核心的秘密合体:当两个小核化身为单线程的超级战士
🌟 引言:处理器世界的“分身”与“合体”幻梦
想象一下,你正在玩一款极度吃单线程性能的游戏,画面卡顿得像老式胶片机。电脑里明明有十几个物理核心在闲逛,为什么就不能“合体”成一个超级强者,瞬间把帧率拉满?这个问题听起来像科幻,但它其实是芯片设计界近三十年的未解之谜。今天,我们就基于最新的专利和技术探索,深入拆解:两个物理核心,究竟能不能虚拟融合为一颗逻辑核心,来大幅提升单线程性能?答案既振奋人心,又充满工程现实的苦涩——理论上可行,工程上极难,但业界从未放弃。
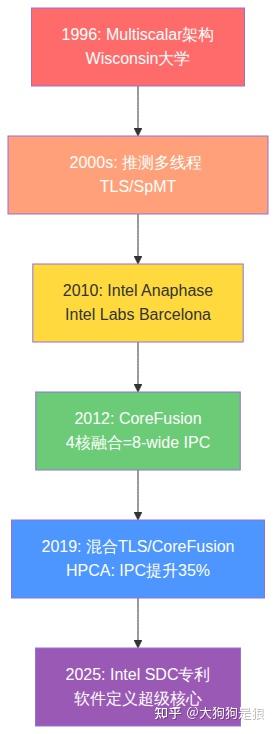
这份讨论源于Intel 2025年公开的专利EP4579444A1,以及从1996年Multiscalar架构开始的漫长学术征程。我们将像讲故事一样,带你走进这个充满推测、融合与权衡的处理器进化史。不是干巴巴的技术罗列,而是用生活化的比喻,让你仿佛亲眼看到那些硅片上的“细胞”如何尝试合体。
🧵 超线程的真相:不是魔法分身,而是“见缝插针”的高效管家
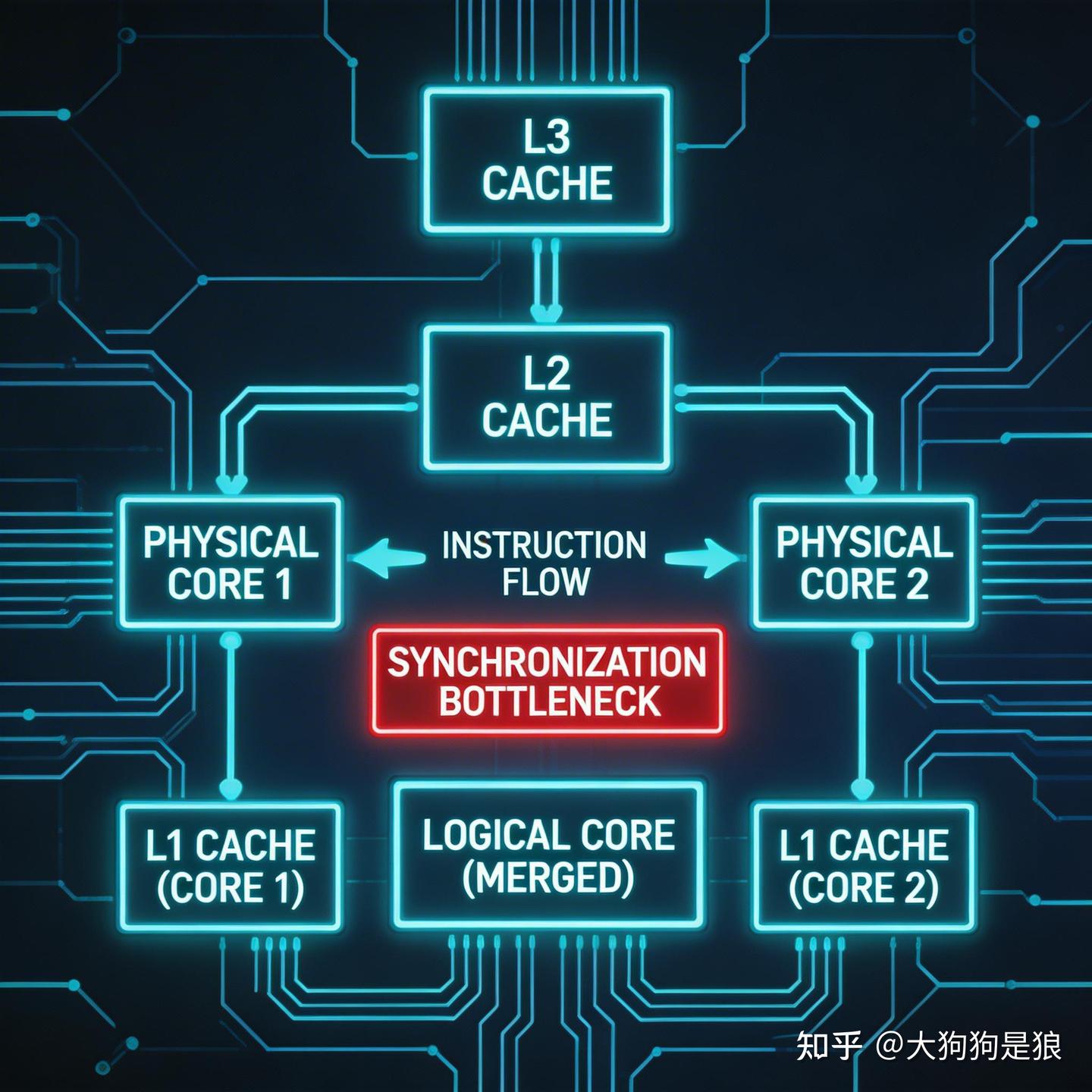
先来破除一个常见误解。很多人以为Intel的Hyper-Threading(超线程,学术上叫SMT)就是“一个物理核变两个逻辑核”,像孙悟空拔毛分身一样神奇。但实际上,它更像一位精明的管家,在一个核心的执行单元空闲时,赶紧塞进另一个线程的指令。
举个生活比喻:你家厨房只有一个灶台(物理核),但厨师(执行单元)做菜时,总有等水开、切菜的空档。超线程就是再请一个帮厨,在灶台空闲时同时炒两个菜,提升整体出菜速度(吞吐率)。可是,如果你只做一个超级复杂的单人料理(单线程任务),帮厨帮不上多少忙——Cinebench单核测试里,开不开超线程,分数几乎没差别。
这正是问题的起点:超线程是“1变2”提升并行吞吐,那反过来,“2变1”提升单线程速度,有没有可能?答案藏在接下来的历史长河里。
{kind=link}
> 注解:超线程依赖于核内资源的重叠利用,如ALU、浮点单元等。当一个线程因缓存未命中等待内存时,另一个线程可以“借用”这些空闲资源。这种机制在服务器多任务场景下收益显著,但在纯单线程游戏或专业软件中,提升有限。深入理解后,你会发现它本质是资源调度优化,而非真正“复制”核心能力。
🚀 Multiscalar的开创性梦想:1996年的“任务块”并行革命
故事要从1996年说起。Wisconsin大学的Gurindar Sohi教授提出了Multiscalar架构,这简直是处理器界的“先知预言”。想法简单却大胆:把一个串行程序切成好几段“任务块”,分发给多个处理单元同时执行。每个块内部严格顺序执行,但块与块之间可以大胆并行,只要硬件能聪明地检测和管理数据依赖。
想象一下,你在组装乐高城堡。传统单核就像一个人一块一块慢慢拼;Multiscalar则是几个人同时拼不同部分,只要提前商量好“这个塔尖依赖那个底座”,就不会出错。这项工作开启了整个领域,后续无数研究都站在它的肩膀上。
{kind=link}
这个架构的魅力在于,它不满足于“多核并行”,而是试图让单线程程序也能“借力”多核。学术界随后演化出多条支线,每一条都像武侠小说里的不同门派,各自钻研“合体”绝技。
🔮 推测多线程(TLS/SpMT):大胆猜测未来的“时间旅行”线程
进入2000年代,推测多线程(Thread-Level Speculation, TLS 或 Speculative Multi-Threading, SpMT)成为热门。核心思路是:把程序切成“猜测线程”,提前在另一个核上跑后面的代码块。如果猜对了,性能飞起;猜错了,就回滚,像电影《终结者》里时间线修正一样。
CMU的Joel Emer团队和UCSD的Dean Tullsen团队都深耕此道。他们发现,许多程序里有大量“可猜测”的并行机会,尤其在循环密集型代码中。比喻来说,这就像你开车去目的地,提前派一辆侦察车走另一条路,如果路好就全队跟上,否则撤回主路。
这种“时间旅行”式的猜测,让单线程性能有了突破可能。但现实中,指针追踪和复杂控制流常常让猜测失败率高企,需要强大的回滚机制。
🏭 Intel Anaphase原型:软硬件混合的“自动分区”尝试
2010年前后,Intel Labs Barcelona推出了Anaphase项目。这是一个实际的原型系统,用软硬件协同方式,把单线程程序自动分区到多核运行。他们专门设计了ICMC模块来处理核间内存一致性,确保数据不乱套。
这个项目像一场精心排练的交响乐:编译器决定“乐章”怎么分,硬件负责实时指挥。实际测试显示,对规整的科学计算代码效果显著,但遇到充满分支和指针的通用软件,就容易“跑调”。这也暴露了早期融合方案的软肋——对程序特性的依赖太强。
🧩 CoreFusion:面积与功耗的“超级核”优化实验
2012年的CoreFusion研究更进一步。结果显示,4个小核融合成的一个“超级核”,能达到8-wide超标量大核相同的单线程IPC(指令每周期),但硅片面积少35%,峰值功耗低28%。这听起来像魔法——用更少的资源办更多事。
比喻一下:四个小厨师合作做一桌大餐,总成本比请一个超级大厨低得多,还能平时分散干活。融合时,他们共享寄存器和执行资源,拆分时又各自高效。
> 注解:IPC是衡量处理器效率的核心指标。CoreFusion通过动态重构核间互联,让小核临时组成大核流水线。这种异构设计在移动芯片中已有雏形,但桌面级通用场景还需要更多一致性保障。
🔄 混合TLS/CoreFusion:2019年的“智能切换”巅峰方案
2019年HPCA会议上,Kim和Yeung的混合方案堪称集大成者。先尝试推测多线程,如果依赖冲突频繁,就切换到核心融合模式。在SPECint2017等基准测试的硬骨头程序上,比纯TLS或纯融合强8-12%。这就像球队战术:进攻时猜球路,防守时全员合体。
他们通过gcc、mcf、omnetpp等真实负载验证,证明融合+猜测的组合拳最灵活。
⚠️ 三大工程难题:为什么“合体”至今难产?
尽管理论诱人,现实却布满荆棘。
第一难题:指令流拆分如走钢丝。 程序里到处是数据依赖,比如a = b + c; d = a * 2;。拆分稍有差池,整个计算就崩盘。硬件必须实时追踪这些“因果链”,延迟稍高就得不偿失。
{kind=link}
第二难题:面积功耗收益贴近临界点。 两个小核面积看似小,但加上通信模块、一致性协议、检查点回滚,总体开销可能反超。2019研究显示,IPC提升15-40%,但额外硬件7-15%,稍有偏差就亏本。
第三难题:编译器与运行时负担沉重。 哪些块能并行?何时融合?这些决策需要极致精准的静态分析或动态预测。Anaphase在循环代码上优秀,在复杂控制流上拉胯。
这些难题让“合体”从梦想走向漫长实验。
📜 Intel SDC专利:2025年的软件定义超级核心新曙光
2025年8月,Intel专利EP4579444A1“Software Defined Super Cores”(SDC)再次点燃希望。它用软件把程序拆成代码块,分给多个小核,通过“影子存储缓冲区”(Shadow Store Buffer)管理数据传递,维持顺序正确性。
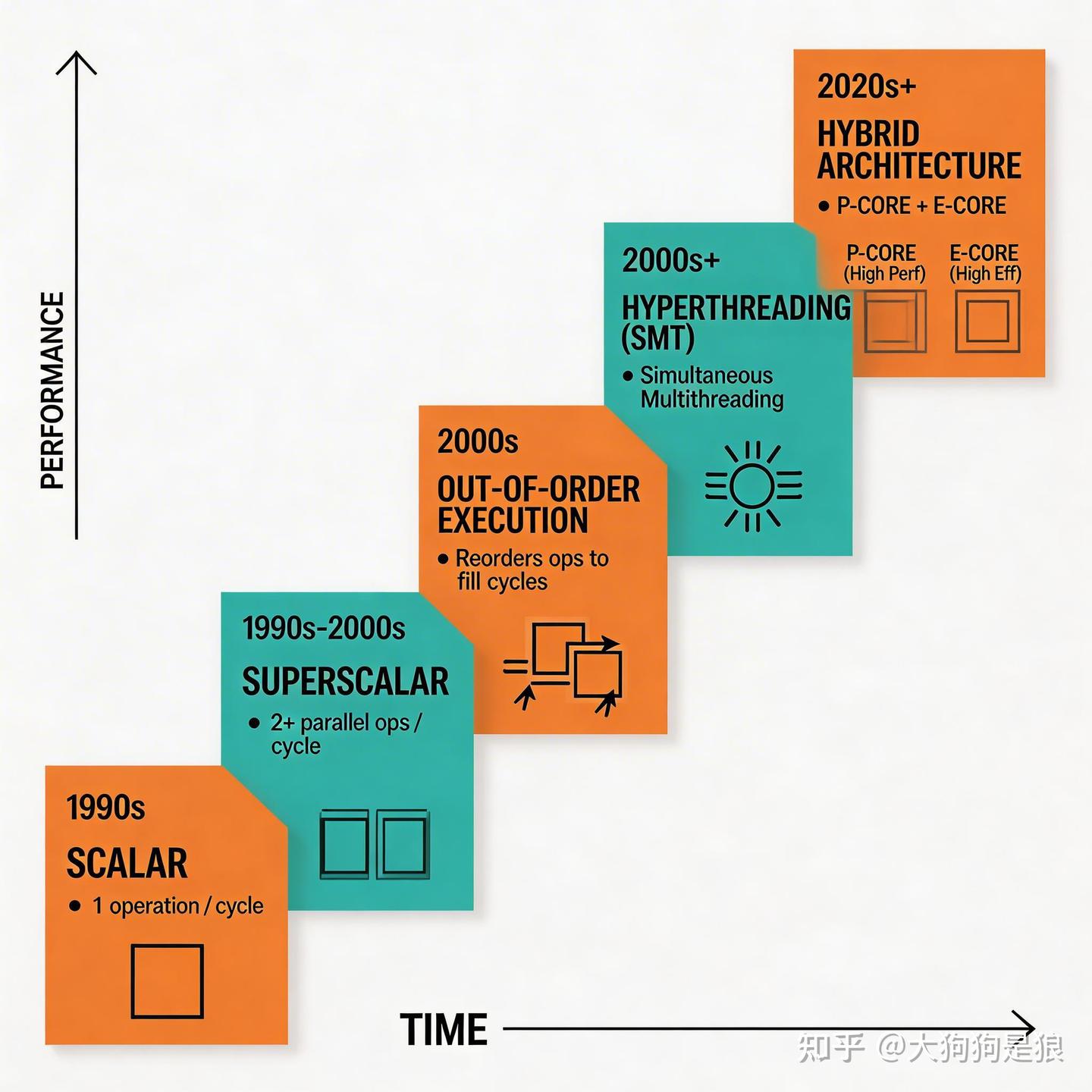
想象未来Titan Lake(2028年)放弃P核、全上E核(最多100个)。SDC让这些E核在单线程高负载时临时“合体”,平时分散节能。这比固定大核灵活太多,像变形金刚而非固定巨人。
{kind=link}
但专利到产品仍有鸿沟。核间通信延迟仍是最大敌人,除非互联架构突破到接近核内寄存器速度,否则仍可能是纸面理想。
🌑 暗硅困境:为什么不直接做更大单核?
工艺到2nm,晶体管越来越多,但功率密度限制让“暗硅”问题凸显——很多晶体管无法同时通电。一个8-wide大核满载可能超100W,4个融合小核只需60W就能接近性能。这就是为什么ARM如联发科天玑9400用大小核组合,而不是一味做超大核。
融合方案在功耗墙时代,提供了一条弯道超车路径。
🏁 结语:值不值的问题,而非能不能
核心融合从来不是“能不能”,而是“值不值”。从Multiscalar到SDC,三十年探索证明:在特定负载上,用小核拼大核性能完全可行,甚至更优。但通用、透明、对所有场景都有净收益的方案,仍待突破。
如果2028年Titan Lake带着SDC落地,那将是处理器设计的大转向——100个小核中,4个突然合体成超级单核,单线程性能将达新高度。在此之前,它仍是学术的课题、工程的苦差、评论区的永恒话题。
(P.S. Intel若真成功,欢迎回来挖坟庆祝!)
------ 参考文献 1. Sohi, G.S., et al. “Multiscalar Processors,” ISCA 1996. 2. “A Survey on Thread-Level Speculation Techniques,” ACM Computing Surveys, 2016. 3. “Boosting Single-thread Performance in Multi-Core Systems” (Intel Anaphase), ISCA 2009. 4. “Comparing Area and Power of Single-ISA Heterogeneous Multi-core Architectures,” IEEE Computer Architecture Letters, 2012. 5. Kim & Yeung, “Exploiting ILP and MLP with Core-Fusion and Thread-Level Speculation,” HPCA 2019.
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens