Monet: Reasoning in Latent Visual Space visibility AI视觉推理在潜在空间的革命性突破
Monet: Reasoning in Latent Visual Space
visibility
AI视觉推理在潜在空间的革命性突破
北京大学 | 快手 | MIT 联合团队
lightbulb
核心概念:超越像素的"想象之眼"
Monet旨在让多模态大模型(MLLM)摆脱"看图说话"的笨拙模式,真正拥有类似人类的"想象之眼"。它不再满足于简单的像素识别,而是在高维的"潜在视觉空间"中进行连续的心理模拟。
流形假说 数据在高维空间中集中在低维流形上。Monet如同在沙漠中找到了唯一的"绿洲之路",在低维流形上进行"心理模拟",避免了维度灾难。
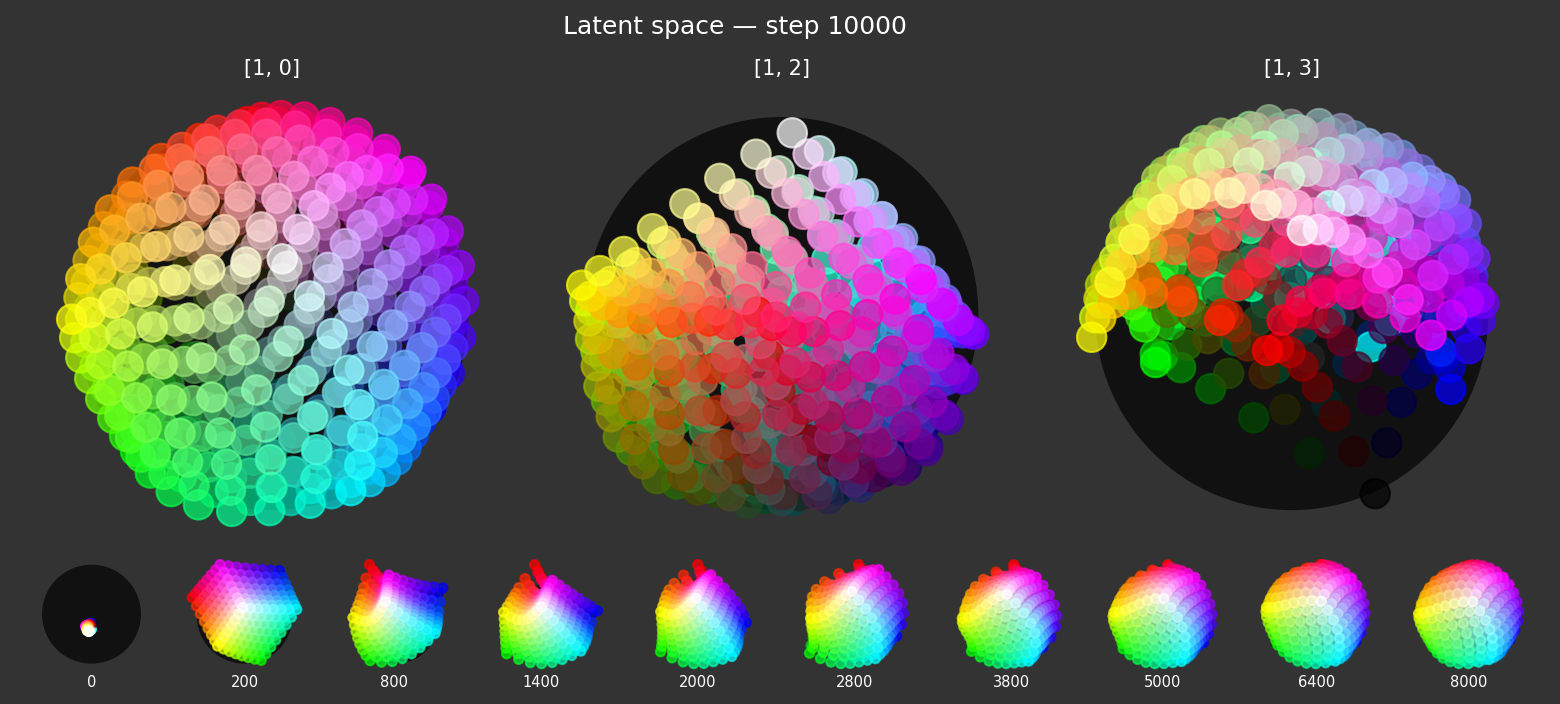
architecture
核心技术架构
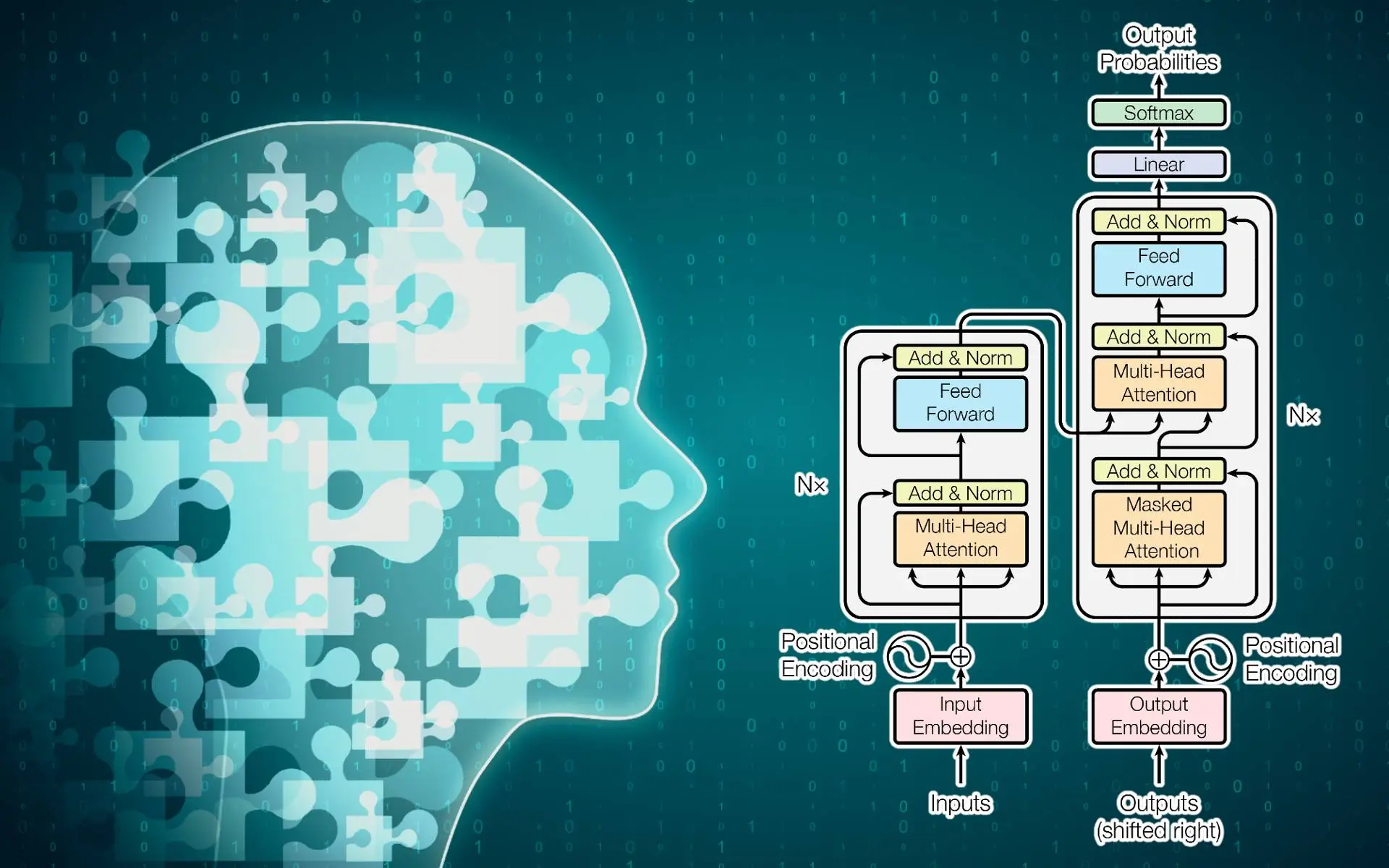
SFT (蒸馏微调)
- 阶段1: 热身适应图像-文本交错推理
- 阶段2: 获取高质量目标潜在嵌入
- 阶段3: 无辅助图像下自主生成嵌入
VLPO (策略优化)
将连续潜变量纳入强化学习策略梯度,直接根据奖励信号优化"视觉直觉"。
bar_chart
实验结果与性能
Monet在常规推理任务和分布外 (OOD)抽象任务上均显著超越基线模型(如GPT-4V)。
rocket_launch
未来展望与应用

机器人救灾:模拟复杂环境,规划安全路径

医疗预测:模拟病情演变,辅助诊疗决策
当机器拥有"心智模型",它们将像人类一样在脑海中预演行动后果,开启AI在物理世界应用的新篇章。
💬 讨论回复 (0)
推荐
🌟 智谱 GLM-5 已上线
我正在智谱大模型开放平台 BigModel.cn 上打造 AI 应用,智谱新一代旗舰模型 GLM-5 已上线,在推理、代码、智能体综合能力达到开源模型 SOTA 水平。
🎁 领取 2000万 Tokens