想象一下,你正站在一个巨大的电子工厂里,四周是密密麻麻的电线纠缠成一团乱麻,每根线都闪烁着微光,传递着无数信号,却没人知道哪根线到底在负责什么任务。这就是传统大语言模型的内部世界——一个黑箱,充满了叠加的计算,让人类难以窥探AI究竟是如何“思考”和决策的。但现在,一道光芒从OpenAI的实验室射出:他们悄悄开源了一个仅有0.4亿参数的小模型,却把99.9%的权重连接直接砍成零,只留下千分之一的有效路径。这听起来像科幻小说里的情节——AI突然变得像电路板一样清晰可读,我们终于能追踪每一步逻辑,避免被它的“胡说八道”骗得团团转。

这张图生动展示了传统神经网络的混乱与稀疏电路的简洁对比,就像从一锅意大利面条中抽出几根直线导线,让一切变得井井有条。
⚡ 黑箱的诅咒:为什么传统AI像一团乱麻?
让我们先来聊聊传统Transformer模型的尴尬处境。想象你的脑子里有成千上万个神经元,每个都和别人扯着无数根“线”——权重连接。这些连接几乎全是非零的,信息像洪水般涌来涌去,高度叠加。结果呢?AI能吐出流利的答案,但你问它“为什么这么想”,它只能耸耸肩(如果它有肩的话)。这就像一个超级聪明的朋友,总能猜对谜底,却从来不告诉你推理过程。你敢完全相信他吗?
黑箱问题指的是神经网络内部计算的不可解释性:特征往往以“叠加”(superposition)形式存在,一个神经元可能同时处理多个概念,导致人类无法精准追踪决策路径。这不仅让AI容易产生幻觉(hallucination,即胡说八道),还阻碍了我们在安全关键领域的应用,比如医疗诊断或自动驾驶。
传统稠密模型的权重矩阵密密麻麻,非零值到处都是,信息传递呈现出一种“集体狂欢”的状态。没人能说清某个结论到底源于哪几个神经元。这就是为什么AI可解释性(interpretability)成了当下热门课题——我们需要打开这个黑箱,看看里面到底藏着什么鬼。

这张图对比了稠密与稀疏权重的差异:左边是乱糟糟的连接,右边则是清晰的稀疏路径,仿佛从丛林小径走进了高速公路。
基于此,OpenAI的团队决定反其道而行之:从训练开始就强制模型变得“极致稀疏”。
🔪 砍断99.9%的连接:Circuit Sparsity的诞生
OpenAI这次开源的模型基于GPT-2风格的Transformer架构,但他们在训练过程中严格约束权重的L0范数(一种衡量非零权重的指标),让99.9%的权重直接归零。只剩下千分之一的有效连接,像电路板上的导线一样固定而稀疏。
想象一下,你在组装一个电子玩具,本来可以乱七八糟地连线,但你强制自己只用最少的线完成任务。结果?玩具不仅能工作,还超级易修——坏了哪根线,一眼就看出来。
他们还引入了“均值屏蔽”(mean masking)剪枝方法,为每个具体任务拆解出专属的“最小电路”(minimal circuit)。比如,在处理Python代码中引号闭合的任务时,模型只需动用2个MLP神经元和1个注意力头,就能构建一个完整的电路:包括引号检测器、类型分类器等模块。这些模块就像电路里的电阻和电容,各司其职,互不干扰。
实验结果令人惊叹:在预训练损失相同的情况下,稀疏模型的任务专属电路规模比稠密模型小16倍!而且,这些电路具备严格的必要性和充分性:保留它们,任务完美完成;删掉任何一个节点,模型立刻罢工。每一笔逻辑都能精准追踪,仿佛AI在对你说:“看,这里就是我决定用双引号闭合的理由。”

这张官方图展示了引号预测电路:仅用五个残差通道、两个MLP神经元和特定注意力通道,就实现了精确的单/双引号判断。想象你正调试代码,突然能看到AI的“思维导图”——多酷啊!
这种原生稀疏性让特征变得“单义”和“正交”:每个概念不再分散在多个节点上,而是投射到超高维度中,只激活少数节点。从根源上解决了叠加问题,避免了信息干扰。就像把一堆杂乱的乐高积木分类存放,取用时再也不会混淆。
🆚 对决MoE:粗糙近似 vs 原生优雅
说到这里,不得不提起当下风头正劲的MoE(Mixture of Experts,混合专家模型)。MoE的核心是门控网络把模型拆成多个专家子网络,路由器根据输入分配任务,看起来像在模拟稀疏性。但这其实是一种“粗糙hack”,为了适配硬件的稠密计算需求而生的妥协。
想象MoE像一个大公司:老板(路由器)把任务扔给不同部门(专家),但部门间边界模糊,员工经常串岗,知识冗余严重。负载均衡需要复杂的损失函数调控,稳定性像过山车一样起伏。

这张对比图完美诠释了差异:左边MoE是碎片化的专家块,人工边界明显;右边稀疏电路则是统一的、解纠缠的空间,特征正交如山峰般独立。
反观Circuit Sparsity,它追求的是原生稀疏:从设计上就让特征正交,不需要路由器这种外挂。功能边界清晰,微观机制精准拆解。有人甚至大胆预测,这种“极致稀疏+功能解耦”的思路,可能让MoE渐渐走上末路——毕竟,谁还想用粗糙的近似,当优雅的原生方案摆在眼前?
当然,MoE在算力效率和性能平衡上更成熟,短期内仍是工业界宠儿。但稀疏电路像一颗种子,悄然播下未来变革的可能。
💸 致命短板:算力饥渴的代价
天下没有免费的午餐。Circuit Sparsity目前最大的痛点是训练和推理成本高得离谱——是传统稠密模型的100到1000倍!模型能力也暂时追不上顶尖大模型。就像一辆手工打造的超级跑车,性能惊人却油耗惊人,开不起。
团队已经看到曙光:两种克服方案正在探索中。
首先,直接从现有稠密模型中提取稀疏电路。复用成熟基础框架,不用从零训练稀疏模型,成本暴降。这就像从一辆量产车里拆出精华零件,组装成可解释的“小车”。
其次,坚持从头训练原生稀疏模型,但优化训练机制。比如改进激活稀疏性,或开发新算法,让高效与可解释并存。
想象一下,未来我们能拥有既强大又透明的AI:像玻璃房子一样,内部一览无余,却坚固无比。
🌟 更复杂的推理:从引号到变量绑定
不止简单任务,团队还在探索更复杂的电路。比如变量绑定(variable binding):模型需追踪函数中变量的类型和名称。
在稀疏模型中,这表现为注意力头在变量定义处“写入”信息,后续使用时“复制”回来。虽然电路更大,还未完全解读,但已能给出预测性结构描述。就像破解一个谜题,虽然没全解开,但已看到关键线索。
增大模型规模、提升稀疏度,能同时改善能力和解释性——这是一条“能力-可解释性前沿”曲线,令人兴奋。
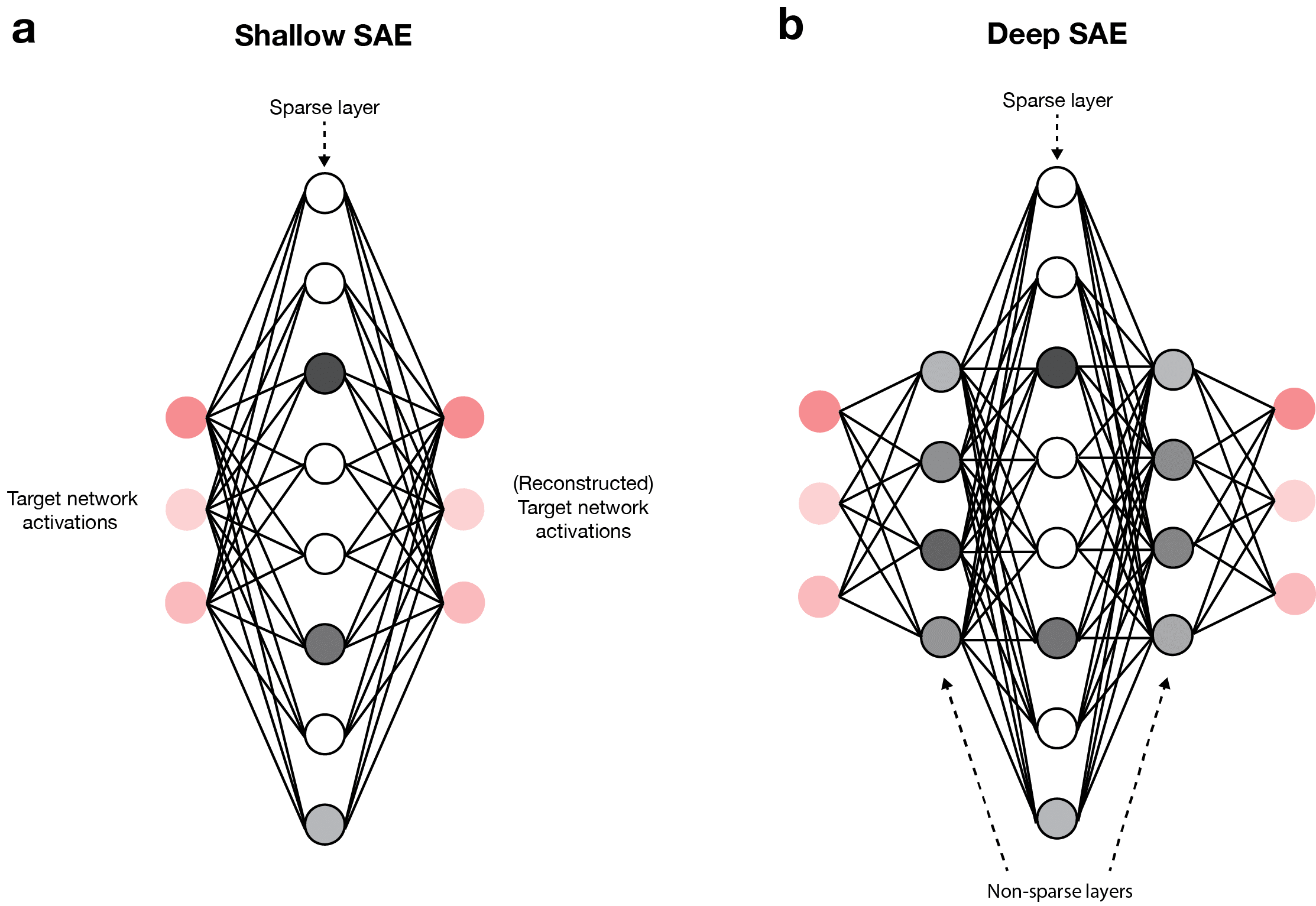
这张图展示了更高级电路的局部结构,暗示AI推理正逐步被拆解成可懂的模块。
🚀 未来展望:揭开黑箱面纱的漫长旅程
OpenAI强调,这只是AI可解释性探索的早期一步。未来,他们计划扩展到更大模型,解锁复杂推理电路;枚举电路模式库,帮助调查前沿模型;甚至开发工具,分析、调试和评估未来系统。
想象你正站在AI的“手术台”前,手持放大镜,逐一剖析它的“神经”。不再害怕它的胡话,因为你知道每一步源于何处。这不只是技术进步,更是通往可信AI的桥梁。
当稀疏电路成熟那天,我们或许会感慨:原来,破解AI黑箱的关键,竟是勇敢地砍掉那些多余的线,让真相在简洁中闪光。
这张封面图象征着从黑箱到透明的转变,犹如小说结局般充满希望。
参考文献
- OpenAI. Understanding neural networks through sparse circuits. https://openai.com/index/understanding-neural-networks-through-sparse-circuits/
- Gao et al. Weight-sparse transformers have interpretable circuits. arXiv preprint, 2025. https://arxiv.org/abs/2511.13653
- Quantum Bit Article on Circuit Sparsity. Zhihu Column, 2025. (Original user-provided reference)
- OpenAI GitHub Repository: circuit_sparsity. https://github.com/openai/circuit_sparsity
- MarkTechPost Coverage on OpenAI Sparse Circuits Release. https://www.marktechpost.com/2025/12/13/openai-has-released-the-circuit-sparsity-a-set-of-open-tools-for-connecting-weight-sparse-models-and-dense-baselines-through-activation-bridges/
讨论回复
加载中...正在加载回复...
推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。