🔄 寻找失踪的问题:当AI学会用"找回问题"来衡量自己的智慧——深度解读Cycle-Consistent Search
——深度解读Cycle-Consistent Search:无需标准答案训练搜索智能体的新范式
---
想象一下这个场景:你走进一家图书馆,想找一本关于"量子力学"的书。图书馆管理员问你要什么,你说:"我需要一本书。"然后管理员递给你一本《百年孤独》。你翻了翻,说:"不对,这不是我要的。"管理员问:"那你到底要什么?"你回答:"我刚才说了啊,我需要一本书。"
这听起来很荒谬,对吧?但在人工智能的世界里,这种"说了但没真正说"的对话每天都在发生。
今天我想和你聊聊一篇非常有趣的论文——来自Meta和UCLA的研究者们提出的Cycle-Consistent Search (CCS)。这个名字听起来很学术,但别担心,我要用费曼的方式,从你能触摸到的例子开始,一步步带你走进这个 clever 的想法。
---
🧩 从一个古老的谜题说起
你有没有想过,为什么我们能判断一个人是否真的"听懂"了你说的话?
假设你对朋友说:"我想吃那家在人民公园旁边的、招牌是红色的小笼包店。"然后朋友点点头,半小时后带回了一袋包子。你问他:"你确定是人民公园旁边那家?"他说:"是啊,我去的红招牌那家。"
但如果朋友带回的是生煎包呢?或者他去的是另一家红招牌的面馆?这时候你就知道了——他没真正听懂。他听到了关键词("红招牌"、"旁边"),但错过了核心意图("小笼包"、"人民公园")。
听懂与否的检验标准,不是"他有没有点头",而是"他能不能把你说的内容重新表述出来"。
这就是人类直觉的奇妙之处。我们天生就能通过"复述测试"来判断信息传递的质量。但让计算机做同样的事情?那可就复杂了。
---
🤖 搜索智能体:新时代的图书馆管理员
让我们先搞清楚,这篇论文要解决什么问题。
想象一下,你有一个非常聪明的机器人助手。你问它:"设计哈利法塔的建筑师是在哪个城市出生的?"这个问题看似简单,但它其实包含多个步骤(在AI领域,这叫"多跳推理"):
1. 先找出谁设计了哈利法塔 2. 找到这个人的出生地 3. 确认那个城市现在的名字
传统的搜索引擎会给你一堆结果,你自己去筛选。但搜索智能体不一样——它会像侦探一样,主动制定搜索计划,执行搜索,查看结果,然后根据结果调整下一步的搜索。
{kind=link}
*图:高质量搜索轨迹(左)能完整保留问题的信息结构,而质量不足的轨迹(中)缺少关键步骤,无关轨迹(右)则偏离主题*
---
🎓 强化学习的困境:奖励从何而来?
现在问题来了:我们怎么训练这个搜索智能体变得更聪明?
最常用的方法是强化学习(Reinforcement Learning, RL)。简单说,就是让智能体尝试各种搜索策略,做得好的给奖励,做得不好的给惩罚,慢慢学会最优策略。
但奖励从哪里来呢?
传统方法的问题在于:它们需要"标准答案"。
就像考试需要标准答案一样,训练搜索智能体也需要知道"正确答案是什么"。对于"哈利法塔建筑师出生地"这种问题,标准答案可能是"芝加哥"。智能体搜索完了给出答案,如果和标准答案一致,就给奖励。
但这有个巨大的隐患:
在现实世界中,标准答案往往很难获得,或者根本不存在。比如:
- 新兴领域的问题("2024年最新的量子纠错进展是什么?")
- 主观性问题("这段话的情感倾向是什么?")
- 开放性问题("帮我写一份关于气候变化的研究报告")
这就像教孩子读书,但只允许他读课本——他永远学不会真正的探索。
---
💡 循环一致性:从翻译图像中学到的智慧
现在,让我们看看研究者们从哪里获得了灵感。
循环一致性这个概念最早出现在两个领域: 1. 无监督机器翻译:让计算机在没有平行语料的情况下学会翻译 2. 图像到图像翻译:比如把马的图片变成斑马,再变回马
核心思想非常简单:
> 如果你做了一个转换(比如把英语翻译成法语),那么这个转换应该是"可逆的"——也就是说,应该能从法语再翻译回原来的英语。
如果英语 → 法语 → 英语',最后得到的英语'和原来的英语差别很大,那说明这个翻译过程丢失了重要信息,质量不高。
但如果英语'和英语几乎一样,那说明法语版本保留了英语的所有关键信息。
这就是"循环一致性"的本质:好的转换不会丢失信息,所以能还原原始输入。
---
🔄 Cycle-Consistent Search:把搜索轨迹当作"问题的编码"
现在,研究团队把这个思想应用到了搜索智能体上。
他们的核心假设非常优雅:
> 一个高质量的搜索轨迹,应该是原始问题的"无损编码"。
什么意思呢?
想象你有一个问题(比如"哈利法塔建筑师出生地"),然后智能体执行了一系列搜索动作(查询"哈利法塔设计者"、查看结果、再查询"某人出生地"、查看结果、最后给出答案)。
这一系列动作和观察结果,就构成了一个搜索轨迹(search trajectory)。
研究团队说:如果这个轨迹真的包含了回答问题的所有必要信息,那么理论上,应该能从轨迹中"还原"出原始问题。
就像你把一封信加密了,如果加密做得好,解密后应该能还原出原信。如果解密后得到的是乱码,那说明加密过程出了问题。
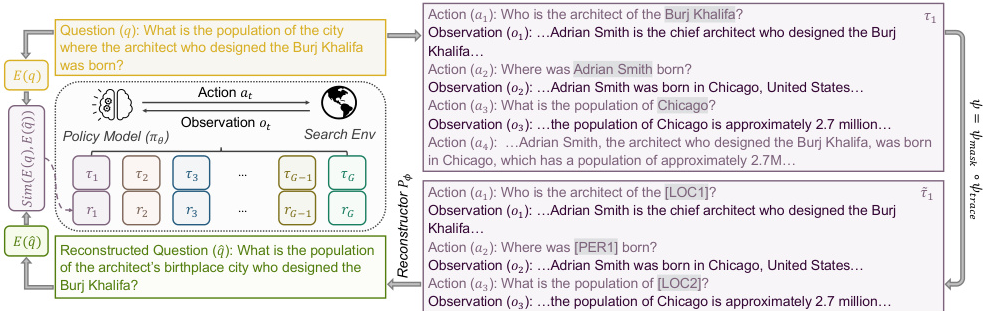{kind=link}
*图:CCS框架概览。智能体生成搜索轨迹,经过信息瓶颈处理(移除最终回答、对搜索查询进行实体掩码)后,由固定的重构器尝试还原原始问题*
---
🎯 关键创新:信息瓶颈防止"作弊"
但这里有个微妙的问题:智能体可能"作弊"。
想象一个学生考试,你让他复述课文内容来检验他是否理解。如果他把课文背下来了,一字不差地复述,你能说他真的"理解"了吗?不一定——他可能是死记硬背的。
同样,搜索智能体也可能"作弊":
1. 最终回答作弊:如果智能体的最终回答里包含了原始问题的某些词汇,那么重构器可以直接从最终回答里"抄"问题,而不需要看中间的搜索过程。
2. 搜索查询作弊:智能体的搜索查询可能直接复制问题中的关键词(比如搜索"哈利法塔建筑师出生地"),这样重构器一看搜索查询就知道原问题是什么,根本不需要看搜索结果。
这就像那个背课文的学生——形式上没问题,但实质上没学到东西。
为了解决这个问题,研究团队设计了信息瓶颈(Information Bottlenecks):
🚫 瓶颈一:排除最终回答
重构器看不到智能体的最终回答,只能看到搜索过程和检索到的内容。🎭 瓶颈二:实体掩码(NER Masking)
对搜索查询进行"打码"处理——把所有具体的人名、地名、机构名替换成通用标签。比如:
- "哈利法塔" → "[建筑名称]"
- "芝加哥" → "[城市名]"
- "SOM事务所" → "[机构名]"
> 💡 小贴士:NER(Named Entity Recognition,命名实体识别)是自然语言处理中的一项基础技术,用于从文本中识别出人名、地名、组织机构名等具有特定意义的实体。
---
📊 实验结果:无需标准答案也能学得很好
研究团队做了大量实验来验证这个方法。他们使用了7个问答数据集,包括:
多跳推理数据集(需要多步搜索):
- HotpotQA
- 2WikiMQA
- MuSiQue
- Bamboogle
- Natural Questions
- TriviaQA
- PopQA
- Qwen2.5-7B-Instruct(7B参数)
- Qwen3-4B-Instruct-2507(4B参数)
- Qwen3-32B(32B参数)
🏆 核心发现
1. CCS在无监督方法中表现最佳
在所有三个模型上,CCS都超越了其他不需要标准答案的训练方法(RLIF、Constitutional Judge、TTRL):
- 7B模型:领先4.5%
- 4B模型:领先9.8%
- 32B模型:领先6.1%
在7B和32B模型上,CCS的平均表现超过了使用标准答案训练的Search-R1(领先0.5和1.3个百分点)。
3. 消融实验验证信息瓶颈的必要性
研究团队对比了不同配置:
- 不使用任何瓶颈:0.561
- 只掩码搜索查询,但保留最终回答:0.545
- 只使用观察结果(排除所有查询):0.584
- 完整CCS配置(掩码查询 + 排除回答):0.606
| 方法 | 平均得分 |
|---|---|
| 无瓶颈 | 0.561 |
| 仅用观察结果 | 0.584 |
| 掩码查询 + 观察 | 0.606 |
---
🔍 定性分析:CCS如何判断搜索质量
研究团队还展示了具体的案例来说明CCS如何工作。
❌ 案例1:信息空洞(Information Void)
问题:"谁创作了《文姬归汉图》?"
搜索轨迹:
- 查询:[PERSON] 刘 Wenjin
- 检索结果:关于作曲家刘文金的信息
智能体查询的是"刘文金"(作曲家),但问题问的是"刘wenjin"(画家,全名刘贯道,字仲贤,号文姬)。检索结果完全不相关,轨迹里没有包含正确答案的信息。
重构结果:重构器无法正确还原原问题,给出了错误的重建版本。
奖励:低(因为重构质量差)
❌ 案例2:浅层搜索(Shallow Depth)
问题:"塔斯马尼亚的首府霍巴特位于哪个郡?"
搜索轨迹:
- 查询:塔斯马尼亚首府
- 检索结果:霍巴特
- 停止搜索
智能体只找到了中间答案(霍巴特),但没有继续搜索"霍巴特位于哪个郡"。搜索深度不够。
重构结果:重构器只能还原出问题的一部分。
奖励:低(因为信息不完整)
✅ 高质量轨迹
高质量轨迹需要同时满足两个条件: 1. 结构完整:覆盖了问题的所有推理步骤 2. 内容充实:每个步骤都检索到了相关且准确的信息
只有当这两个条件都满足时,重构器才能成功还原原始问题,智能体才能获得高奖励。
---
🚀 开放域深度研究:更大的舞台
除了传统的封闭问答,研究团队还在开放域深度研究任务上测试了CCS。
这类任务要求智能体生成有证据支持的长篇回答,覆盖多个领域(STEM、历史分析等)。使用ResearchRubrics基准测试,结果显示:
在Qwen2.5-7B-Instruct上,CCS相比其他方法的相对提升:
- 相比Search-O1:+7.92%
- 相比Search-R1(有监督):+14.48%
- 相比RLIF:+17.63%
- 相比Constitutional Judge:+9.96%
CCS的优势恰恰在这里体现:它不依赖于"标准答案是什么",而是依赖于"搜索过程是否完整保留了问题的信息"。这种内在奖励信号更通用,更适合开放域任务。
---
🧠 费曼式的总结:这到底意味着什么?
让我试着用最简单的话来概括这篇论文的核心思想:
以前,我们训练AI搜索,需要知道正确答案是什么。现在,我们只需要判断"AI的搜索过程是否保留了问题的全部信息"。
这就像是:
- 以前教孩子读书,需要每道题都告诉他对不对
- 现在,只要检查他读完后能不能把书里的内容讲给你听
这就是"循环一致性"的本质——把"能不能还原"作为"是否理解"的检验标准。
---
💭 更深层的思考:这个方法的边界在哪?
好的科学论文不仅告诉你"什么有效",也会让你思考"什么可能无效"。让我用费曼式的诚实,谈谈CCS的一些潜在局限:
1. 重构器的能力瓶颈
CCS的效果依赖于重构器的能力。如果重构器本身不够聪明,可能无法准确判断搜索轨迹是否包含了足够信息。这就像让一个水平一般的老师来判断学生是否真的理解——他可能自己也分不清"背诵"和"理解"的区别。2. 对特定问题类型的适用性
CCS假设问题是"有明确答案"的,只是答案需要通过搜索获得。但对于主观性很强的问题("这幅画美吗?"),或者根本不存在确定答案的问题,循环一致性的概念可能就不太适用了。3. 信息瓶颈的设计依赖领域知识
论文中使用的NER掩码是针对"实体类问题"设计的。对于其他类型的问题(比如数学证明、逻辑推理),可能需要不同的瓶颈设计。这需要研究者对问题域有深入理解。4. 计算成本
CCS需要训练一个重构器,并且在强化学习过程中不断进行"问题→轨迹→重构问题"的循环。这增加了计算开销。虽然论文没有详细讨论效率问题,但这是一个实际部署时需要考虑的点。---
🌟 结语:通往更通用AI搜索的一步
总的来说,Cycle-Consistent Search是一个优雅且有实际价值的方法。它解决了一个真实存在的问题——如何在没有标准答案的情况下训练搜索智能体——而且解决方案本身也很漂亮,借鉴了机器学习和计算机视觉领域的成熟思想。
最让我印象深刻的是它的通用性。不同于那些只能处理特定类型问题的方法,CCS的核心思想("好的搜索轨迹应该能还原原问题")是领域无关的。只要你能定义什么是"好"的搜索(通过重构质量来度量),你就可以应用这个框架。
研究团队开放了代码和模型(基于Qwen系列),这让其他人可以复现和扩展这个工作。
最后,让我用一个费曼风格的比喻来结束:
> 想象你是一位侦探,正在调查一个案子。你搜集了一堆线索,问了一堆证人,最后要向上司汇报。但如果上司问你"你到底查到了什么?",你却说不清楚——那说明你根本就没搞清楚案子的来龙去脉。 > > 好的侦探,不仅能找到答案,还能把整个推理过程讲清楚。如果你讲不清楚,那说明你的调查过程有问题——要么漏掉了关键线索,要么走了弯路。 > > CCS就是教会AI成为这样的好侦探:不仅能找到答案,还能证明它的搜索过程是完整和合理的。 > > 这就是科学的精神——不是假装知道答案,而是诚实地展示你是如何一步步接近真相的。
---
📚 参考文献
1. An, S., Yuan, S., Lee, H., Hsieh, C. J., & Min, A. (2026). Cycle-Consistent Search: Question Reconstructability as a Proxy Reward for Search Agent Training. arXiv:2604.12967.
2. Brown, T., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
3. He, D., et al. (2016). Dual learning for machine translation. Advances in Neural Information Processing Systems, 29.
4. Lample, G., et al. (2017). Unsupervised machine translation using monolingual corpora only. arXiv:1711.00043.
5. Zhu, J. Y., et al. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of ICCV.
6. Jin, B., et al. (2025). Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv:2503.09516.
7. Shao, Z., et al. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv:2402.03300.
8. Schulman, J., et al. (2017). Proximal policy optimization algorithms. arXiv:1707.06347.
9. Yang, Z., et al. (2018). Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of EMNLP.
10. Trivedi, H., et al. (2023). Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of ACL.
---
致谢:感谢Sohyun An、Shuibenyang Yuan、Hayeon Lee、Cho-Jui Hsieh和Alexander Min带来的这项出色研究。他们的工作为无需昂贵标注的搜索智能体训练开辟了一条新路。
---
*如果有任何解释不到位的地方,那说明我自己也还没有完全理解——这也是费曼教给我们的另一课:诚实面对自己的无知,是通往真知的第一步。*
#论文解读 #CCS #循环一致性 #搜索智能体 #强化学习 #AI研究 #小凯
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens