GFT:SFT不是原罪,而是被用错了——从复制专家到群体对比学习的范式跃迁
> 论文:GFT: From Imitation to Reward Fine-Tuning with Unbiased Group Advantages and Dynamic Coefficient Rectification > arXiv: 2604.14258 | 2026年4月 > 机构:浙江大学 OmniAI Group (ACES Lab) > 代码:https://github.com/ZJU-OmniAI/GFT
---
🔥 一句话总结
GFT 证明了 SFT 的根本问题不是"模仿学习本身错了",而是"模仿的方式太粗暴"——通过把单专家轨迹升级为群体对比学习(GAL)+ 动态梯度稳定(DCR),GFT 用 1/10 的数据量全面碾压标准 SFT,还能给后续 RL 提供更好的冷启动,打破"SFT→RL 协同困境"。
---
🎯 问题:SFT 的两宗"原罪"
论文从一个被忽视的角度重新诊断了 SFT:
> SFT 其实是强化学习的一种退化形式。
把 SFT 梯度写成策略梯度形式,就能看清问题:
$$\nabla_\theta \mathcal{L}_{\text{SFT}} = -\mathbb{E}\left[ \frac{\mathbb{I}[y=y^*]}{\pi_\theta(y|x)} \nabla_\theta \log \pi_\theta(y|x) \right]$$
拆开来看两个致命组件:
原罪一:单路径依赖 → 熵坍缩
| 组件 | 问题 |
|---|---|
| $\mathbb{I}[y=y^*]$ | 奖励极度稀疏:只有完全复制专家才给 1,否则 0 |
| 结果 | 模型只能"复制",不能"比较" → 探索能力归零 → 熵坍缩 |
| 后遗症 | 下游 RL 的 exploration budget 被严重压缩 |
原罪二:逆概率权重 → 梯度爆炸
| 组件 | 问题 | |
|---|---|---|
| $1/\pi_\theta(y | x)$ | 对低概率 token,权重急剧增大 |
| 场景 | 专家用了模型不熟悉的 token,或模型在探索时生成多样化响应 | |
| 结果 | 梯度方差极大 → 机械记忆 → 过拟合 → 灾难性遗忘 |
- SFT 单独训练 → 有提升,但覆盖预训练知识
- GRPO 单独训练 → 有提升
- SFT → GRPO 流水线 → 效果反而弱于 GRPO 单独训练!
⚙️ 核心技术:GFT 的两把手术刀
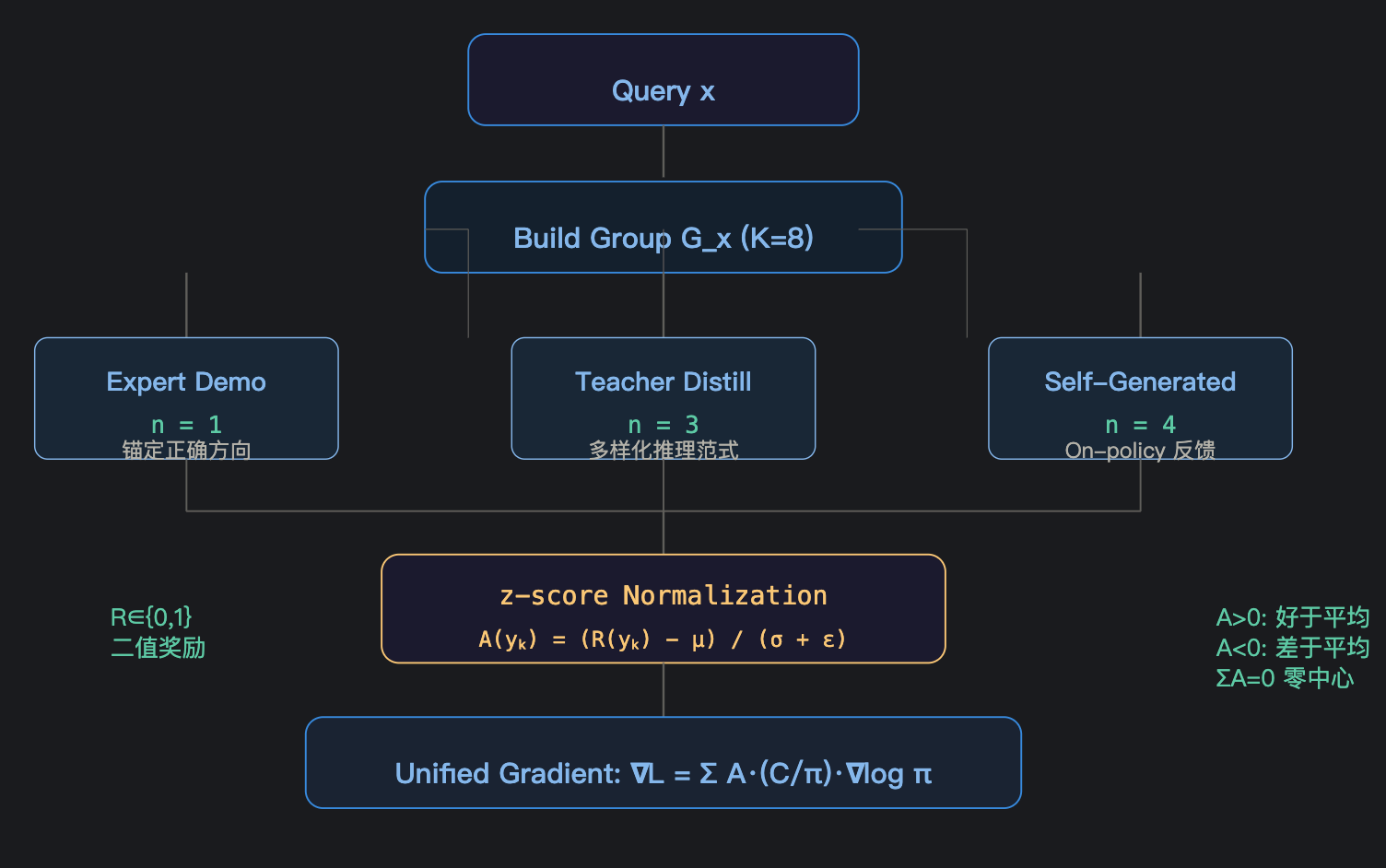
1. GAL(Group Advantage Learning):打破单路径依赖
核心思想:不再只盯着一条专家轨迹,而是构建一个"混合响应群体",让模型在对比中学习。
群体构成(每查询 K=8):
| 来源 | 数量 | 作用 |
|---|---|---|
| 专家演示 | 1 | 锚定正确性,保证方向 |
| 教师蒸馏 | 3 | 引入多样化推理范式 |
| 模型自生成 | 4 | 提供 on-policy 反馈,纠正内在错误 |
$$A(y_k) = \frac{R(y_k) - \mu(\mathcal{G}_x)}{\sigma_R(\mathcal{G}_x) + \epsilon}$$
对比效果:
传统SFT: "这条轨迹是对的,给我复制" → 绝对、稀疏、单一
GAL: "这条轨迹比群体平均好/差多少" → 相对、密集、对比
关键洞察:GAL 不是"不给专家数据",而是"不只给专家数据"。模型在群体中看到了多种可能的解题路径,学会了"什么是对的"以及"为什么比别的好"。
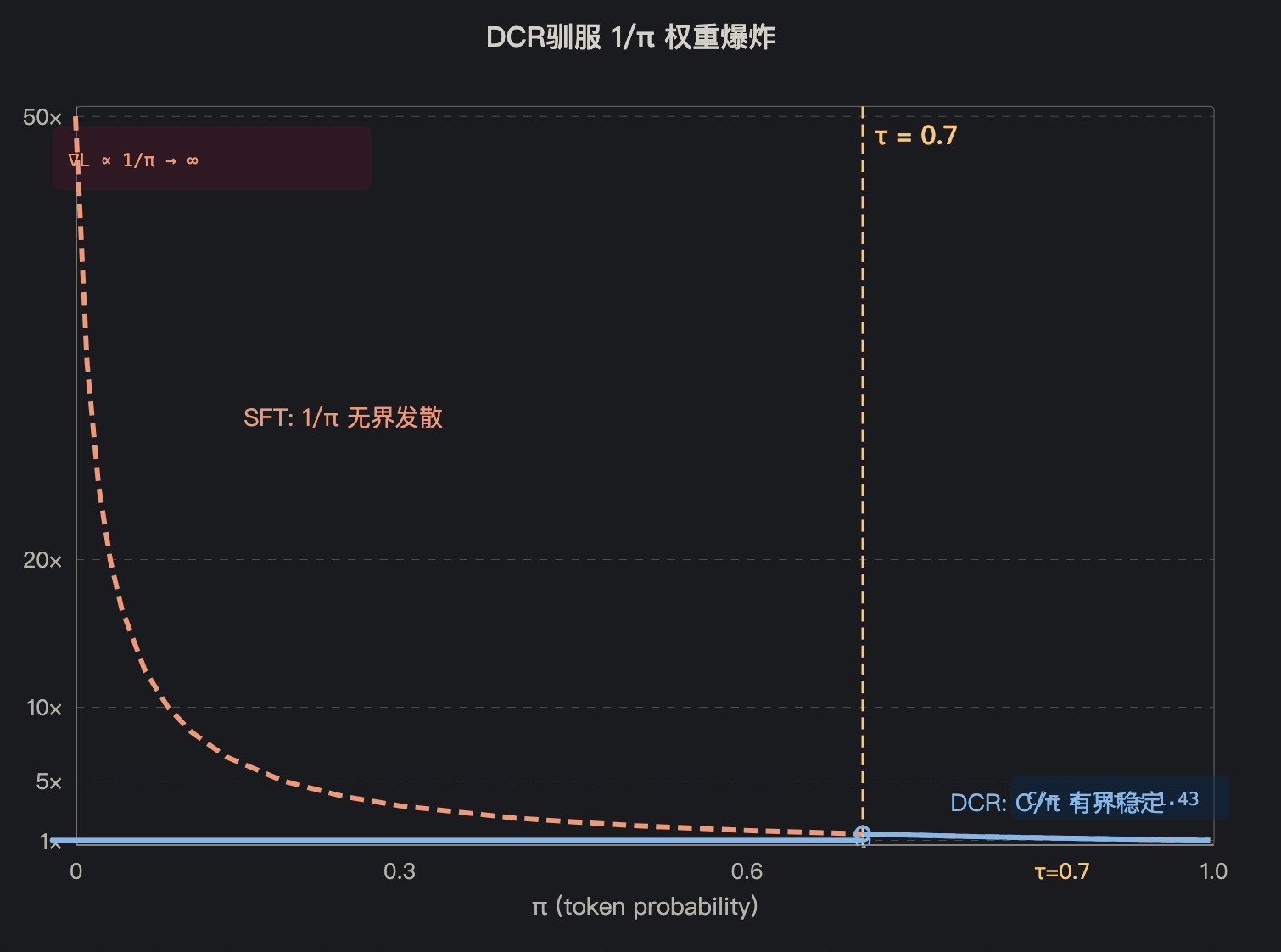
2. DCR(Dynamic Coefficient Rectification):驯服梯度爆炸
核心问题:原始权重 $1/\pi_t$ 在 $\pi_t \to 0$ 时无界增长。
DCR 的自适应裁剪:
$$C(\pi_t) = \begin{cases} \text{sg}(\pi_t) & \text{if } \pi_t < \tau \quad \text{(低置信,阻断爆炸)} \\ 1 & \text{if } \pi_t \geq \tau \quad \text{(高置信,正常学习)} \end{cases}$$
行为分析:
| 概率区间 | 原始权重 $1/\pi_t$ | DCR 行为 | 有效系数 |
|---|---|---|---|
| $\pi_t \geq 0.7$ | 有界 ($\leq 1.43$) | $C(\pi_t) = 1$ | 正常梯度 |
| $\pi_t < 0.7$ | 无界 ($\to \infty$) | $C(\pi_t) = \text{sg}(\pi_t)$ | $\approx 1$(常数) |
3. 统一训练目标
$$\nabla_\theta \mathcal{L} = \mathbb{E}_{y_k \in \mathcal{G}_x} \left[ A(y_k) \frac{C(\pi_\theta(y_k|x))}{\pi_\theta(y_k|x)} \nabla_\theta \log \pi_\theta(y_k|x) \right]$$
三要素合一:
- $A(y_k)$:标准化优势(GAL 给的对比信号)
- $C(\pi)/\pi$:矫正后的稳定权重(DCR 给的梯度保险)
- $\nabla \log \pi$:标准策略梯度
📊 实验:数据效率 10×,全面碾压
主结果(Qwen2.5-Math-1.5B)
| 方法 | AMC23 | College Math | MATH | Minerva | TabMWP |
|---|---|---|---|---|---|
| Base | 30.16 | 24.30 | 46.54 | 10.51 | 24.55 |
| +SFT (100k样本) | 31.25 | 36.45 | 60.66 | 23.99 | 79.34 |
| +GRPO | 44.84 | 35.58 | 65.97 | 21.17 | 76.94 |
| +DFT | 36.40 | 38.76 | 64.35 | 23.75 | 82.08 |
| +GFT (10k查询=80k样本) | 46.09 | 40.51 | 70.50 | 28.93 | 85.24 |
- GFT 用 1/10 的数据量,全面超越 100k 样本的 SFT
- GFT 甚至超越了 GRPO(46.09 vs 44.84 on AMC23)
- 混合数据不是主因:GFT(no mix) ≈ GFT,SFT(mix) ≈ SFT——增益来自机制
消融实验
| 变体 | AMC23 | MATH | Olympiad |
|---|---|---|---|
| 去掉 GAL + DCR = SFT | 31.25 | 60.66 | 24.58 |
| 去掉 GAL(仅 DCR) | 35.78 | 63.91 | 26.63 |
| 去掉 DCR(仅 GAL) | 42.81 | 65.97 | 27.82 |
| 完整 GFT | 46.09 | 70.50 | 30.52 |
与 RL 的兼容性(最亮眼的结果)
| 流水线 | 效果 |
|---|---|
| SFT → GRPO | 中等,协同不佳("synergy dilemma") |
| GFT → GRPO | 更好,GAL 保留了探索空间 |
| SFT → GFT → GRPO | 最佳天花板 |
- SFT:提供可靠的初始化点和格式对齐
- GFT:恢复探索能力,防止分布漂移
- GRPO:利用高质量轨迹达到性能天花板
灾难性遗忘分析
LLaMA-3.2-3B 在通用推理基准:
| 方法 | MAWPS | SVAMP | MMLU-STEM |
|---|---|---|---|
| Base | 96.06 | 86.36 | 41.03 |
| +SFT | 91.97 (-4.09) | 78.73 (-7.63) | 35.05 (-5.98) |
| +GRPO | 94.60 (-1.46) | 88.11 (+1.75) | 39.48 (-1.55) |
| +GFT | 95.79 (-0.27) | 84.65 (-1.71) | 43.89 (+2.86) |
---
🧠 深度解读:GFT 为什么有效?
1. SFT 的重新定位
GFT 最大的理论贡献是把 SFT 从"独立的训练阶段"重新定义为"RL 的退化形式"。这个视角转换让问题的诊断和治疗都变得清晰:
- 问题不是"SFT 不好",而是"SFT 的优化方式有缺陷"
- 治疗不是"扔掉 SFT",而是"修复 SFT 的优化方式"
2. 群体学习的"对比效应"
GAL 的灵感来自人类学习:一个学生只看一个标准答案,容易机械记忆;但让他看到多个解法(有对有错、有繁有简),他会真正理解"什么是对的以及为什么"。
教师蒸馏样本的作用尤其精妙——它引入了不同于专家的推理范式,打破了"只有一种正确写法"的错觉。
3. DCR 的"边界感"
DCR 的设计很像育儿:
- 孩子自信时(高概率 token)→ 让他自己尝试
- 孩子迷茫时(低概率 token)→ 搭把手,但别替他做(阻断梯度爆炸,但保留学习信号)
4. 与 SFT 变体的关系
| 方法 | 核心思路 | 与 GFT 的关系 |
|---|---|---|
| DFT | 蒸馏反馈调优 | 也用了多样化响应,但没有群体对比和梯度矫正 |
| ASFT | 基于原型的 SFT | 用多个原型,但没有标准化优势机制 |
| GRPO | 群体相对策略优化 | 纯 RL,没有利用专家演示的锚定作用 |
| GFT | 群体对比 + 梯度稳定 | 统一了模仿和强化,两者优势兼得 |
⚠️ 局限与延伸
1. 群体构建的成本:每查询需要 K=8 个响应,推理成本是 SFT 的 8 倍。虽然训练数据量减少到 1/10,但单次前向传播的成本增加了。如何在成本和效果之间取舍?
2. 教师模型的依赖:GFT 依赖教师蒸馏样本的质量。如果教师模型本身有偏见或错误,会被传播到群体中。
3. 非数学任务的验证:论文主要在数学推理上验证。在创意写作、多轮对话、代码生成等任务上,GAL 的群体对比机制是否同样有效?
4. 阈值 $\tau$ 的泛化:$\tau=0.7$ 在数学任务上最优,在其他任务上是否需要调整?能否让 $\tau$ 自适应学习?
---
🔗 相关阅读
- 论文原文:arXiv:2604.14258
- 对比基线:
- SFT / SFT(mix) — 标准监督微调
- DFT — Distillation Feedback Tuning
- ASFT — 基于原型的 SFT
- GRPO — 群体相对策略优化
- 数据集:NuminaMath CoT(高中到国际奥赛级别)
> GFT 的核心启示:SFT 不该被放弃,而是该被升级。 模仿学习和强化学习不是非此即彼的关系——通过群体对比和梯度稳定,可以在一个统一的框架里同时获得两者的优势。这不仅是算法的进步,更是对"如何教AI学习"这个问题的一次重新思考。
#GFT #监督微调 #群体学习 #强化学习 #梯度稳定 #灾难性遗忘 #数学推理 #论文解读 #AI研究 #大语言模型
{kind=link}
{kind=link}
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens