失落的加速器:Trace Cache的荣耀与陨落
想象一下,你是一名赛车手,在一条布满弯道的高速赛道上飞驰。每次转弯、加速、刹车,你的大脑都在实时记录最优路径。下一次再跑同样的赛段,你不需要重新思考——直接“重播”那段完美操作,就能以最快速度通过。这就是Intel Pentium 4时代Trace Cache的核心魔力:它不是静态存指令,而是记录下CPU实际执行过的动态微操作序列(uop trace)。可惜,这项曾经被寄予厚望的“赛车记忆”技术,却因为过于复杂、代价高昂,最终在历史的尘埃中黯然退场。今天,让我们一起重返那个NetBurst狂飙的时代,探寻Trace Cache的兴衰故事。
🏁 赛道记忆的诞生:Trace Cache为何如此特别
在Pentium 4的NetBurst微架构中,Trace Cache是Intel试图彻底颠覆传统前端设计的大胆尝试。它不再像经典的L1 Instruction Cache那样单纯存放x86指令,而是直接缓存解码后的微操作(uop)片段——而且是动态的、实际执行过的片段。

一条Trace由多个trace-line组成。Northwood核心的每个trace-line可容纳6个uop,每两个周期能加载两条;Prescott则改为每个周期加载一条但只有4个uop的trace-line。容量方面,Northwood的Trace Cache为80 KiB,Prescott增大到128 KiB,相当于约16K个uop(Prescott)。作为对比,同期的Tualatin(Pentium III移动版)L1 I-Cache仅16 KiB,直到Merom(Core 2首发)才提升到32 KiB。
什么是Trace Cache与传统I-Cache的根本区别?
传统L1 I-Cache存的是原始x86指令,CPU每取一次都要重新解码成uop,解码器成为瓶颈。Trace Cache直接存已经解码且实际执行过的uop序列,命中时可直接“重播”,省去了重复解码的开销。就像你背熟了一段乐谱,不用再看谱直接弹奏。
这种设计还需要一系列配套设施:Trace BTB(分支目标缓冲专门服务Trace)、复杂的构建逻辑、退休单元反馈等,整个前端复杂度远超传统I-Cache + 解码器组合。这也是为什么后人常说:Trace Cache的实现要比i-Cache和现在的uOP Cache复杂得多。
⚠️ 荣耀背后的隐患:命中失败的代价
Trace Cache的初衷是取代L1 I-Cache,成为前端唯一的指令供应来源。可一旦Trace未命中,问题就严重了——前端只能转向L2 Cache取指令,L2在NetBurst时代有11个周期的可怕延迟。再加上NetBurst那条著名的20+级超长流水线,任何前端停顿都会被放大成灾难性性能损失。
在分支密集的负载(如国际象棋引擎)中,Trace构建难度剧增,未命中率飙升,CPU仿佛突然从高速公路掉进了乡间小路,性能瞬间“扑街”。这正是当年Pentium 4在SPECint等整数分支密集基准上表现不佳的罪魁祸首之一。
🌉 从NetBurst到Core的桥梁:被遗忘的PARROT论文
在NetBurst走向尽头、Core架构酝酿之际,Intel以色列海法实验室发表了一篇如今常被忽视的关键论文——PARROT。它首次系统提出“冷热路径”分离的思想:把程序中频繁执行的热路径优化到极致,冷路径则用低功耗方式处理。

PARROT引入了多项革命性技术:uop fusion(宏融合,把多条uop合并减少依赖)、标量指令的SIMD化、关注能耗的前端设计……这些理念直接影响了后续Core微架构。Trace Cache那套昂贵而激进的动态trace理念虽然退场,但PARROT对“热路径加速”的执着,却以更务实的方式延续下来。
🔄 传承与进化:LSD + uOP Cache的新时代
从Core架构开始,Intel放弃了Trace Cache,转而采用混合方案:传统L1 I-Cache + uOP Cache + Loop Stream Detector(LSD)。uOP Cache缓存解码后的uop,但只缓存热路径,且不追求完全取代I-Cache;LSD则专门检测并重播小循环,避免反复取指解码。
这种设计既保留了Trace Cache“重播热路径”的精髓,又大幅降低了复杂度和miss代价。AMD Zen系列也走了类似道路,并提供了关闭uOP Cache的BIOS选项,实测差距惊人:
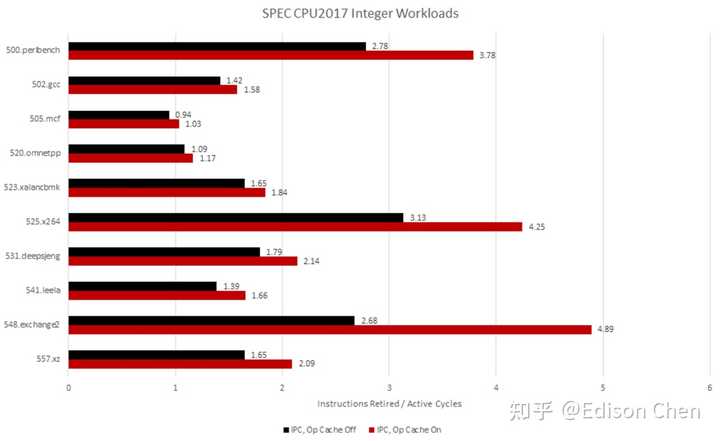
Zen 5的uOP Cache容量约为6K uop,远小于Prescott的16K uop,却因为更先进的解码器、更精准的预测、更低的miss penalty,实际效果往往更出色。
LSD(Loop Stream Detector)是做什么的?
当检测到小循环(通常几十条指令以内)反复执行时,LSD会锁定前端,直接从解码后的uop缓冲中循环供应,完全绕过取指和解码阶段。就像把一段反复播放的副歌直接录进磁带,不用每次都从唱片重新读。
🛤️
当代最优解:uOP Cache + L1I + TAGE的黄金组合
如今的主流高性能x86前端,几乎都趋同于这种“三保险”方案:
- L1 I-Cache提供冷路径和初始取指
- uOP Cache加速热路径
- TAGE分支预测器提供极高的预测准确率
- LSD处理小循环
相比当年Trace Cache试图“一统江湖”的激进,这种混合设计在性能、功耗、面积之间取得了最佳平衡。Zen 5的6K uop虽小,却能在现代制程和预测器的加持下,轻松碾压Prescott的16K uop。
尾声:技术的轮回
Trace Cache就像一位昙花一现的天才赛车手,用惊艳的技术征服了特定赛段,却因为规则变化(功耗墙、制程瓶颈)黯然离场。但它的灵魂——对热路径的极致加速——从未消失,而是以更成熟、更高效的形式,在今天的uOP Cache和LSD中继续闪耀。
每当我们感叹现代CPU前端的强大时,别忘了向那个NetBurst时代致敬:正因为有过Trace Cache这样大胆甚至有些疯狂的尝试,后人才知道哪条路更值得坚持。
参考文献
- Intel Pentium 4 Processor Optimization Manual (2001-2005)
- Sprangle E, Carmean D. "Increasing Processor Performance by Implementing Deeper Pipelines" (ISCA 2002, NetBurst相关)
- Rotem E et al. "PARROT: Power Awareness and Reducing Redundant Operations in Transmeta-inspired Architecture" (Intel Haifa, ~2005)
- AMD Zen Architecture Whitepaper & Zen 5 Technical Deep Dive
- 知乎专栏用户技术整理贴(本文主要参考来源,包含Trace Cache与uOP Cache历史对比)