preserved, with improvements in vision-language integration and training data scale.
For tracking applications, the π0 to π0.5 evolution suggests: better maintenance of target identity over extended sequences; improved handling of temporary occlusion and re-emergence; and more robust performance under appearance changes and viewpoint variation. These are precisely the capabilities that distinguish capable tracking systems, suggesting π0.5 as a strong candidate for VLA-based tracking when architectural access is available.
#### 2.2.4 Partial Open-Source Availability and Community Ecosystem
π0's base architecture and training approach are documented in research publications with accompanying code, enabling community replication and extension. π0.5 represents a more advanced but less completely disclosed system, with performance claims and limited architectural description without full implementation availability. This partial openness creates a tradeoff: practitioners can build π0-class systems independently, but access to state-of-the-art π0.5 capabilities may require collaboration with Physical Intelligence or independent replication of reported techniques.
The community ecosystem around π0 includes: open-source reimplementations and training code; adaptation to diverse robot platforms; and integration with broader robotics frameworks like ROS 2. For tracking applications, community contributions might develop: output interfaces for detection-compatible formats; training protocols on tracking-specific data; and efficiency optimizations for video-only deployment (without robot action generation). These developments remain speculative given the current robotics focus of the ecosystem.
2.3 Gemini Robotics: Google Ecosystem Integration
#### 2.3.1 Gemini 2.0 Foundation and Multi-Frame Video Processing
Gemini Robotics builds upon Google's Gemini 2.0 foundation model, extending the Gemini family's multimodal capabilities into embodied action generation. The Gemini 2.0 base provides exceptional language understanding, code generation, and structured output capabilities, with vision processing supporting high-resolution image and video inputs. For video specifically, Gemini 2.0's native multi-frame processing enables temporal reasoning without architectural additions, distinguishing it from VLA models that process frames independently or require explicit temporal mechanisms.
The multi-frame video support in Gemini 2.0, and by extension Gemini Robotics, enables: native understanding of motion and temporal relationships; implicit tracking through frame-to-frame feature correspondence; and generation of video descriptions that capture dynamic events. These capabilities are foundational for tracking applications, though the model's outputs remain primarily linguistic rather than spatial.
Gemini Robotics extends this foundation with action generation capabilities, though specific architectural details are less disclosed than for open alternatives. The integration with Google's broader AI ecosystem—including Cloud TPUs, Vertex AI deployment, and Android/Chrome device integration—provides deployment advantages for organizations already committed to Google infrastructure.
#### 2.3.2 Dexterous Task Specialization and Fine-Grained Manipulation
A distinctive focus of Gemini Robotics is dexterous manipulation—tasks requiring precise finger and hand control, such as folding paper, threading needles, or handling delicate objects. This specialization develops fine-grained visual-motor coordination that transfers to precise tracking: the same capabilities that enable grasping a small object enable maintaining visual fixation on small, fast-moving targets.
The dexterous focus is reflected in training data and evaluation protocols emphasizing high-DOF hand control, with reported capabilities exceeding prior systems on benchmark manipulation tasks. For video analysis, this suggests particular strength in: tracking small objects or object parts; maintaining fixation during rapid, unpredictable motion; and coordinating tracking with fine-grained action decisions.
The limitation is that dexterous manipulation training may not optimize for the extended temporal horizons typical of surveillance tracking. Manipulation episodes are typically seconds to minutes; surveillance tracking may require hours of continuous operation. Whether Gemini Robotics' capabilities scale to such extended durations without degradation remains to be empirically validated.
#### 2.3.3 On-Device Lightweight Variant for Edge Deployment
Google's announcement of an On-Device variant of Gemini Robotics addresses the deployment accessibility critical for many tracking applications. Edge execution enables: reduced latency by avoiding network round-trips; operation in connectivity-limited environments; and enhanced privacy by keeping video data local. The On-Device variant reportedly maintains core capabilities while achieving substantially improved efficiency through quantization, pruning, and neural architecture search optimization.
Specific performance figures for the On-Device variant are not widely disclosed, but the pattern from other Google edge models (Gemini Nano, MobileNet) suggests 10-100× efficiency improvement over cloud variants with modest capability reduction. For tracking applications, this may enable frame rates approaching real-time requirements, though likely still below specialized trackers.
The On-Device variant's integration with Android and potential specialized hardware (Tensor G4 and beyond) creates ecosystem lock-in advantages and risks: optimal performance requires Google-aligned devices, limiting deployment flexibility; but seamless integration with Google's mobile and IoT platforms simplifies development for that ecosystem.
#### 2.3.4 Medium Real-Time Performance with Google Stack Dependencies
Gemini Robotics' real-time performance is characterized as "medium"—better than unoptimized large models, but not competitive with specialized trackers. The cloud variant's latency is dominated by network transmission and large-model inference, suitable for batch or near-real-time applications but not frame-critical tracking. The On-Device variant improves this substantially, potentially achieving multiple fps, but remains within "medium" characterization.
The Google stack dependencies create both advantages and constraints. Integration with Google Cloud enables scalable deployment, automatic scaling, and managed infrastructure; but also creates vendor lock-in, data residency complications, and potential service discontinuation risks. For organizations with existing Google commitments, these are acceptable tradeoffs; for others, open alternatives may be preferable.
2.4 Hardware-Aligned Alternatives
#### 2.4.1 GR00T N1 (NVIDIA): Humanoid-Centric Synthetic Data Training
##### 2.4.1.1 Hardware-Software Co-Design with NVIDIA Robotics Stack
GR00T N1 represents NVIDIA's entry into foundation models for humanoid robotics, with explicit hardware-software co-design optimizing for NVIDIA's robotics platform. The model architecture combines a VLM backbone with a diffusion transformer action head, with cross-attention from the diffusion transformer to VLM tokens enabling information flow between high-level understanding and low-level control. This design pattern, shared with several contemporary VLAs, is implemented with NVIDIA-specific optimizations for TensorRT inference and Isaac Sim training.
The hardware alignment extends to training infrastructure: GR00T N1 is trained on massive synthetic data generated in NVIDIA Isaac Sim, with physics-based simulation enabling diverse scenario coverage impossible with real-world collection. This synthetic training develops robust visual-motor policies that transfer to physical deployment, with the simulation-to-reality gap addressed through domain randomization and adaptation techniques.
For tracking applications, the NVIDIA stack integration provides: optimized inference on NVIDIA GPUs, from edge Jetson devices to datacenter A100/H100 clusters; seamless simulation-based testing and validation; and integration with broader NVIDIA robotics tooling (Isaac ROS, cuMotion planning). These advantages are substantial for organizations with NVIDIA infrastructure, but create ecosystem dependencies similar to Google's.
##### 2.4.1.2 Perception-Action Coupling for Bimanual Manipulation
GR00T N1's training emphasizes bimanual manipulation—coordinated two-hand actions requiring sophisticated spatial reasoning and temporal coordination. This develops capabilities relevant to multi-object tracking: maintaining awareness of multiple objects simultaneously; predicting interactions between manipulated objects; and coordinating attention between task-relevant targets. The bimanual focus is more complex than typical single-arm manipulation, suggesting stronger general spatial reasoning.
The perception-action coupling in GR00T N1 is tight, with visual features directly informing action generation without intermediate symbolic representation. This enables fast, reactive behavior but complicates extraction of explicit tracking outputs. For hybrid tracking systems, GR00T N1 might serve as a "physical validator"—confirming that tracked object motions are physically plausible and predicting likely future trajectories based on learned dynamics.
#### 2.4.2 Helix (Figure AI): Dual-System Architecture
##### 2.4.2.1 System 1/2 Separation for Reactive vs. Deliberative Control
Helix from Figure AI introduces an explicit dual-system architecture inspired by cognitive science's distinction between fast, automatic processing (System 1) and slow, deliberative reasoning (System 2). In Helix, System 1 provides fast, reactive motor responses for immediate environmental demands; System 2 performs slower, planning-based reasoning for complex goal achievement. This separation enables both responsiveness and sophistication, addressing a fundamental tension in embodied AI.
For tracking applications, the dual-system design suggests natural mapping: System 1 for immediate target following, maintaining fixation and basic motion prediction; System 2 for target re-identification after occlusion, behavior understanding, and task-level planning. The explicit architectural separation may enable more reliable extraction of tracking-relevant information from System 2's deliberative outputs, compared to monolithic models where such information is implicit.
The System 1/2 separation also enables graceful degradation: if System 2 is overloaded or unavailable, System 1 maintains basic functionality. For surveillance applications, this suggests robust operation under resource constraints, with full capabilities available when computational resources permit.
##### 2.4.2.2 Full-Body Motion Planning with Video Context
Helix's scope extends beyond manipulation to full-body humanoid control—walking, balancing, whole-body coordination. This develops capabilities for egocentric tracking, where the camera moves with the robot and tracking must account for self-motion. The video context for Helix includes both external scene understanding and proprioceptive state awareness, enabling tracking that integrates target motion with self-motion prediction.
The full-body focus is less directly relevant to fixed-camera surveillance tracking but highly relevant to mobile robot applications where the tracking system moves through the environment. For such applications, Helix's integrated approach to perception, planning, and control may outperform decoupled tracking-plus-planning systems.
##### 2.4.2.3 Closed-Source Commercial Deployment Focus
Helix is primarily closed-source, with deployment through Figure AI's commercial humanoid robot platform rather than open research access. This limits independent validation and adaptation but ensures integrated, tested, and supported deployment for commercial customers. The closed-source model reflects Figure AI's business strategy of vertical integration—developing both the AI and the physical platform for specific high-value applications.
For tracking practitioners, Helix's accessibility is limited to: partnership with Figure AI for specific deployments; indirect influence through published research describing architectural approaches; and potential future API or platform access. This restricts Helix's role in broad tracking research and development, though commercial deployments may demonstrate capabilities that inform open alternatives.
2.5 Efficiency-Optimized Variants
#### 2.5.1 SmolVLA: Edge-First Compact Architecture
##### 2.5.1.1 Parameter Reduction Without Core Capability Sacrifice
SmolVLA represents a deliberate design for efficiency, reducing model scale while preserving the core VLA capabilities that enable generalization and instruction following. The specific parameter count is not widely reported, but "small model" characterization suggests <1B parameters, potentially 100M-500M range—an order of magnitude reduction from OpenVLA's 7B. This reduction enables deployment on resource-constrained edge devices: smartphones, embedded cameras, IoT processors.
The parameter reduction strategy likely employs: smaller language model backbones (Phi-1.5, TinyLlama, or custom); reduced vision encoder resolution and layer count; and efficient action head designs (potentially direct regression rather than diffusion). The specific tradeoffs between efficiency and capability are not fully documented, but the model's characterization as suitable for "edge devices" with "medium-to-high" real-time performance suggests successful preservation of core functionality.
For tracking applications, SmolVLA's efficiency enables: direct deployment on camera-edge devices, reducing bandwidth and latency; operation in power-constrained environments; and lower hardware costs for large-scale deployment. The capability sacrifice relative to larger models is acceptable when the VLA serves as semantic supervisor rather than primary tracker, with fast traditional tracking handling frame-by-frame demands.
##### 2.5.1.2 Medium-to-High Real-Time Video Suitability
SmolVLA's "medium-to-high" real-time characterization, combined with edge deployment focus, suggests frame rates of 5-15 fps—substantially better than larger alternatives, though still below specialized trackers. This performance level enables: more responsive semantic supervision of tracking; reduced latency for alert generation; and smoother visualization of VLA-guided attention.
The "medium-to-high" range reflects deployment-dependent variation: optimal performance on specialized accelerators (NPUs, TPUs), reduced performance on general CPUs. Practitioners should validate specific deployment targets against requirements, as real-world performance varies considerably with hardware platform and optimization effort.
##### 2.5.1.3 Primary Recommendation for Resource-Constrained Deployment
Given its efficiency-performance tradeoff profile, SmolVLA emerges as the primary recommendation for deployment scenarios with significant resource constraints. Edge devices, embedded systems, and battery-powered platforms that cannot accommodate full-scale VLA inference may nevertheless achieve useful VLA functionality through SmolVLA deployment.
The specific deployment recommendations depend on precise capability requirements and available hardware, with empirical evaluation advised to confirm suitability for specific tracking applications. The open-source availability of SmolVLA implementations supports such evaluation without substantial upfront investment.
#### 2.5.2 ChatVLA-2: Mixture-of-Experts for Complex Reasoning
##### 2.5.2.1 Mathematical and OCR-Augmented Tracking Scenarios
ChatVLA-2 employs Mixture-of-Experts (MoE) architecture to specialize model capacity across diverse reasoning modalities, with particular strength in mathematical reasoning and optical character recognition. These capabilities, while not directly central to standard tracking tasks, enable specialized applications where tracking must be integrated with symbolic reasoning or text-based information extraction.
For surveillance applications involving document handling, signage reading, or numerical data extraction, ChatVLA-2's augmented capabilities may prove valuable despite its reduced inference speed. The MoE architecture enables efficient routing of specific inputs to appropriate expert modules, preserving some computational efficiency despite the expanded capability set.
##### 2.5.2.2 Research-Grade Availability with Low Inference Speed
ChatVLA-2's research-grade availability limits immediate deployment for production tracking applications, with the model primarily serving as a research platform for exploring VLA capability expansion. The low inference speed—substantially below real-time requirements for standard video—further constrains practical deployment.
For prototype development and capability exploration, ChatVLA-2 provides a valuable reference point demonstrating the potential for VLA architectures to incorporate diverse reasoning modalities. Future efficiency improvements may enable practical deployment of similar capability combinations.
---
3. Functional Role Assessment: VLA vs. Gemma 4 vs. Traditional Pipelines
3.1 Capability Mapping Across Three Paradigms
#### 3.1.1 Gemma 4: General-Purpose Vision-Language Foundation
##### 3.1.1.1 Broad Visual Understanding Without Action Output
Gemma 4 represents Google's flagship open-weight vision-language model, providing substantial visual understanding capabilities without the action generation component that defines VLA architectures. The 27B multimodal variant processes images at up to 8192 resolution with 128K context windows, enabling detailed scene analysis and extended video sequence processing.
The absence of action output mechanisms constrains Gemma 4's direct applicability to closed-loop tracking applications requiring active response to detected objects. However, for analysis-oriented tracking—where the goal is understanding and documentation rather than physical interaction—Gemma 4's capabilities may prove sufficient and its reduced complexity advantageous.
##### 3.1.1.2 Suitable for Description, Classification, and Static Analysis
Gemma 4's strengths center on linguistic description of visual content, categorical classification of depicted objects and scenes, and analysis of static or slowly evolving visual configurations. The model excels at generating rich natural language descriptions that capture object attributes, relationships, and scene context, supporting applications where tracking outputs require human-interpretable documentation.
For dynamic tracking with rapid object motion and identity maintenance requirements, Gemma 4's frame-by-frame processing without explicit temporal modeling mechanisms presents limitations. The extended context window enables some temporal integration through prompt engineering, but without architectural support for temporal reasoning, this approach proves less robust than native video processing architectures.
#### 3.1.2 Traditional MOT Pipelines (YOLO + ByteTrack/DeepSORT)
##### 3.1.2.1 Optimized for Speed-Precision Tradeoffs in Detection
Traditional multi-object tracking pipelines achieve their performance through explicit optimization of the speed-precision tradeoff at every architectural decision. YOLO detection architectures employ single-stage design that directly predicts bounding boxes and class probabilities from full-image features, eliminating the region proposal and refinement stages that increase latency in two-stage detectors.
The evolution of YOLO architectures demonstrates sustained progress in this optimization: YOLOv5's modular PyTorch implementation with depth/width scaling; YOLOv8's decoupled head and anchor-free design with C2f backbone; YOLO11's compact C3k2 bottlenecks and C2PSA attention; and YOLO26's radical simplification with NMS-free end-to-end inference. Each generation improves the efficiency frontier, with YOLO26 achieving 39.8% mAP at 38.9ms CPU inference—substantially faster than predecessors at comparable accuracy.
##### 3.1.2.2 Explicit Bounding Box and Identity Association
The tracking components of traditional pipelines—ByteTrack, DeepSORT, and their successors—implement explicit mechanisms for identity association across frames. These approaches combine motion prediction (typically Kalman filtering) with appearance matching (through learned embedding spaces) to maintain consistent identity labels despite occlusion, reappearance, and detection failure.
The explicit nature of these association mechanisms enables interpretable debugging, predictable failure modes, and straightforward integration with downstream processing that requires consistent object identifiers. The computational efficiency of these methods—often operating at hundreds of FPS on appropriate hardware—supports real-time applications with minimal latency.
##### 3.1.2.3 Absence of Semantic and Action Reasoning
The optimization for speed and explicit association comes at the cost of semantic flexibility and reasoning capability. Traditional trackers operate on fixed category vocabularies defined by detector training, cannot interpret complex linguistic specifications, and provide no mechanism for integrating task-level reasoning into tracking decisions. These limitations constrain applicability in scenarios requiring open-vocabulary object specification, complex query interpretation, or tracking informed by high-level task understanding.
#### 3.1.3 VLA Models: Action-Coupled Perception
##### 3.1.3.1 "Understand Scene + Decide Action" vs. "Detect and Track"
The defining characteristic of VLA models is their integration of perception with action decision-making, captured in the formulation "understand scene + decide action" rather than the "detect and track" paradigm of traditional pipelines. This integration enables closed-loop behavior where tracking directly informs and is informed by intended actions, but introduces complexity that reduces throughput and complicates evaluation.
The action coupling proves advantageous in applications where tracking serves action-oriented goals: robotic following, surveillance with automated response, or autonomous navigation with obstacle avoidance. In these scenarios, the VLA's implicit understanding of action consequences can improve tracking robustness by anticipating environmental changes and planning appropriate responses.
##### 3.1.3.2 Implicit Object State Maintenance Through Action Sequences
Rather than explicit identity association mechanisms, VLA models maintain object state implicitly through action sequence generation that presupposes continued object existence and predictable evolution. When a VLA model generates a sequence of actions to "follow the moving target," the sequence implicitly encodes predictions about the target's future states. A smooth approach trajectory implies confidence in the target's current location and predicted motion; hesitation or replanning signals uncertainty or target loss.
This implicit tracking is functionally equivalent to maintaining a Kalman filter or particle filter state estimate, but expressed in the action space rather than explicitly parameterized. For hybrid tracking systems, implicit VLA tracking can complement explicit traditional tracking by providing "semantic motion priors"—predictions of where interesting objects are likely to move based on goal-directed behavior.
##### 3.1.3.3 Natural Language Task Specification Interface
The language model component of VLA architectures provides natural language interfaces for task specification that substantially exceed the flexibility of traditional tracking systems. Complex referring expressions, temporal constraints, and conditional specifications can be directly interpreted without engineering of specialized feature representations or matching mechanisms.
This interface flexibility enables rapid adaptation to novel tracking requirements without model retraining, supporting applications where task specifications evolve frequently or cannot be fully anticipated during system design. The linguistic interface additionally facilitates human oversight and intervention, with natural language providing a common medium for human-machine collaboration in tracking tasks.
3.2 Quantitative Performance Tradeoffs
| Capability Dimension | Specialized Detectors | VLA Models | Gemma 4 |
|---|---|---|---|
| Detection Precision | Highest | Moderate | Lower |
| Tracking Stability | Highest (30+ fps) | Moderate (1-10 fps) | Not applicable |
| Semantic Flexibility | Lowest (fixed categories) | Highest | High |
| Action Integration | None | Exclusive capability | None |
| Spatial Reasoning | Moderate | High | Moderate |
| Temporal Reasoning | Motion-based only | Rich (multi-frame) | Limited |
| Deployment Efficiency | Highest | Moderate-Low | Moderate |
3.3 Complementary Rather Than Substitutive Relationship
#### 3.3.1 VLA as "Intelligent Brain" vs. "Front-End Detector"
The appropriate conceptualization of VLA models in tracking systems positions them as "intelligent brains" that augment rather than replace "front-end detectors". This architectural pattern preserves the real-time performance of traditional pipelines while leveraging VLA capabilities for semantic enrichment and long-term identity preservation.
The recommended integration pattern processes high-frequency detection outputs through VLA at reduced temporal resolution (5-10 frame intervals), using the model's outputs to verify and refine tracker state rather than replace per-frame association. This architecture preserves the real-time performance of traditional pipelines while leveraging VLA capabilities for semantic consistency and long-term identity preservation.
#### 3.3.2 Gemma 4 as General Visual-Language Interface
Gemma 4's positioning as general visual-language interface—without action generation—makes it suitable for applications requiring rich description and analysis without closed-loop control. Its deployment in tracking systems would emphasize documentation, search, and retrospective analysis rather than real-time guidance.
The integration of Gemma 4 with detection pipelines parallels VLA integration patterns, with reduced complexity due to the absence of action output but also reduced capability for proactive system behavior.
#### 3.3.3 Traditional Pipeline as High-Frequency Perception Engine
The traditional detection-tracking pipeline retains its role as high-frequency perception engine, providing the continuous environmental monitoring that enables responsive system behavior. This foundational role persists across architectural variations, with VLA and Gemma 4 components layered atop this foundation to provide enhanced semantic capabilities at reduced temporal resolution.
---
4. Hybrid Architecture Design: Optimal Integration Patterns
4.1 Tiered Processing Framework
#### 4.1.1 Layer 1: High-Speed Detection (YOLO/YOLO-World)
##### 4.1.1.1 Per-Frame Bounding Box Generation at 30+ fps
The foundation of practical hybrid architectures is high-speed detection operating at video frame rate or above. YOLO26's optimized implementation achieves 38.9ms CPU inference (25+ FPS) with TensorRT GPU acceleration enabling substantially higher throughput. This performance level ensures that no significant motion occurs between detection updates, supporting reliable association and responsive system behavior.
The detection output provides the geometric foundation for all subsequent processing: bounding box coordinates that localize objects with precision exceeding VLA attention-based localization, class probabilities that enable initial categorization, and confidence scores that support detection quality assessment. This geometric precision compensates for the relative coarseness of VLA spatial understanding.
##### 4.1.1.2 Initial Object Hypothesis Creation
Detection outputs create initial object hypotheses that seed the tracking process. Each detection initiates a track candidate that subsequent association mechanisms attempt to link across frames, with the detection's class label providing initial semantic information that may be refined through VLA processing.
The hypothesis creation process includes quality filtering based on detection confidence, with low-confidence detections either suppressed or flagged for cautious handling. This filtering reduces false positive tracks that would consume downstream processing resources and potentially trigger erroneous VLA analysis.
#### 4.1.2 Layer 2: Temporal Association (ByteTrack/DeepSORT)
##### 4.1.2.1 Identity Preservation Across Frames
The association layer maintains consistent identity labels across detection frames, implementing the core tracking functionality. ByteTrack's association mechanism combines motion prediction through Kalman filtering with appearance matching through learned embeddings, achieving robust association despite temporary detection failure and moderate occlusion.
The identity preservation mechanism enables trajectory construction that supports velocity estimation, motion pattern analysis, and anomaly detection. These trajectory-based features complement the instantaneous features extracted by detection, providing temporal context that improves tracking robustness.
##### 4.1.2.2 Motion-Based Trajectory Prediction
Association mechanisms incorporate motion prediction that anticipates object positions during occlusion or detection gaps. This prediction capability proves particularly valuable for maintaining track continuity through challenging sequences, with the prediction uncertainty quantification supporting appropriate confidence adjustment for predicted positions.
The trajectory predictions additionally provide motion features—velocity, acceleration, motion direction—that support higher-level behavior analysis and anomaly detection. These features may inform VLA processing by highlighting objects exhibiting unusual motion patterns.
#### 4.1.3 Layer 3: Semantic Enrichment (VLA at 5-10 Frame Intervals)
##### 4.1.3.1 Open-Vocabulary Fine-Grained Recognition
VLA processing at reduced temporal resolution provides semantic enrichment that exceeds the capabilities of detection classifiers. The open-vocabulary understanding enables recognition of object categories, attributes, and relationships not represented in detector training data, supporting applications with diverse or evolving tracking requirements.
Specific capabilities include: fine-grained category specification ("electric scooter" vs. generic "vehicle"); attribute identification ("red jacket," "carrying backpack"); and relational analysis ("person approaching building entrance"). The VLA's language interface enables flexible specification of recognition targets without model retraining.
##### 4.1.3.2 Multi-Frame State Tracking and Behavior Understanding
Beyond single-frame recognition, VLA processing of short temporal windows enables behavior understanding that integrates information across time. This includes: action recognition ("person is running," "vehicle is parking"); intent prediction ("person appears to be heading toward exit"); and anomaly detection ("unusual loitering pattern").
This behavioral analysis supports higher-level tracking applications where object trajectories must be interpreted in terms of their functional significance rather than merely their geometric properties.
##### 4.1.3.3 Decision/Action Signal Generation
For deployment scenarios involving robotic or automated response systems, the VLA tier generates decision and action signals based on integrated tracking and behavior understanding. These signals may include: alerts for security personnel; navigation commands for following robots; or control signals for active camera pointing.
The integration of perception with action generation—VLA's distinctive capability—enables closed-loop behaviors that adapt observation and response strategies based on tracking progress and task requirements.
4.2 Information Flow Integration
#### 4.2.1 VLA Output to Tracker State Update
##### 4.2.1.1 Identity Verification and Correction
VLA semantic analysis can provide identity verification that corrects errors in traditional tracking association. When the VLA recognizes that "the person currently labeled track_7 is actually the same person previously labeled track_3 who changed jackets," this information can trigger track merging that maintains long-term identity consistency.
Implementation requires careful confidence thresholding to avoid introducing errors from uncertain VLA recognitions, with verification typically applied only when VLA confidence exceeds calibrated thresholds and traditional association exhibits ambiguity indicators.
##### 4.2.1.2 Dynamic Class Label Refinement
VLA recognition enables dynamic refinement of object class labels as detections are processed, with coarse detector categories replaced by fine-grained VLA identifications. This refinement can propagate backward to reclassify recent trajectory segments, improving consistency and supporting more accurate behavioral analysis.
#### 4.2.2 VLA Output to Downstream Control
##### 4.2.2.1 Direct Action Command Generation
For robotic tracking applications, VLA action outputs can directly control platform motion, with velocity commands or waypoint sequences enabling active target following. This integration eliminates separate planning components, creating unified perception-action loops that adapt to dynamic scene conditions.
##### 4.2.2.2 Anomaly Alert Triggering
VLA behavior understanding enables intelligent alert generation, with natural language specification of alert conditions supporting flexible deployment configuration. The semantic richness of VLA analysis enables more nuanced alerting that distinguishes concerning situations from benign anomalies with similar superficial characteristics.
4.3 Latency-Aware Scheduling
#### 4.3.1 Adaptive Frame Sampling Based on Scene Dynamics
Adaptive frame sampling optimizes computational resource allocation, with increased VLA invocation frequency during complex or rapidly evolving scenes and reduced frequency during quiescent periods. This adaptation can be driven by simple heuristics—motion magnitude, detection count, track density—or by more sophisticated prediction of when VLA insights would be most valuable.
#### 4.3.2 Asynchronous VLA Inference with Result Buffering
Asynchronous processing decouples high-frequency tracking from latency-tolerant semantic enrichment. The tracker operates on detection outputs with minimal latency, while VLA processing proceeds in parallel with results incorporated when available. This architecture accepts temporary semantic information staleness—typically 100-300ms depending on VLA latency—for substantial system responsiveness improvement.
#### 4.3.3 Fallback to Pure Traditional Pipeline Under Resource Pressure
Graceful degradation ensures that core detection and tracking capabilities remain available even when VLA processing cannot keep pace with requirements. This may occur during scene complexity spikes, hardware thermal throttling, or concurrent workload competition. The fallback mechanism preserves basic functionality, with semantic enrichment resuming when resources permit.
---
5. Scenario-Specific Deployment Recommendations
5.1 Robotics-Centric Applications
#### 5.1.1 Visual Servoing and Grasp Planning
| Application Sub-Type | Recommended VLA | Key Considerations |
|---|---|---|
| General manipulation | OpenVLA or π0.5 | Balance of capability and accessibility |
| Dexterous fine control | Gemini Robotics | Specialized training for high-DOF hand control |
| High-speed assembly | π0.5 with flow matching | 50 Hz control rates for responsive interaction |
| Novel object categories | Any open-vocabulary VLA | Zero-shot generalization reduces setup time |
#### 5.1.2 Mobile Robot Navigation and Object Following
| Scenario | Specialized Solution | Key Capability |
|---|---|---|
| Aerial tracking (drones) | UAV-Track VLA | 17.5 fps with temporal compression |
| Ground vehicle following | TrackVLA / TraceVLA | Embodied trajectory with collision avoidance |
| Legged locomotion | Helix (System 1/2) | Whole-body coordination with visual tracking |
| Long-duration patrol | TrackVLA++ with TIM | 30+ minute identity maintenance |
5.2 Intelligent Video Surveillance
| Requirement | Architecture Pattern | VLA Role |
|---|---|---|
| Real-time anomaly detection | Mandatory hybrid | Behavior understanding, alert prioritization |
| Cross-camera re-identification | Language-guided association | Semantic matching across viewpoint changes |
| Long-term behavior analysis | VLA-enriched storage | Activity classification, pattern recognition |
| Interactive query response | Gemma 4 + VLA hybrid | Natural language interface to video archive |
5.3 Autonomous Driving Perception
| Function | VLA Contribution | Critical Constraint |
|---|---|---|
| Multi-agent interaction prediction | Physics-informed motion forecasting | Safety-critical redundancy required |
| Vulnerable road user intent | Behavioral cue interpretation | Latency must not exceed reaction time |
| Construction zone navigation | Open-vocabulary obstacle recognition | Fallback to traditional perception essential |
| Anomaly response (wrong-way driver) | Situation assessment, emergency planning | Deterministic validation of VLA outputs |
5.4 Edge and Embedded Deployment
| Platform Category | Recommended Solution | Expected Performance |
|---|---|---|
| High-end mobile (Tensor G4) | Gemini Robotics On-Device | 5-10 fps, Google ecosystem integration |
| General edge (Jetson, Snapdragon) | SmolVLA | 5-15 fps, platform-agnostic deployment |
| Ultra-low-power (microcontrollers) | Quantized SmolVLA or custom distillation | 1-5 fps, task-specific optimization |
| Custom ASIC/FPGA | Architecture search + hardware co-design | Application-dependent, requires engineering investment |
---
6. Implementation Pathways and Practical Considerations
6.1 OpenVLA Quick-Start Protocol
# Environment setup
pip install transformers torch accelerate
# Model loading
from transformers import AutoModelForVision2Seq, AutoProcessor
model = AutoModelForVision2Seq.from_pretrained(
"openvla/openvla-7b",
torch_dtype=torch.float16,
device_map="auto"
)
processor = AutoProcessor.from_pretrained("openvla/openvla-7b")
# Video frame processing
def process_frame_sequence(frames, query):
# frames: list of PIL Images or tensors
# query: natural language tracking specification
inputs = processor(images=frames, text=query, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=256)
return processor.decode(outputs[0], skip_special_tokens=True)
# Prompt engineering for tracking-oriented outputs
TRACKING_PROMPTS = {
"location": "In this image, where is {target}? Describe its position precisely.",
"tracking": "Track {target} across these frames. Report position changes and any notable behavior.",
"verification": "Is the object at {location} the same as {description}? Explain your reasoning."
}
Key implementation considerations:
| Aspect | Recommendation | Rationale |
|---|---|---|
| Frame resolution | 224×224 or 336×336 | Balance of detail and inference speed |
| Temporal context | 4-8 frames for dynamic scenes | Sufficient for motion understanding without excessive latency |
| Query specificity | Include distinguishing attributes | Reduces ambiguity, improves grounding accuracy |
| Output parsing | Structured extraction with fallback heuristics | VLA outputs may vary in format and completeness |
| Confidence thresholding | Calibrate on domain-specific validation set | Prevents over-reliance on uncertain VLA predictions |
6.2 YOLO-VLA Integration Code Patterns
class HybridTrackingSystem:
def __init__(self):
self.detector = YOLO("yolov8x-worldv2.pt") # 30+ fps
self.tracker = ByteTrack() # Real-time association
self.vla = OpenVLAWrapper() # 5-10 fps semantic enrichment
self.vla_queue = asyncio.Queue(maxsize=4) # Async buffering
async def process_frame(self, frame):
# Layer 1: High-speed detection (every frame)
detections = self.detector(frame, verbose=False)[0]
# Layer 2: Temporal association (every frame)
tracks = self.tracker.update(detections)
# Layer 3: Async VLA enrichment (every 5-10 frames)
if self.frame_count % self.vla_interval == 0:
await self.vla_queue.put({
'frame': frame,
'tracks': tracks,
'timestamp': time.time()
})
# Apply available VLA results with temporal interpolation
enriched_tracks = self.apply_vla_updates(tracks)
return enriched_tracks
async def vla_worker(self):
while True:
item = await self.vla_queue.get()
vla_output = await self.vla.process(
frames=self.get_temporal_window(item),
query=self.generate_tracking_query(item['tracks'])
)
self.update_track_cache(item['timestamp'], vla_output)
6.3 Evaluation and Benchmarking
| Metric Category | Specific Metrics | Evaluation Approach |
|---|---|---|
| Detection quality | mAP, recall@IoU, small object AR | Standard COCO/LVIS evaluation on VLA-extracted boxes |
| Tracking performance | MOTA, IDF1, HOTA, MT/ML/Frag | MOTChallenge or custom benchmark with VLA integration |
| Semantic accuracy | Open-vocabulary recall, attribute precision | Human evaluation on natural language queries |
| Action correctness | Task success rate, safety violations | Domain-specific simulation or real-world deployment |
| System efficiency | End-to-end latency, throughput, power | Profiling on target deployment hardware |
| Long-term consistency | Identity preservation over hours, drift accumulation | Extended scenario testing with ground truth |
---
7. Future Trajectory and Research Frontiers
7.1 Architectural Convergence Trends
| Direction | Current State | Potential Impact |
|---|---|---|
| Detection-specific VLA design | UAV-Track VLA auxiliary heads, Mantis disentanglement | Native bounding box + ID output without post-hoc extraction |
| Neural architecture search | Emerging in efficiency optimization | Task-optimal hybrids combining detector speed with VLA reasoning |
| Unified pretraining objectives | Separate VLM + robot fine-tuning | Joint optimization for detection, tracking, and action |
| Differentiable tracking layers | End-to-end tracker learning | Gradient flow from tracking metrics to VLA representations |
7.2 Efficiency Breakthroughs
| Approach | Technical Basis | Projected Outcome |
|---|---|---|
| Progressive distillation | Teacher-student with capability preservation | Sub-second frame rate with >90% capability retention |
| Speculative decoding | Draft model for action token prediction | 2-3× latency reduction for autoregressive VLAs |
| Event-camera integration | Asynchronous visual sensing, sparse processing | Microsecond effective latency for high-speed scenarios |
| Neuromorphic acceleration | Spiking neural networks, in-memory computing | Order-of-magnitude efficiency gains on specialized hardware |
7.3 Expanded Task Horizons
| Emerging Capability | Enabling Technology | Application Domain |
|---|---|---|
| Multi-modal tracking (visual-language-audio) | Unified multimodal transformers | Surveillance with acoustic event detection |
| Predictive tracking with physical world models | Neural physics simulation, differentiable simulation | Autonomous driving, robotic manipulation |
| Social behavior prediction | Theory-of-mind modeling, multi-agent reasoning | Crowd monitoring, public safety |
| Lifelong adaptive tracking | Continual learning, meta-learning | Long-term deployment with evolving scenarios |
---
Conclusion
Vision-Language-Action models represent a transformative but strategically bounded capability for video object detection and tracking applications. Their core design for robotic end-to-end control creates fundamental mismatches with traditional MOT requirements—particularly the ~1 fps inference speeds of full-scale models versus 30+ fps real-time needs, and the implicit action outputs versus explicit bounding box + ID expectations. These are not incidental limitations to be engineered away but structural consequences of architectural choices that enable VLA's distinctive strengths.
The optimal deployment pattern is not substitution but complementarity: traditional pipelines (YOLO + ByteTrack/DeepSORT) as high-frequency perception engines, VLAs as semantic enrichment layers operating at 5-10 frame intervals, and Gemma 4 as general visual-language interface where action generation is not required. This tiered architecture preserves real-time responsiveness while accessing the open-vocabulary recognition, temporal reasoning, and action integration that distinguish VLA capabilities.
For practitioners initiating VLA exploration, OpenVLA offers the most accessible entry point—complete open-source availability, established community support, and proven adaptability through LoRA fine-tuning. For demanding applications requiring superior generalization, π0.5 provides state-of-the-art open-world performance with partial availability that nonetheless enables effective deployment. For resource-constrained scenarios, SmolVLA achieves practical efficiency without catastrophic capability loss.
The field is evolving rapidly: architectural innovations like UAV-Track VLA's temporal compression demonstrate that substantial efficiency gains are possible without fundamental model changes, while research frontiers in detection-specific VLA design and neuromorphic acceleration promise to narrow the gap between VLA capabilities and MOT requirements. The strategic practitioner will monitor these developments while deploying today's capabilities in architectures that leverage their genuine strengths without demanding performance they cannot deliver.

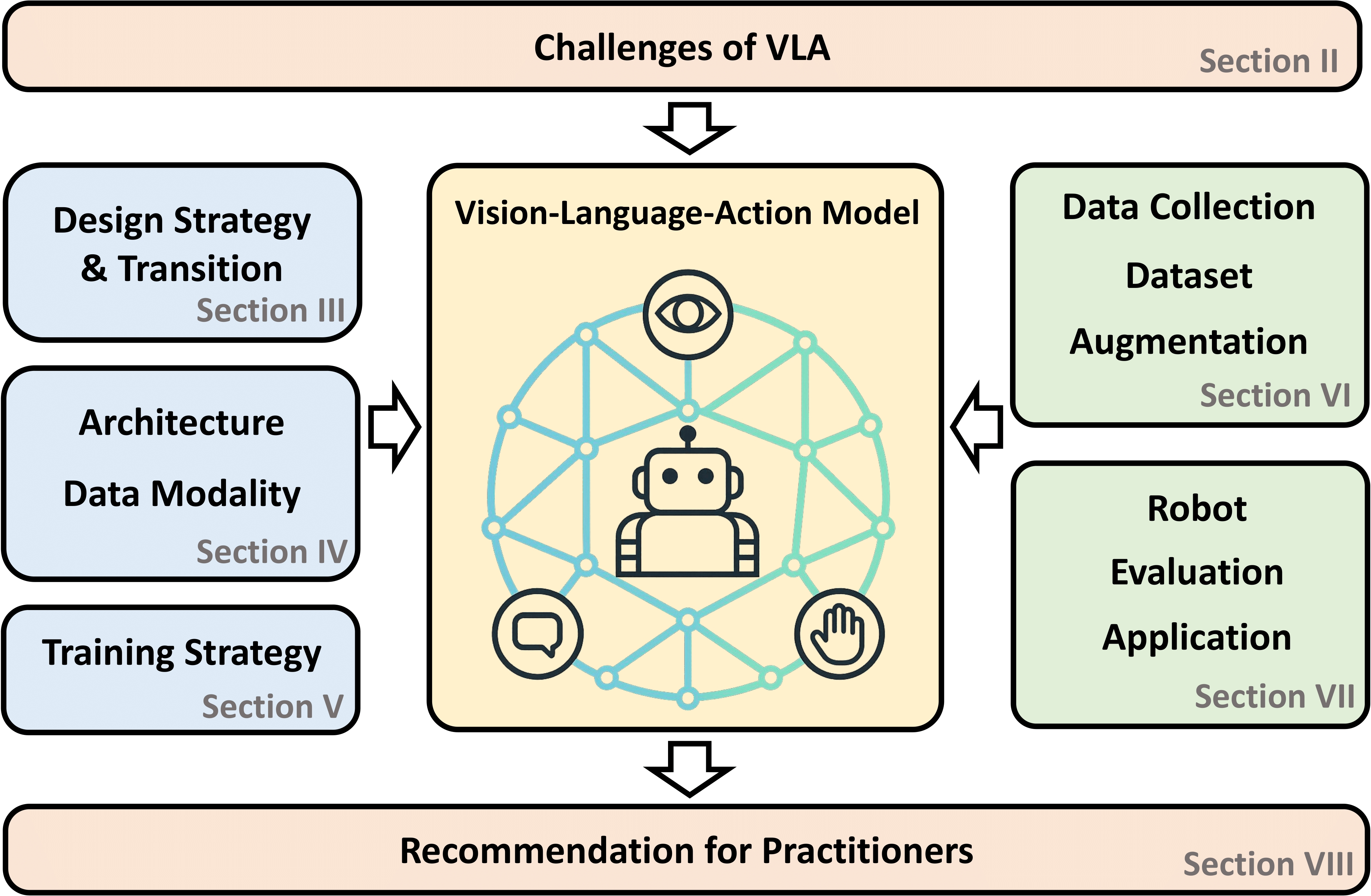

🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens