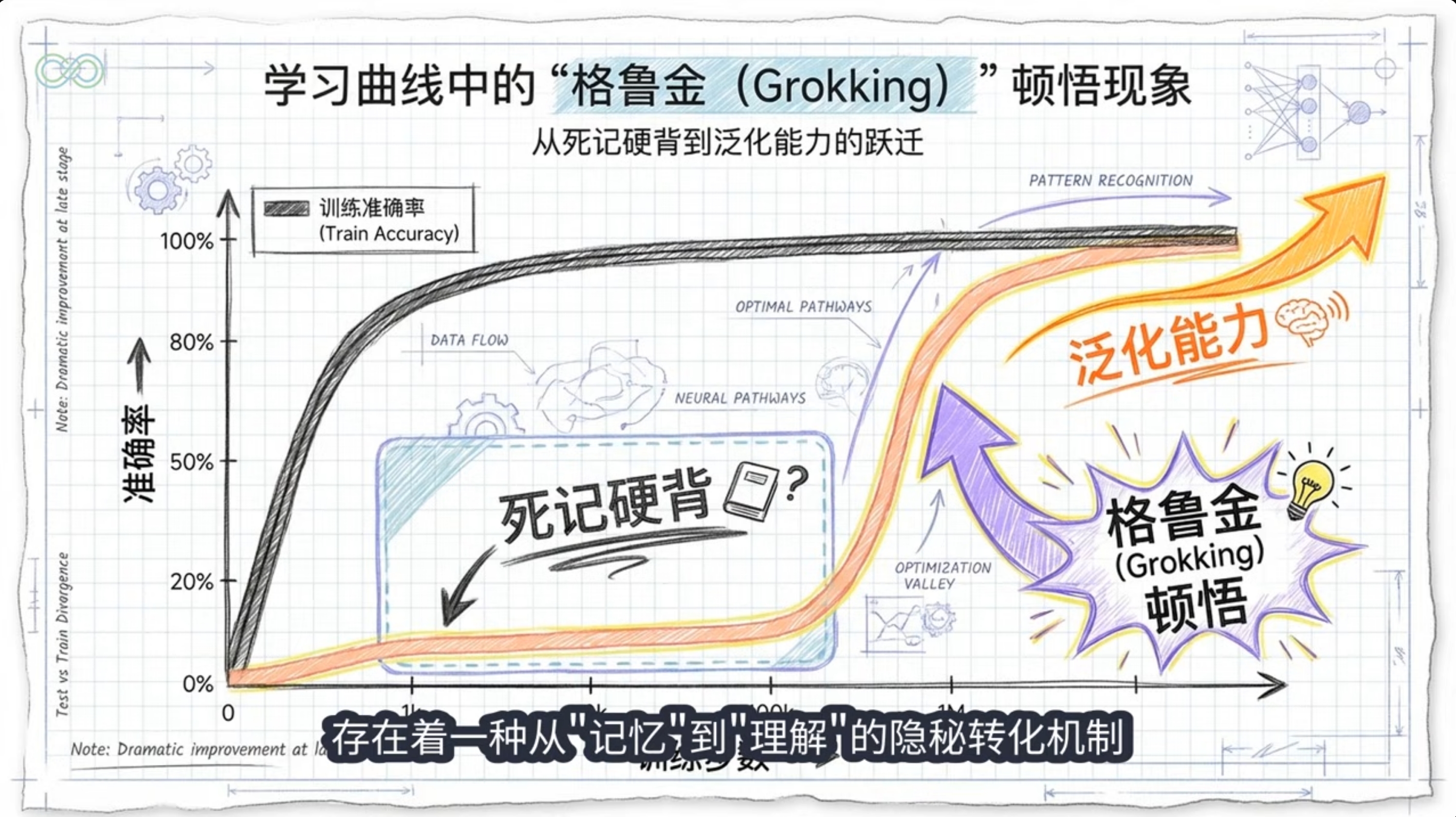
Grokking是神经网络训练中一种延迟泛化相变现象:在过拟合后,继续训练导致模型从记忆转向结构化理解(如算法电路或三角表示)。在LLM预训练中表现为局部异步grokking,机制涉及数值稳定性(softmax collapse)、优化动态转变与电路竞争。2024-2025研究深化了数值与相变视角,证实其在真实LLM中的存在。
行动建议
- 研究者:监控预训练中数据子集损失与内部路径演化,作为廉价泛化指标。
- 实践者:适度延长训练并加强正则化,可能诱导更好泛化;关注数值精度优化(如Muon优化器)。
登录后可参与表态
讨论回复
加载中...
正在加载回复...
正在加载回复...
推荐
推荐
智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
领取 2000万 Tokens
通过邀请链接注册即可获得大礼包,期待和你一起在 BigModel 上畅享卓越模型能力