想象一下,你正站在2011年的硅谷街头,空气中弥漫着晶圆厂的焦香味。一枚小小的芯片即将改变整个PC世界的游戏规则——它不再只是冷冰冰的计算核心,还藏着一颗会画画、会打游戏的心脏。从那一刻起,Intel的核显开始了它长达十五年的史诗征程:从被嘲笑的“够用党”到如今让片上最强GPU的王者,它像一个沉默寡言的少年,一步步长成让对手胆寒的巨人。今天,就让我们一起翻开这本像素编年史,看看Intel是如何一次次打破桎梏的。
🌱 砂桥的黎明:核显从此不再是配角
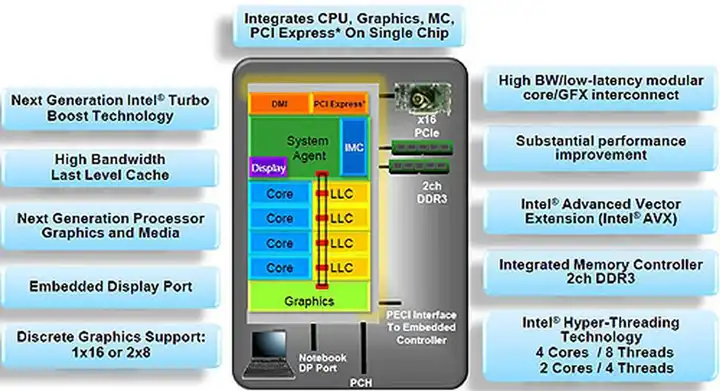
2011年,Sandy Bridge横空出世。这不是一次简单的制程升级,而是Intel对“CPU该长什么样”的一次彻底重塑。32nm工艺下,CPU、内存控制器、PCIe总线,甚至GPU核心,全都被塞进同一块die里。想象一下,就像把客厅、厨房、卧室和游戏房全部挤进一间公寓——SoC化的时代正式开启。
{kind=link}
这一代的Gen6核显(主流GT2配置)虽然只有12个执行单元,但已经足够在1080p下流畅运行《英雄联盟》和《魔兽世界》。更重要的是,它让“集成显卡”这个带着贬义的词彻底改名——从此叫“核心显卡”。很多人以为核显是AMD APU的首创,但Sandy Bridge和首款APU Llano几乎同期发布,Intel甚至更快一步把完整PCIe通道和GPU整合进Ring Bus架构。从此,X86核显战场正式拉开帷幕:你来我往,互不相让。
> Ring Bus是什么? > 想象CPU内部是一座环形高速公路,数据像车辆一样高速流动。Sandy Bridge首创的Ring Bus让CPU核心、GPU核心、内存控制器共享这条高速路,避免了以往北桥南桥时代的拥堵。这也是Intel后续十几年核显性能的根基。
🚀 哈斯维尔的野心:大核显与晶体缓存的第一次狂想
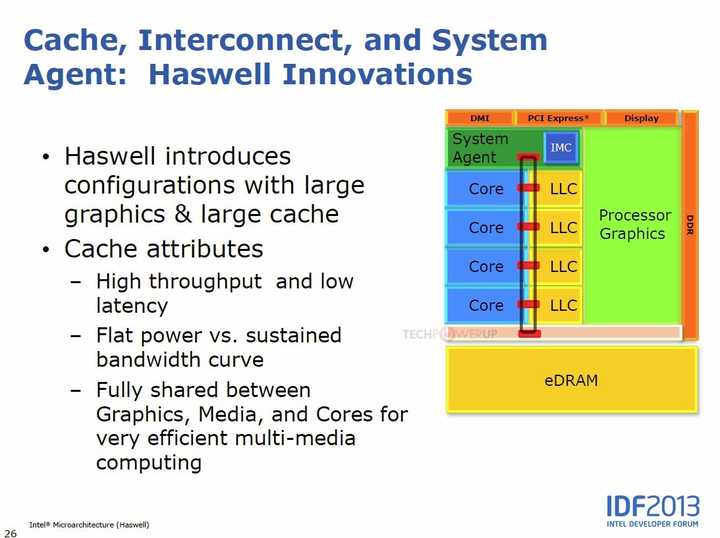
Gen7(Ivy Bridge)只是小修小补,真正的狂欢在Haswell时代到来。得益于与苹果MacBook的深度绑定,Intel首次推出了Iris Pro GT3e——执行单元直接翻倍到40个,外加128MB eDRAM晶体缓存。
{kind=link}
这块eDRAM就像给GPU配了一个私人高速缓存库,既能被GPU独享,也能被CPU调用,实质上已成为最早的L4缓存。游戏帧数直接暴涨30-50%,在当时堪称“X3D鼻祖”。Broadwell时期的Crystal Well机型至今仍是二手市场香饽饽,跑老游戏丝滑得像涂了黄油。
这段时期,Intel第一次尝到“大核显”的甜头:只要内存带宽跟得上,GPU规模翻倍带来的性能提升是线性的。这为后来的GT4e埋下了伏笔。
🔥 Skylake的持久战:又大又持久的Gen9绝唱
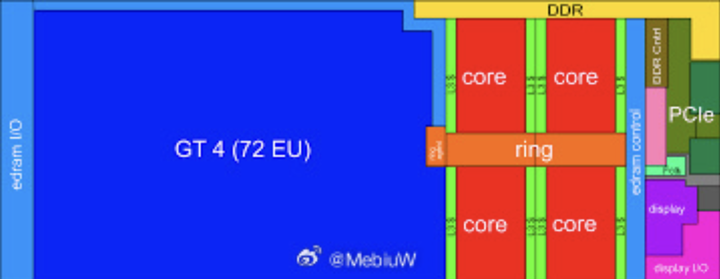
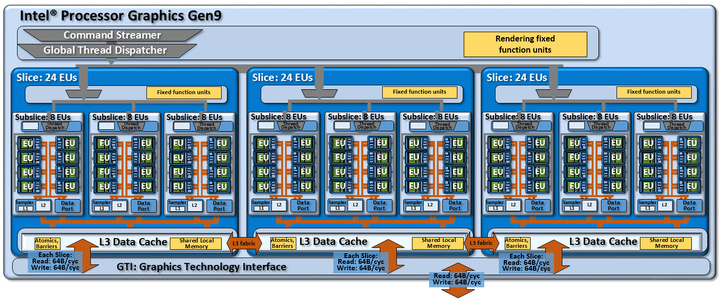
如果说Haswell是试水,那Skylake时代的Gen9就是Intel核显的巅峰狂欢。14nm工艺虽然饱受诟病,但Gen9却借此实现了史上最大规模的集成GPU——GT4e足足72个执行单元(GT2的三倍!),堪称“Strix Halo的祖师爷”。
{kind=link}
{kind=link}
这一代核显性能强到让苹果都坐不住了——MacBook Pro一度用Iris Pro 580跑《守望先锋》都能中高特效。但也正因14nm工艺的持久,Gen9陪我们走了整整六代处理器,从Skylake到Coffee Lake再到Comet Lake,持久得让人又爱又恨。苹果最终选择自研M1,也与这段“又大又持久”的合作经历不无关系。
💔 Gen10的隐身:被族谱除名的葫芦娃老六
2018年,Cannon Lake作为Intel首款10nm处理器姗姗来迟,却只推出了单款低压型号i3-8121U。更离谱的是,它的Gen10 GPU被直接物理屏蔽——官方解释是“良率问题”。于是Gen10成了Intel历史上最神秘的核显,连实机跑分都屈指可数。
{kind=link}
就像葫芦娃里会隐身的老六,Gen10明明存在,却谁也看不见。它提醒了Intel一个残酷的事实:工艺不成熟,再好的架构也是空中楼阁。
⚔️ Ice Lake的逆袭:GT2也能打的年代
痛定思痛,Ice Lake的Gen11核显彻底放弃了大规模路线,转而深耕GT2配置。但这一次,Intel把64个执行单元塞进10nm工艺,频率、架构、效率全面升级,性能直逼上一代GT4。
{kind=link}
从此,Intel不再需要GT3/GT4来对抗AMD,GT2就够了。这是一个战略转折:与其追求规模,不如精雕细琢架构与工艺。从Ice Lake开始,Intel核显与AMD核显的对比变成了一场“你超我,我超你”的拉锯战,谁先更新架构谁就领先半年。
🛡️ Xe LP的持久临时工:96EU的黄金时代
Tiger Lake首发的Xe LP(业内仍称Gen12)将GT2规模推到96EU,一举成为当时最强核显。UHD Graphics不再是笑话,而是能吊打AMD Vega 8的存在。
{kind=link}
可惜这个辉煌被后续的Alder Lake、Raptor Lake原地踏步拖垮——14代酷睿至今仍在用96EU的Xe LP。但正是这段“临时工”生涯,让Intel积累了宝贵的低功耗高性能经验,为后面的ARC独立显卡铺路。
🃏 炼金术士的觉醒:Xe LPG与AI核显时代
Meteor Lake带来品牌大变革:Core Ultra + ARC核显。Xe LPG虽然官方仍归为Gen12.7,但架构已天翻地覆——告别Ring Bus,改用Tile胶水设计,GPU Tile甚至外包给台积电制造。
{kind=link}
{kind=link}
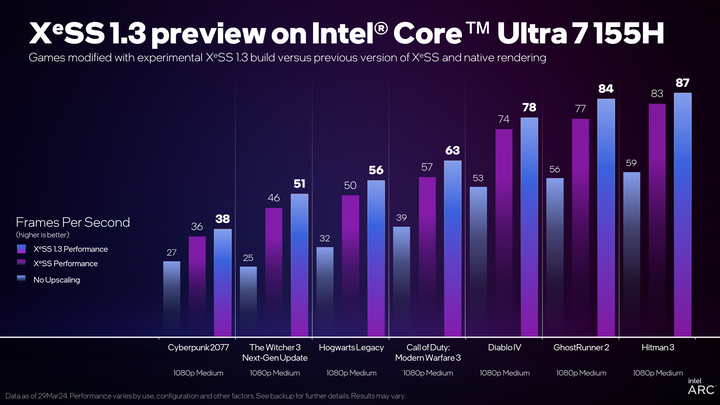
128EU、XeSS超采样、完整XMX矩阵单元、AV1编码……Xe LPG在光追、AI、媒体处理上全面碾压AMD同期RDNA2/3核显。即使光栅性能略有争议,但在生产力与AI场景下,Intel核显第一次实现了“全面领先”。
🌙 战斗法师的绝唱:Lunar Lake的极致效率
Lunar Lake的Xe2核显(Battlemage)用台积电N3B工艺,将效率推向极致。低功耗下至今无敌,高功耗受限于15-30W封顶,未能完全展现实力。
{kind=link}
不过Xe2在光追、纹理性能、驱动稳定性上都有明显进步,主战场终究是独显Battlemage,而非核显。
🐆 豹湖的王座:Xe3时代优势空前
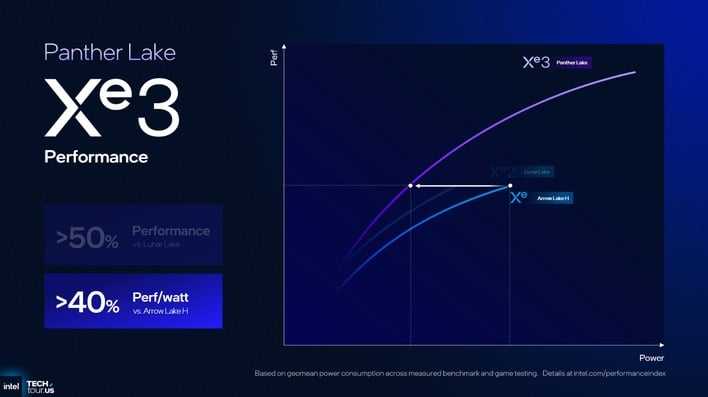
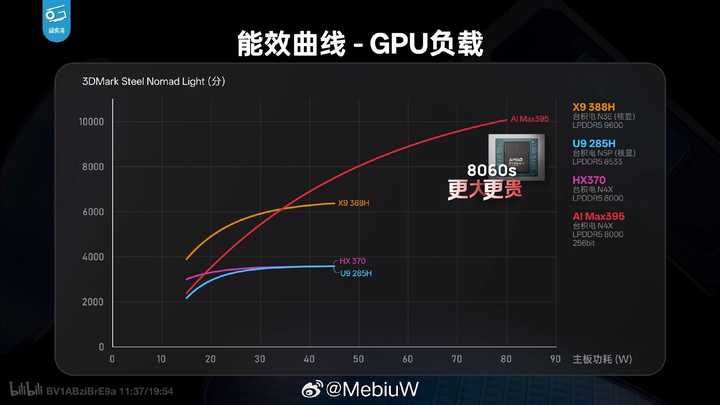
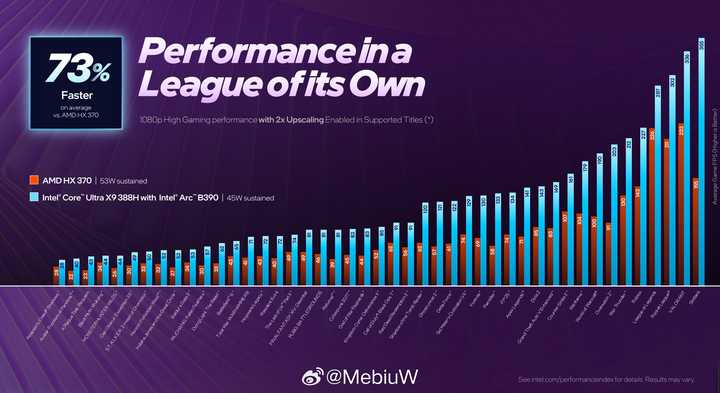
Panther Lake的Xe3(Celestial)用上了N3E工艺、50%规模提升、架构大改,终于让Intel核显在光栅性能上也实现全面碾压。H45功率段内,AMD的RDNA3.5彻底失去还手之力。
!Panther Lake Xe3预览 !性能挤牙膏真相 !H45实测碾压 !标准定位对比
{kind=link}
{kind=link}
{kind=link}
{kind=link}
早期PPT挤牙膏式的40%提升被实测数据无情打脸——实际游戏性能领先AMD同级别产品50-80%。Xe3时代,Intel核显的优势从未如此明显。
🔮 Xe3P的未来:AI推理的下一战
Nova Lake预计搭载Xe3P,将补齐低精度FP4/FP8支持,结合XeSS 4.5有望进一步降低AI超采样开销。矩阵加速的全面进化,将让Intel核显在AI创作、游戏帧生成领域继续扩大优势。
!Xe3P FP4支持 !Crescent Island展望
{kind=link}
{kind=link}
尾声:像素帝国的真正主人
十五年,从Gen6的12EU到Xe3的潜在12+Xe核,Intel从未真正挤过牙膏。每一次有条件更新,它都毫不犹豫地堆工艺、刷架构、加特性。相比某些对手的“祖传古董”与“倒吸规模”,Intel的态度更像一位真正的战士——该上的时候绝不含糊。
核显的王座,从来不是天上掉下来的,而是Intel用一代又一代芯片,一点一点铸就的。
-----
参考文献
1. Intel官方架构白皮书(Sandy Bridge至Panther Lake系列) 2. AnandTech & Tom's Hardware历年核显评测合集 3. Intel ARC & Core Ultra技术深潜报告 4. Chips and Cheese对Xe3微架构分析 5. 知乎用户“weibo_mebiuw”原创整理(本文主要参考来源)
{kind=link}
{kind=link}
{kind=link}