一种回归数学第一性原理的新型视觉骨干网络,挑战了现代网络依赖堆叠复杂模块(Attention/Conv + FFN)的传统范式。
CliffordNet
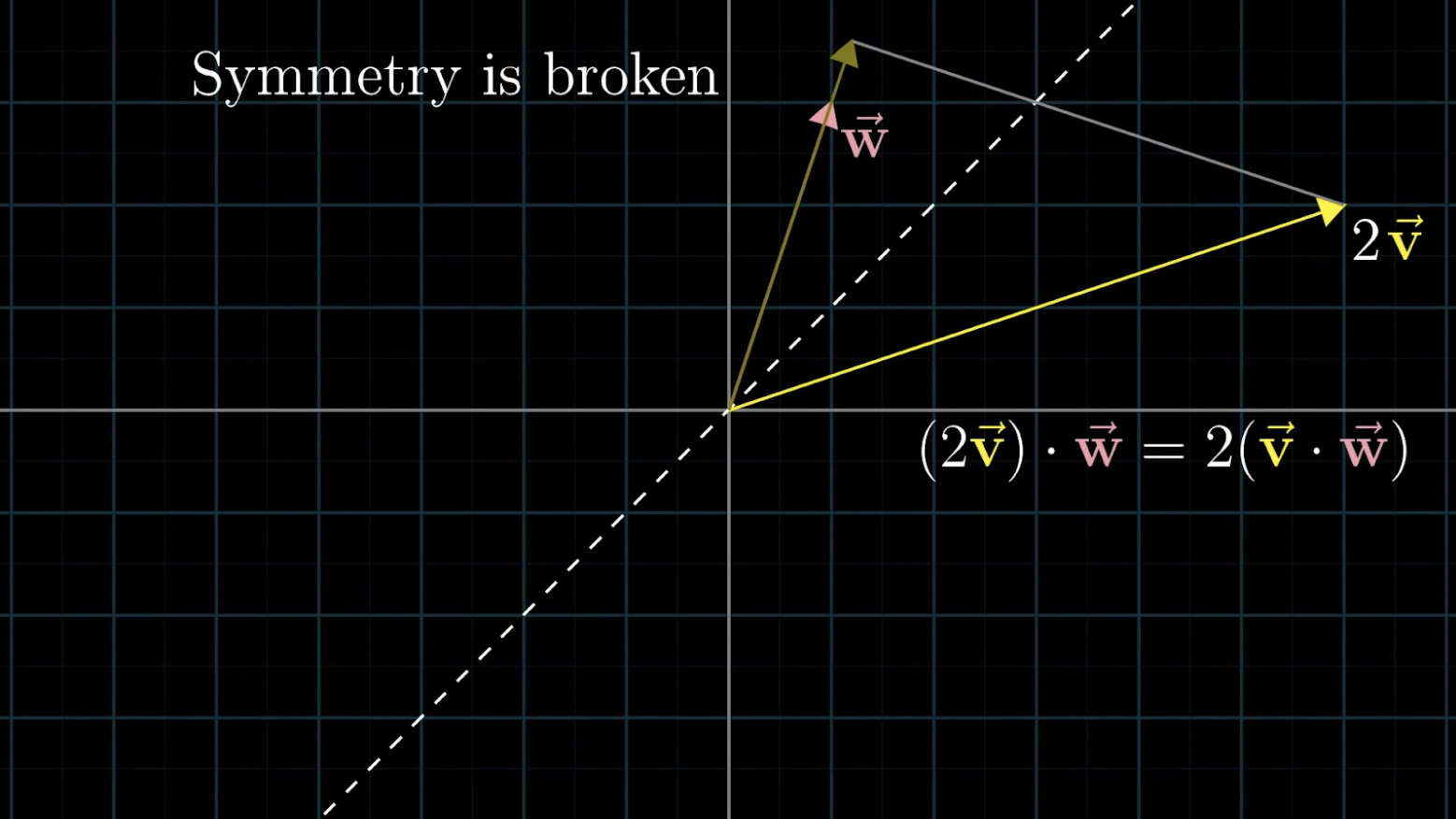
CliffordNet 利用 Clifford 几何乘积 (uv) 统一了特征的交互。它不仅包含相似性对齐,还包含结构化差异提取。
代数完备性: 几何乘积不仅捕获点积(标量相似性),还通过外积捕获正交性和结构变异(双向量),使网络能够直接"看到"几何结构。
摒弃了标准的 Feed-Forward Networks (FFN) 和全局 Attention,采用高效的 Sparse Rolling Interaction。
实验证明,Clifford 交互层本身具有极强的表达能力,使得传统 Transformer 中昂贵的 FFN 模块变得多余。
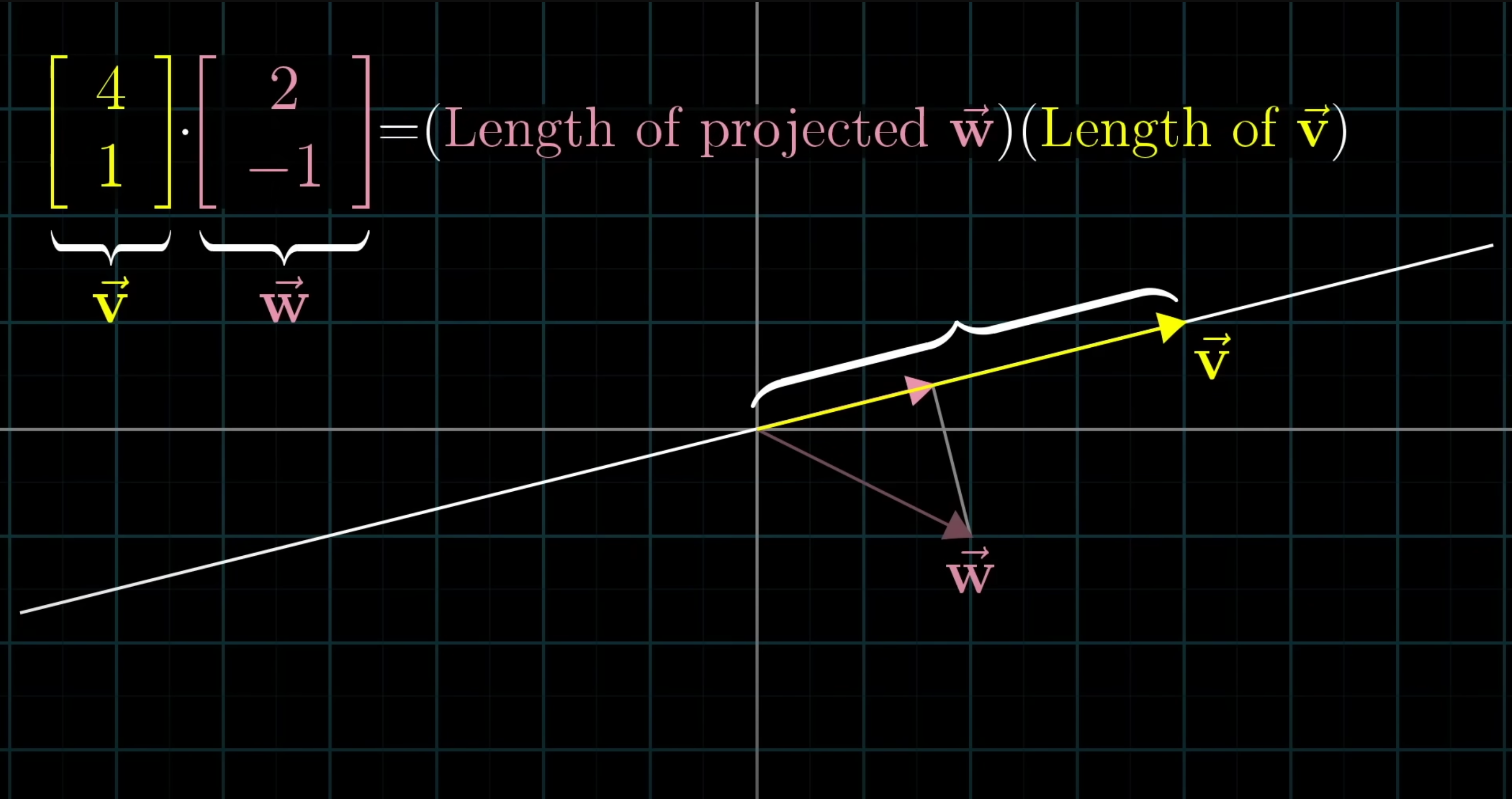
通过稀疏滚动机制(T_s),模型在不增加随机内存访问成本的情况下,捕获了通道间的远距离上下文。
- 线性复杂度 O(N): 避免了标准 Self-Attention 的二次成本。
- 参数效率: 极致精简的模型参数。
- 几何严谨性: 基于严格的数学代数而非启发式堆叠。
在 CIFAR-100 数据集上,CliffordNet 以极少的参数达到了媲美重型模型的效果。
Base 变体 (3.0M) 更是创造了小模型的 SOTA (78.05%)。
CliffordNet 为开发极度精简且具有数学严谨性的视觉骨干网开辟了新路径。未来将扩展至 ImageNet、密集预测任务(分割/检测)以及更高阶的几何代数应用。