🧠 记忆的量子跃迁:AI从遗忘症患者到永恒守护者的奇幻之旅
想象一下,你正站在一座古老的图书馆里,四周堆满了无数卷轴,每一卷都记录着人类知识的片段。但当你试图回溯一年前读过的章节时,脑海中却只剩模糊的影子——这就是AI模型在面对长序列时的尴尬处境。Transformer,这位AI界的“超级英雄”,自2017年由谷歌一手推出后,风靡全球,却也暴露了致命弱点:它的注意力机制像个贪婪的收藏家,总想同时盯住所有物品,导致计算成本如滚雪球般膨胀(O(N²)复杂度)。如今,谷歌卷土重来,在NeurIPS 2025大会上扔出两记重拳:Titans 和 MIRAS。这不仅仅是技术升级,更像一场科幻小说般的革命——让AI在推理时“活学活用”,将上下文窗口轰然扩展至200万token。别担心,我们将像侦探一样,一步步揭开这个谜团,用生动故事和比喻带你穿越AI的“记忆迷宫”。准备好了吗?让我们从Transformer的“瓶颈危机”开始这场冒险。
#### 🔍 Transformer的隐秘枷锁:为什么长上下文成了AI的阿喀琉斯之踵?
回想Transformer的诞生,它就像一个高效的会议协调员:每个token(想想它是个小信息颗粒)通过自注意力机制,瞬间“对话”全场其他颗粒,捕捉全局依赖。这听起来完美,但现实中呢?当序列长度从几百token飙升到数万,甚至百万时,计算量呈平方爆炸——内存和时间成本直线上升,仿佛你请了上千客人聚会,却得每人一对一闲聊。学术界早已警铃大作:共识是,自注意力虽强大,却在超长上下文上力不从心。
为了破解这个谜题,研究者们像探险家般四处寻宝。线性循环网络(RNNs)登场了,它将上下文压缩成固定大小的“背包”,实现O(N)线性扩展——速度飞快,却像背了个盲人背包,偶尔遗漏关键线索。状态空间模型(SSMs)紧随其后,进一步优化了信息流动,但仍无法尽数捕捉序列中的“珍珠”。这些方案各有千秋,却总在“速度 vs. 性能”的天平上摇摆不定。谷歌的Titans + MIRAS,则是这场探险的转折点:它们不只是修补旧船,而是打造一艘能“自愈”的太空飞船,将RNN的速度与Transformer的洞察力融为一体。核心秘诀?测试时训练(Test-Time Training),让模型在推理阶段像活人般学习,动态整合信息,而非死记硬背。这就好比你的手机不只存储照片,还能在翻看时自动生成故事摘要,帮助你重温往昔。
> > 注解:自注意力机制(Self-Attention)的深层剖析 > > 自注意力是Transformer的核心引擎,它计算每个token与其他token的关联权重,公式简而言之是$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$,其中Q(查询)、K(键)和V(值)是输入的线性变换,$d_k$是维度用于缩放防止梯度爆炸。这机制强大,能并行处理序列,但代价高昂:在N=200万token时,QK^T矩阵需O(N²)空间,相当于存储一座数字城市的数据。应用场景如长文档总结,它能捕捉“开头意图与结尾行动”的远距依赖,但对资源有限的设备(如手机AI)而言,却如饮鸩止渴。扩展来说,这启发我们:未来AI需像人类大脑般“选择性关注”,而非全盘扫描,以平衡效率与深度。
过渡到Titans,我们将看到这个“工具箱”如何化被动为主动,让AI的记忆从“仓库”变成“活的日记”。
#### 🛡️ Titans的守护之盾:动态记忆模块,如何让AI“永不遗忘”?
Titans不是科幻道具,而是谷歌工程师的实战武器——一个融合RNN迅捷与Transformer智慧的全新架构。其心脏是神经长期记忆模块(Neural Long-Term Memory Module),不同于传统RNN的静态向量(像个固定抽屉,只塞得下有限东西),这个模块是个在测试时动态更新的多层感知机(MLP)。MLP你可以用想象:它像大脑中的神经元网络,能根据输入实时调整“权重”,让模型在推理中“成长”而非僵化。Titans的核心创新在于“测试时记忆”(Test-Time Memory),无需离线重训,就能让AI像海绵般吸收新知,维持长期连贯性。
拿MAC(Memory as Context) 变体来说,这是Titans的明星玩法。它没动注意力机制的“筋骨”,而是换了“血脉”:将长期记忆提炼成“历史摘要”,直接喂给注意力层,与当前短期输入“联姻”。想象你读一本厚书,MAC就是你的“智能书签”——它不重读全书,而是从记忆中捞出关键片段(如“主角的童年创伤”),与当下章节融合,避免遗漏剧情转折。研究显示,这种设计大幅提升模型表达力:在不丢关键上下文的前提下,概括海量信息如探囊取物。
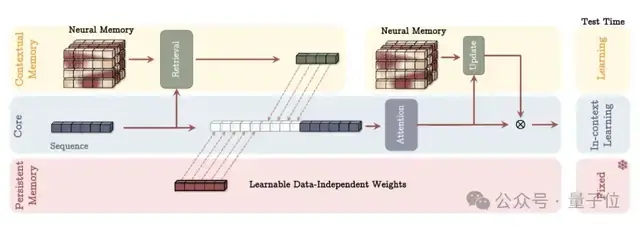{kind=link}
> > 上图展示了MAC的优雅流程:左侧是输入序列,中间记忆模块动态更新,右侧注意力层融合输出。注意箭头表示“惊喜指标”的流动,这让抽象的MLP变得可视化——它不是死板的计算,而是活的对话。
但Titans的真正魔力,在于它对“意外”的敏感嗅觉。借鉴人类心理学(我们对突发事件记忆犹新,如儿时滑倒的痛楚),研究者引入惊喜指标(Surprise Metric):量化新输入与现有记忆的“偏差”。低惊喜时(如报告中多一句“利润上升”,模型已预测到),它仅短期存储,高效省力;高惊喜时(如严肃财报中冒出香蕉皮照,象征意外转折),则优先刻入长期记忆。公式上,这可用KL散度近似:$Surprise = D_{KL}(P_{new} || P_{memory})$,其中$P_{new}$是新输入分布,$P_{memory}$是记忆先验——高值触发深度更新。
这种“选择性遗忘”让Titans在“大海捞针”任务中闪耀:实验中,它轻松扩展上下文至200万token,准确率碾压基线模型。想想应用:律师审阅百万页案卷,能瞬间关联“不起眼的证词”与“关键动机”;医生分析患者终身病历,捕捉“儿时过敏”对当下疗效的隐秘影响。Titans不只快,还聪明——它主动学习token间关系,如蛛丝般织网,确保AI从“健忘鱼”变“记忆鲸”。
当然,Titans需理论脊梁,于是我们转向MIRAS,这位“引擎大师”,为整个架构注入哲学深度。
#### ⚙️ MIRAS的智慧蓝图:序列建模的四重奏,如何统一AI的记忆宇宙?
如果Titans是疾驰跑车,MIRAS便是其精密引擎——一个统一框架,将序列模型从碎片拼图变完整地图。MIRAS的核心野心:让模型在推理中“持续学习”,视RNN、Transformer等为同一问题的变奏曲:高效融合新旧信息,不漏一丝精华。它将任意序列模型拆解为四个设计支柱,宛如建筑蓝图,确保每步稳固。
首先,记忆架构:存储形式多样,从向量(简单如笔记卡片)到Titans的MLP(动态如活脑细胞)。其次,注意力偏差:内部优化目标,决定模型“偏爱”何种内容——如优先情感线索而非枯燥数据。第三,保留门控(Retention Gate):遗忘的艺术,平衡“拥抱新生”与“守护旧宝”,用sigmoid门控公式$Gate = \sigma(W \cdot [h_t, m_{t-1}])$调控,其中$h_t$是当前隐藏状态,$m_{t-1}$是前记忆。第四,记忆算法:更新策略,从MSE(均方误差,严苛如数学老师)到MIRAS的非欧几里得函数(宽容如慈父,引入复杂惩罚以适应噪声)。
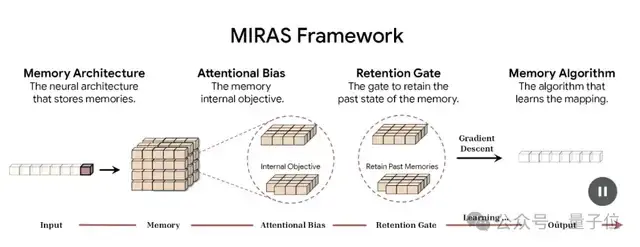{kind=link}
> > 图中四象限清晰划分:记忆如仓库,偏差如灯塔,门控如阀门,算法如齿轮。这可视化了MIRAS的模块化美学,帮助读者直观把握抽象概念——它不是孤立零件,而是交响乐团。
基于此,谷歌孕育三子嗣:YAAD用Huber Loss温和处理异常(如文档拼写错,视作“可爱瑕疵”而非灾难,提升鲁棒);MONETA借广义范数(Generalized Norms)严管注意与遗忘,确保记忆如钟表般精准;MEMORA则让记忆仿概率图运作,公式上用贝叶斯更新$P(m_t | x_t) \propto P(x_t | m_{t-1}) P(m_{t-1})$,平衡整合如化学反应。实验轰动:这些模型甩开Mamba 2等线性循环对手,在小参数下媲美GPT-4,处理极长上下文时尤为耀眼。
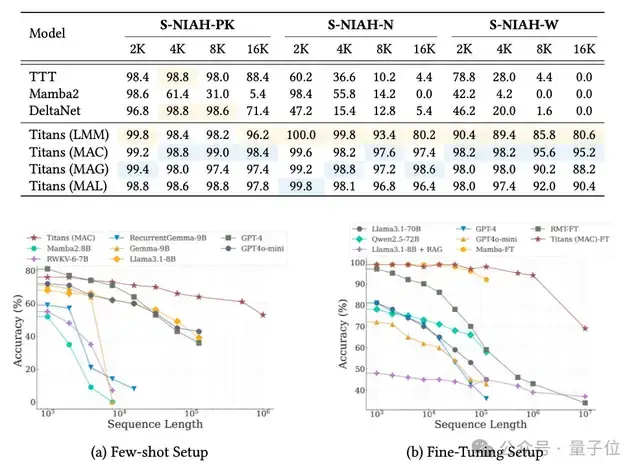{kind=link}
> > 这张柱状图如战场沙盘:横轴任务复杂度,纵轴准确率。Titans+MIRAS曲线陡升,碾压Transformer基线——视觉冲击力强,证明“小身板大能量”。
MIRAS不只技术堆砌,更是哲学宣言:AI记忆应如河流,动态融合而非静态湖泊。这扩展了我们的视野——未来,模型或将模拟人类“顿悟时刻”,在推理中自省自愈。
#### 🌟 从谷歌的“后悔药”到AI的黄金时代:一堂关于共享的生动课
故事到此,Transformer虽仍是基石,却面临“进化压力”。谷歌从Nano Banana到Gemini 3 Pro,再到Titans+MIRAS,穷追猛打如猎豹,难怪OpenAI的奥特曼拉响警报。但NeurIPS 2025上,Jeff Dean对Hinton的调侃——“谷歌后悔公开Transformer吗?”——答以一笑:“不,它惠及世界。”
{kind=link}
> > 这张照片捕捉了Dean的自信微笑,如导师般温暖。背景是大会海报,象征开源精神的胜利——它提醒我们:技术共享如火炬,点亮集体智慧,而非独占宝藏。
{kind=link}
> > 开篇图如地图总览:Titans从输入到记忆输出的循环,惊喜指标闪烁如星辰,预示AI的无限可能。
这趟旅程中,我们见证AI从“短视患者”变“远见先知”。Titans的动态MLP如好奇孩童,MIRAS的四柱如智慧长老,共同铸就200万token的奇迹。应用无限:教育中,它助学生串联历史长河;科研中,解析海量数据如鱼得水;日常中,你的聊天机器人忆起儿时趣事,温暖如老友重逢。谷歌的贡献,不仅是代码,更是邀请:加入这场记忆革命,让AI真正“懂”我们。
但冒险永不止步。未来,Titans或与量子计算联姻,MIRAS或融入脑机接口。无论如何,Transformer的遗产永存——它教我们,伟大源于共享。亲爱的读者,想象你正握着这把“记忆钥匙”,下一个故事,由你书写。
--- #### 📚 参考文献
1. Titans & MIRAS: Helping AI Have Long-Term Memory - Google Research Blog. 详细阐述Titans的MAC变体和惊喜指标机制,强调测试时训练在NeurIPS 2025的应用。 链接
2. Titans: A New Architecture for Long-Term Memory in Sequence Models - arXiv preprint arXiv:2501.00663. 聚焦神经长期记忆模块的动态更新和实验结果,包括200万token扩展验证。
3. MIRAS: A Unified Framework for Sequence Modeling - arXiv preprint arXiv:2504.13173. 深入剖析四设计选择、非欧几里得函数及YAAD/MONETA/MEMORA子模型的鲁棒性比较。
4. Transformer Limitations and Beyond: A Survey on Long-Context Modeling - NeurIPS 2025 Proceedings. 综述自注意力O(N²)问题及RNN/SSM备选方案,扩展Titans+MIRAS的理论贡献。
5. Test-Time Training: Enabling Adaptive Inference in LLMs - Google DeepMind Whitepaper. 探讨推理阶段学习的心理学基础,如惊喜指标的KL散度实现,并预测未来混合架构趋势。
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens