失忆的艺术:为什么2025年最聪明的AI代理,都在拼命“删代码”
🌱 从“喂得越多越聪明”到“塞得越满越蠢”:一个反直觉的觉醒时刻
想象一下,你正在给一个天才大脑喂饭。你以为盘子越大、菜越多,它就越聪明。于是你端上来满满一桌子菜:昨天的聊天记录、上周的代码、去年写的文档、甚至连WiFi密码都塞进去。结果呢?这个天才开始结巴、犯迷糊、把盐当成糖撒进咖啡里。
这不是科幻,而是2024-2025年无数AI代理团队真实经历的惨剧。 Hugging Face的机器学习工程师Philipp Schmid前几周听完Manus AI和LangChain的两场闭门分享后,彻底被震撼了——Manus团队把自己的代理系统重写了整整五次,最后发现最有效的改动永远是那两个字:
删代码。
是的,你没听错。 不是加功能,不是换更大的模型,不是把上下文窗口从12.8万撑到100万。 而是删。删到出血,删到心疼,删到整个系统突然就“活”了。
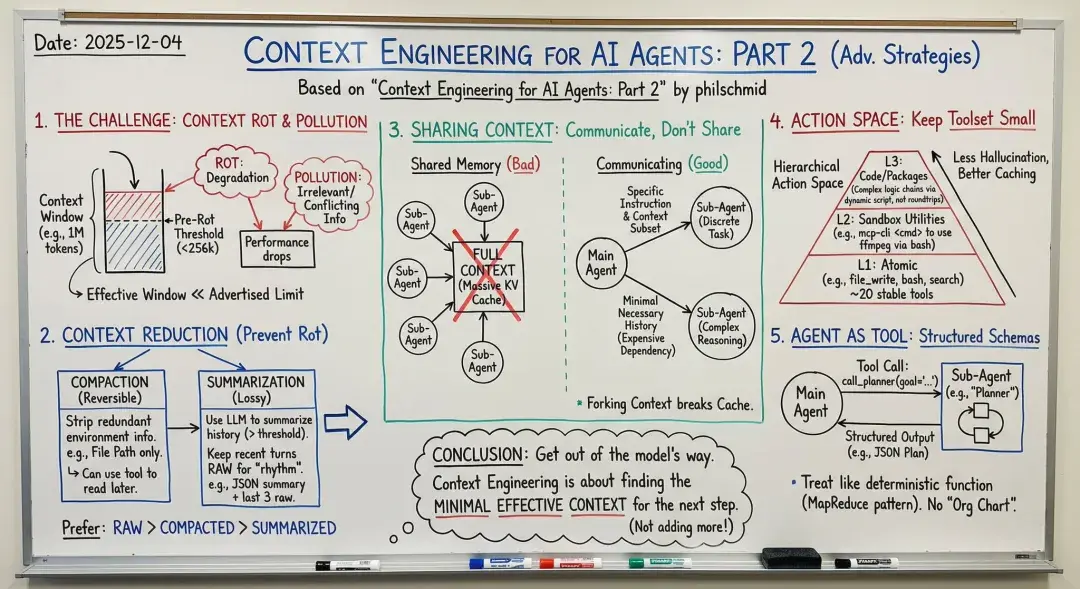
🧠 上下文会像牛奶一样变质:一个被遗忘的残酷真相
我们总以为上下文窗口是冰箱——放进去就永远新鲜。 错!它更像一盒没盖盖的牛奶,放在常温下。
研究和实战都证明:即使是最强的模型,当上下文超过20-30万token后,性能也会像自由落体一样崩塌。中间那段信息会变成“毒瘤”,模型会莫名其妙忘记自己三分钟前刚说过的话。这就是社区现在流行的新名词——Context Rot(上下文腐败)。
> 上下文腐败的典型症状: > - 把问题答偏到十万八千里 > - 突然开始循环输出同一段废话 > - 明明文件已经写好,却死活找不到路径 > - 最致命:把正确答案埋在第157页历史里,然后自信地说“没有找到”
Manus的工程师们用血泪总结出一句话: “给模型刚好够用的信息,比给它全世界都更重要。”
🔥 Manus的“三板斧”:删到骨头里,才看到灵魂
🗑️ 第一板斧:能删就删,能总结就总结,绝不心软
他们发现最有效的上下文瘦身术只有两条:
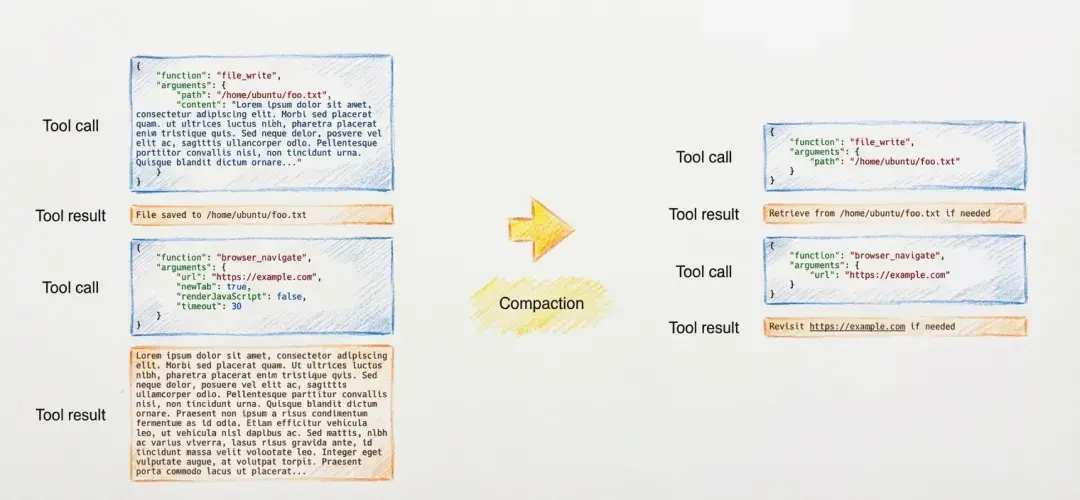
1. 存在硬盘上的东西,坚决不留在内存里 AI写了500行代码?立刻存文件,聊天记录里只留一句“代码已保存至./agent/output_v3.py”。需要的时候再读回来。 这就像你家厨房做完菜立刻洗碗,而不是把所有脏盘子堆在桌子上等下次用。
2. 上下文太长?强制让AI给自己做减法总结 但这里有个绝妙的小技巧: 永远保留最近3轮完整对话。 为什么是3轮?因为这能让模型保持“手感”,就像篮球运动员热身时最后三投必须进框一样,否则手感就断了。
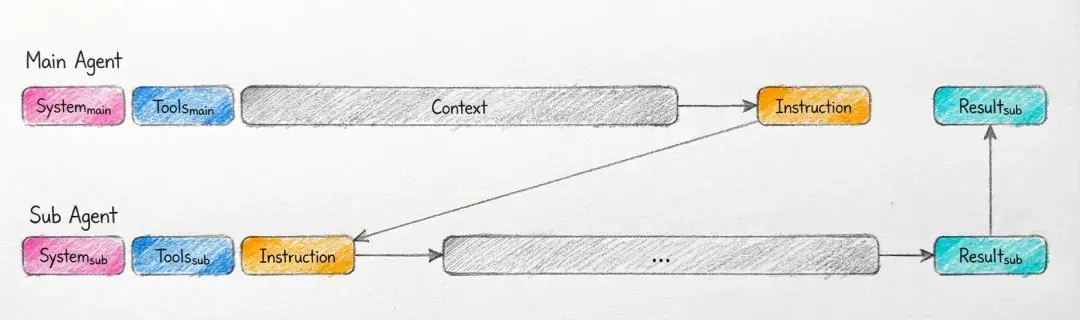
🧊 第二板斧:别让所有AI共用一个大脑
最容易翻车的多代理系统,就是所有人抢同一个共享内存。 A在想代码,B突然插进来一句“用户说想加个暗黑模式”,结果A的整个思路全崩。
Manus直接抄了Go语言那句名言: “通过通信共享内存,而不是通过共享内存通信。”(Share memory by communicating, not communicate by sharing memory.)
具体做法简单粗暴: 每个子代理有自己独立的上下文,主控Agent只通过结构化消息(JSON)跟他们对话。 就像公司开会,不是每个人都坐在一个大会议室里吵,而是用Slack发消息,干净、清晰、不串味。
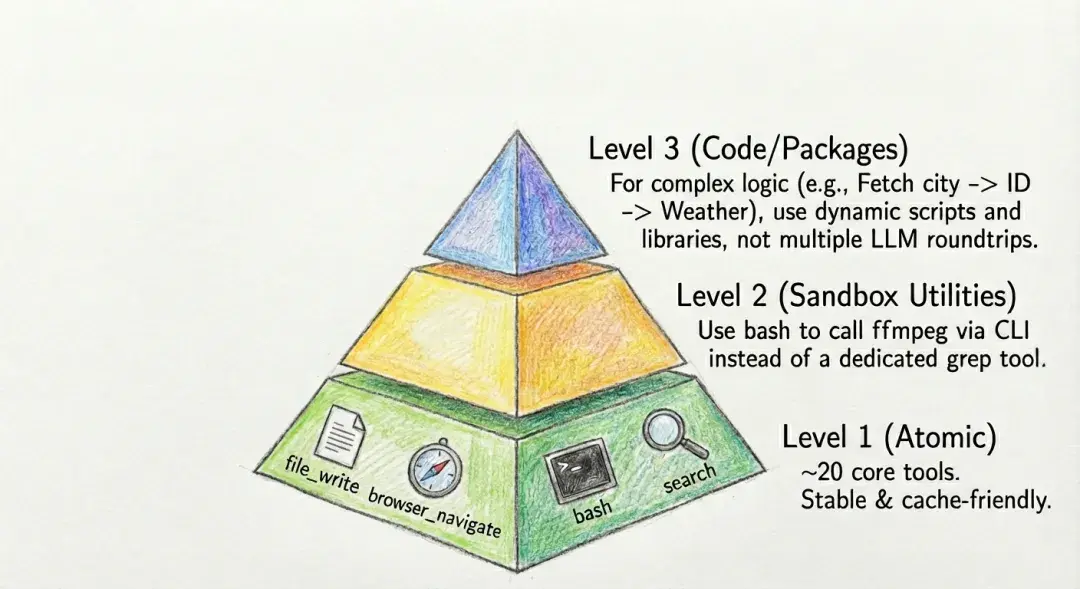
🔧 第三板斧:工具越少越好,越简单越好,越傻越好
给AI 100个工具 = 给一个三岁小孩100把刀。 它一定会拿错,还可能砍到自己。
Manus最终的工具策略只有三层,金字塔一样稳:
1. 最底层:20个最基础的工具(读文件、写文件、运行命令、搜索等) 2. 中间层:根本不定义工具,直接让AI用命令行!(对,就是bash) 3. 最顶层:复杂功能直接打包成Python代码库,一次性import解决
他们甚至把“搜索arxiv”“生成图表”这种常见操作,直接写成一个叫research.py的库,AI需要的时候就import research; research.run(query)——干净、确定性极高、不会用错。
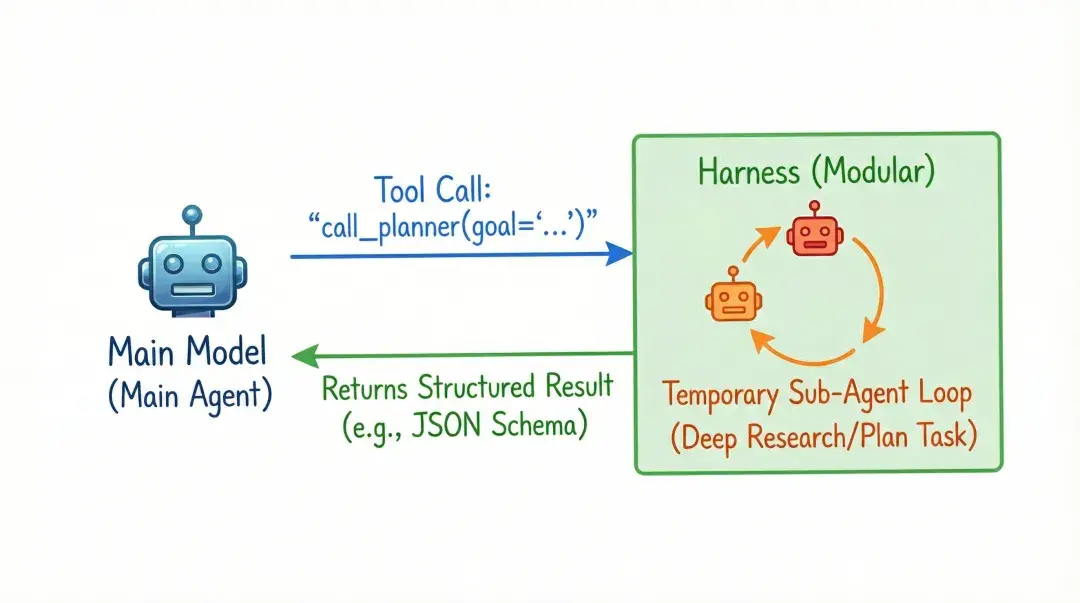
🤖 把AI当函数调用,别当同事开会
很多人喜欢给每个子代理起名字:Planner、Researcher、Critic、Executor…… 然后让它们像真人一样在群聊里吵架。
Schmid在博客里直接开喷: “这是最愚蠢的过度拟人化。”
正确的打开方式: 把子代理当成纯函数。 主Agent只管一句:
result = call_researcher(goal="帮我查2025年最新长上下文技术")
就像你调用requests.get(),永远不会返回“我正在思考要不要给你数据哦~”。
💰 删完之后,世界突然清晰了
有开发者按照这套思路重构,花了三次才稳定,但最终结果是: Token消耗下降40%,稳定性大幅提升,bug数量肉眼可见减少。
这不是小数字。 对一个日调用百万次的代理系统来说,40%意味着真金白银的服务器费用,更意味着用户体验从“偶尔抽风”变成“永远可靠”。
🎯 2025年的六条“删代码”戒律(实用清单)
1. 永远监控上下文长度,超过12万token就报警 2. 所有文件、代码、搜索结果,写盘,绝不留内存 3. 每个代理独立上下文,只通过消息通信 4. 工具能少则少,能蠢则蠢,确定性比智能更重要 5. 子代理必须返回结构化数据,像API一样冷酷无情 6. 定期删代码!删掉复杂的路由、删掉多余的管理层、删掉一切让你“觉得很酷”的东西
正如LangChain的Lance Martin在2025年开年说的那句名言:
> “2025年最好的AI系统,不是能吃下100万token的怪物, > 而是用5万token就能完美解决问题的极简主义者。”
删,是最高级的加法。 少,即是多。
当所有人都在卷参数、卷上下文窗口、卷工具链的时候, 真正领先的团队,已经在悄悄练习一门新武功—— 失忆的艺术。
---
参考文献
1. Philipp Schmid. How Manus AI Learned to Stop Worrying and Love Deleting Code [EB/OL]. Hugging Face Blog, 2025. 2. AI智能体的上下文工程:Manus的构建心得 [EB/OL]. https://mp.weixin.qq.com/s?__biz=MzA5MTIxNTY4MQ==&mid=2461153168&idx=1&sn=0a916373534eefe733461c5965157f9d&scene=21#wechat_redirect 3. 上下文管理:从Agent失效到高效运行的完整指南 [EB/OL]. https://mp.weixin.qq.com/s?__biz=MzA5MTIxNTY4MQ==&mid=2461153448&idx=1&sn=929bc72cbd00425d411ac8d3fe0e9ecd&scene=21#wechat_redirect 4. Lance Martin. The Future of Agents: Less is More [R]. LangChain Internal Summit, 2025. 5. Rob Pike. Concurrency is not Parallelism [R]. Go Proverbs, 2012.(Manus引用来源)🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens