RWKV模型深度研究报告(截至2026年初)
1. 模型架构与技术原理
1.1 RWKV核心架构设计
#### 1.1.1 RNN-Transformer混合架构:线性注意力机制替代传统多头注意力
RWKV(Receptance Weighted Key Value,发音为"RwaKuv")代表了一种根本性的神经网络架构创新,其核心突破在于成功融合了循环神经网络(RNN)的高效推理特性与Transformer架构的并行训练优势 。该架构由Bo Peng及其领导的RWKV开源社区开发,自2023年加入Linux基金会以来,已发展成为备受关注的非盈利开源项目 。RWKV最显著的技术特征在于其完全摒弃了传统Transformer中计算复杂度为O(n²)的自注意力机制,转而采用一种精心设计的线性注意力机制,从而在保持竞争力的模型性能的同时,实现了计算效率的数量级提升。
传统Transformer架构的核心瓶颈在于其自注意力机制:对于长度为n的输入序列,每个token都需要与序列中所有其他token计算注意力分数,形成完整的n×n注意力矩阵。这种设计虽然赋予了Transformer强大的全局依赖建模能力,但也导致了两个严重问题——计算量随序列长度呈平方级增长,以及推理阶段必须维护庞大的键值缓存(KV-Cache),进一步加剧了内存压力。RWKV通过其独特的线性注意力设计彻底改变了这一范式:该架构将信息传递重新建模为递归形式,每个时间步的计算仅依赖于当前输入和前一个隐藏状态,而非完整的序列历史,从而将复杂度降至O(n)的线性级别,同时消除了KV-Cache的需求 。
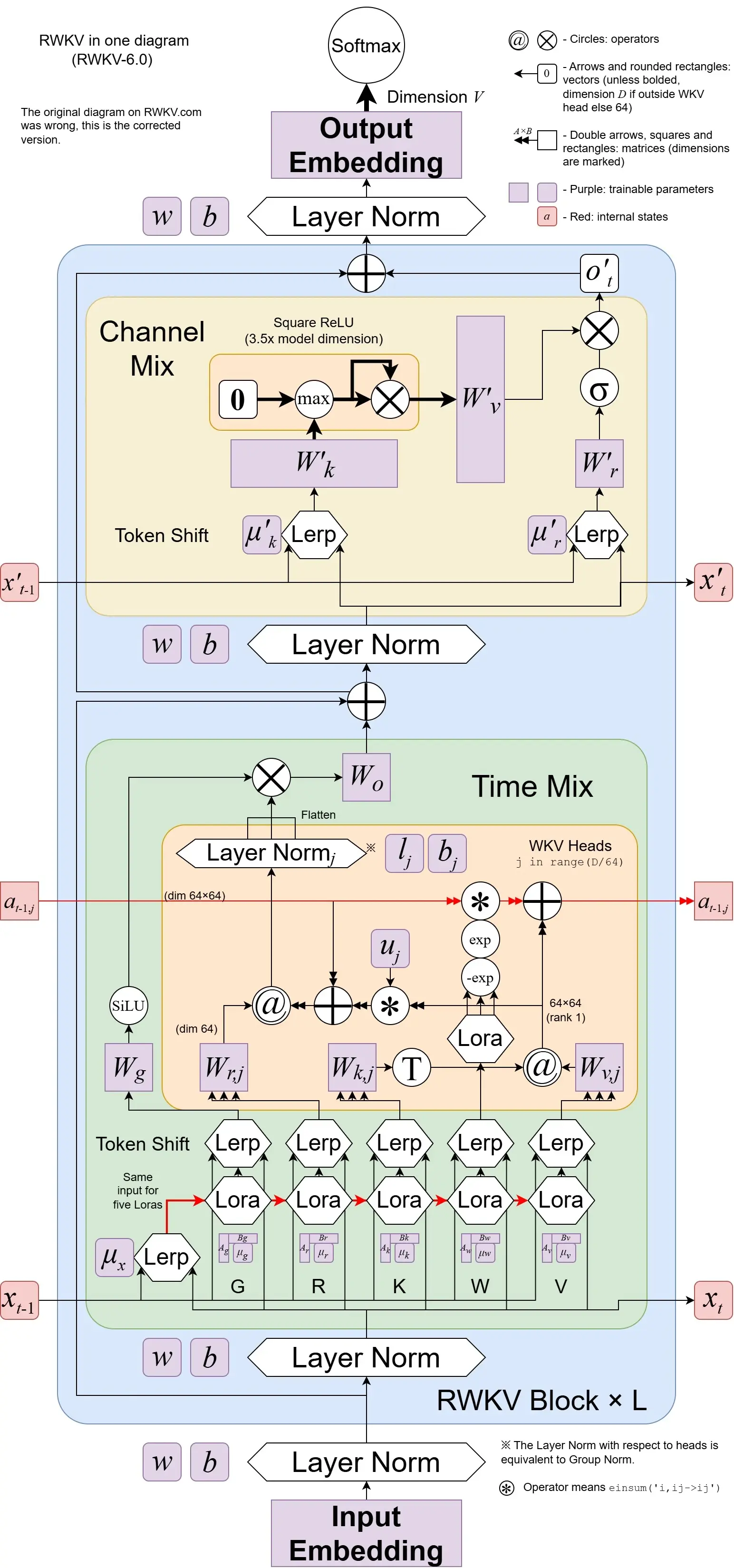
从数学形式上看,RWKV的注意力计算可以表达为一种递归状态更新机制。设F[t]为时刻t的系统状态,x[t]为新的外部输入,RWKV通过可学习的Receptance矩阵R、Key矩阵K、Value矩阵V以及时间衰减向量W来计算当前输出。与GPT-style模型需要同时考虑F[0]到F[t]所有历史状态不同,RWKV的状态更新仅依赖于前一时刻状态F[t-1]和当前输入x[t]。关键的创新在于,RWKV的"并行模式"(parallel mode)在训练时采用类似Apple AFT(Attention-Free Transformer)的结构,允许像Transformer一样进行高效的并行计算;而在推理时则转换为"递归模式"(recursive mode),实现常数时间的单步生成 。这种"训练时并行、推理时串行"的双模式特性是RWKV架构的工程精髓所在。
#### 1.1.2 四大核心组件:Receptance(R)、Weight(W)、Key(K)、Value(V)机制解析
RWKV的命名直接来源于其四个核心计算组件,这些组件共同构成了独特的信息处理流程,每个组件承担着 distinct 的功能角色 :
Receptance(R,接收门) 是RWKV架构中最具创新性的设计之一。该组件决定了当前token应该从历史隐状态中接收多少信息,本质上扮演着信息筛选器的角色。R通过sigmoid激活函数输出0到1之间的值,实现对过往状态的选择性吸收。与LSTM中的遗忘门和输入门类似,但计算方式更加高效,R门能够根据当前输入的语义特征自适应地调整对历史上下文的依赖程度,从而在长序列中实现有效的信息聚焦。
Weight(W,权重/时间衰减) 提供了可学习的位置相关衰减机制。W以通道级(channel-wise)的方式初始化,其值类似于ALiBi中的线性偏置,但关键区别在于W是可训练的而非固定值 。这一设计允许模型为不同的特征通道学习独立的时间衰减特性——某些通道可能专注于捕捉长期趋势(慢衰减),而另一些通道则关注近期信息(快衰减)。W的存在使得RWKV能够在不使用显式位置编码的情况下,隐式地建模序列中的时间顺序信息。
Key(K,键向量) 与 Value(V,值向量) 延续了注意力机制中的经典概念,但应用方式有所不同。Key负责对输入token的压缩表示,用于计算与历史信息的兼容性;Value则承载了实际需要传递的语义信息。在RWKV的线性注意力框架下,K和V的计算与当前输入直接相关,通过线性投影从输入嵌入得到,然后与Receptance调控的历史状态进行融合。
这四个组件的协同工作形成了RWKV独特的状态更新公式。在训练阶段,模型以并行方式处理整个序列,通过矩阵运算高效计算所有时间步的R、K、V;在推理阶段,模型以递归方式逐个生成token,每步仅需维护固定大小的状态向量,实现了真正的常数内存复杂度 。
#### 1.1.3 双层结构:Time-Mixing Block(时序信息处理)与Channel-Mixing Block(特征通道处理)
RWKV的每个基本构建块由两个功能互补的子模块组成,分别针对不同类型的信息交互进行优化 :
Time-Mixing Block(时序混合模块) 是RWKV实现序列建模能力的核心。该模块负责处理不同时间步之间的信息交互,功能上对应于Transformer中的自注意力层,但计算方式截然不同。Time-Mixing通过RWKV机制——即R、W、K、V四个组件的协同计算——实现了对历史信息的递归聚合。关键的设计细节包括Token Shift(token位移)机制:在计算当前token的表示时,不仅使用其自身嵌入,还通过可学习比例将其与前一token的嵌入进行混合。这一"时间偏移"设计增强了模型对局部上下文模式的敏感性,缓解了传统RNN将长序列压缩为单一隐向量时的信息损失问题 。
RWKV-6对这一机制进行了重大升级,引入了基于LoRA的动态Token Shift。静态混合比例被替换为输入依赖的动态形式:lora(x) = λ + tanh(xA)B,其中A、B是可学习的低秩矩阵。这一改进使得模型能够根据输入内容动态决定每个通道的信息融合策略——"重要信息"可以通过学习到的模式主动标记自身,而"不重要信息"则被抑制 。
Channel-Mixing Block(通道混合模块) 负责处理特征维度上的非线性变换,功能上对应于Transformer中的前馈网络(FFN)。该模块对每个时间步的特征向量独立操作,通过可学习的线性变换和非线性激活(通常为SiLU或GeLU)实现特征空间的复杂映射。与Time-Mixing不同,Channel-Mixing不涉及时间维度上的交互,因此计算完全并行化,不会成为推理效率的瓶颈。
1.2 计算效率优势
#### 1.2.1 线性时间复杂度O(n) vs Transformer的O(n²)
RWKV最显著的架构优势在于其严格的时间复杂度优化。对于长度为n的输入序列,标准Transformer的自注意力机制需要计算n×n的注意力矩阵,时间和空间复杂度均为O(n²)。当n从1K增长到100K时,Transformer的计算成本增长约10,000倍,这使得长文本处理在硬件资源上变得极为昂贵甚至不可行 。
RWKV通过递归状态更新机制将这一复杂度降至O(n)。具体而言,每个token的处理仅涉及固定大小的矩阵-向量乘法,计算量与序列位置无关。对于长度为n的序列,总计算量与n成正比,而非n的平方。这一改进的量化影响极为显著:假设处理单个token需要C次基本运算,Transformer需要约Cn²次运算,而RWKV仅需约Cn次。当n=10,000时,RWKV的计算效率优势达到三个数量级 。
更深入的复杂度分析需要考虑实际运算类型。Transformer的O(n²)复杂度主要来自矩阵乘法,其常数因子较大,涉及高维张量的频繁内存访问。RWKV的O(n)操作主要是矩阵-向量乘法和逐元素运算,内存访问模式更加规则,硬件利用率更高。在实际GPU实现中,这种差异往往比理论分析更为显著——RWKV的线性操作能够更好地利用GPU的Tensor Core,而Transformer的注意力计算常受限于内存带宽而非计算单元 。
#### 1.2.2 常数级显存占用:与序列长度无关的内存效率
RWKV的内存效率优势与其时间复杂度改进同等重要。标准Transformer在推理时需要维护KV-Cache,其大小为(层数)×(注意力头数)×(每头维度)×(序列长度)×2。对于典型的7B参数模型,使用16位精度,处理1K token序列需要约数GB的KV-Cache;当序列延长至100K token时,KV-Cache alone就需要数百GB内存,远超消费级GPU的容量 。
RWKV彻底规避了这一内存瓶颈。其推理状态仅包含每层的一个隐状态向量,大小为(层数)×(隐藏维度),与序列长度完全无关。以RWKV7-G1-2.9B为例,其隐状态大小约为400KB量级,相比Transformer处理1M token序列时约400GB的KV-Cache需求,内存效率提升超过一百万倍 。这一极端的内存效率使得RWKV能够在资源受限的环境中处理超长序列,为边缘部署和长文档处理应用开辟了新的可能性。
常数级内存占用的实际意义体现在多个层面:它消除了批处理大小与序列长度之间的权衡;简化了服务部署的容量规划;支持真正的流式处理——模型可以无限期地持续运行,处理连续输入流,而不会累积内存消耗 。
#### 1.2.3 无KV-Cache设计:推理时无需存储键值缓存
KV-Cache的消除不仅是内存优化的技术手段,更是架构层面的根本性变革。传统Transformer的推理优化大量围绕Cache管理展开:Cache的分配与释放、分页调度(如vLLM的PagedAttention)、多序列共享等,增加了系统的复杂性和不确定性。RWKV的无Cache设计使得推理引擎可以极为简洁——每个生成步骤执行固定计算图,无需动态内存管理,延迟可预测性大幅提升 。
更深层的收益在于解码策略的灵活性。RWKV支持真正的增量处理——可以在任意时刻中断和恢复生成,而无需保存和恢复庞大的缓存结构。这一特性对于需要低延迟响应的交互式应用尤为重要,可以实现高效的对话状态管理和 speculative decoding 等高级优化 。
1.3 架构演进历程
#### 1.3.1 RWKV-4:基础架构验证,最大14B参数规模
RWKV-4是架构的首个成熟版本,验证了RNN-Transformer混合设计的可行性。该版本发布了从169M到14B参数的多个模型,是当时训练的最大规模密集RNN模型 。RWKV-4确立了核心设计原则:线性注意力、递归推理、并行训练,以及Time-Mixing与Channel-Mixing的双层结构。该版本的生命周期已于2025年6月正式结束,现有模型仅作为历史存档保留 。
#### 1.3.2 RWKV-5/6 (Eagle & Finch):矩阵值表示与长序列优化
RWKV-5(代号"Eagle")和RWKV-6(代号"Finch")引入了矩阵值状态表示(Matrix-Valued States),显著增强了模型的表达能力 。与RWKV-4中标量形式的衰减因子不同,这两个版本采用矩阵形式的状态更新,允许不同特征通道拥有独立的时间衰减特性。EagleX v2模型(基于RWKV-5,2.25万亿token训练)在多项评估中超越了Llama-2-7B,并接近Mistral-7B-v0.1和Llama-3-8B的水平 。两个版本的生命周期同样已于2025年6月结束 。
#### 1.3.3 RWKV-7 (Goose):动态状态演化与广义Delta规则,突破TC⁰计算复杂度限制
RWKV-7(代号"Goose")于2025年3月发布,代表了架构的重大飞跃 。该版本的核心创新是动态状态演化机制和广义Delta规则(Generalized Delta Rule),通过使状态更新过程本身成为输入依赖的,突破了传统线性RNN的TC⁰复杂度限制。状态更新公式演变为:S_t = S_{t-1}(diag(w_t) + a_t^T b_t) + v_t^T k_t,其中w_t是向量值衰减,a_t、b_t是上下文学习率相关的向量,允许通道间的交叉耦合 。RWKV-7-World系列在训练数据量少于同类开源模型的情况下,展现了可比较的语言建模能力,证明了新架构的高效样本利用率 。
#### 1.3.4 RWKV-7-G1 (GooseOne):推理专用模型版本
RWKV-7-G1(GooseOne)是RWKV-7架构的专门优化版本,针对推理和问题解决任务进行了强化训练 。该版本延续了Goose的架构创新,但在训练数据配比和优化目标上更加强调逻辑推理、数学问题和代码生成。G1系列提供了2.9B、7B、13B等多种参数规模,其中RWKV7-G1-2.9B成为消费级部署的热门选择,在RTX 4090上可实现115+ tokens/s的推理速度 。
1.4 训练方法论
#### 1.4.1 并行训练能力:保留Transformer式的高效训练特性
RWKV最具工程价值的特性之一,是它在保持RNN式高效推理的同时,实现了Transformer式的并行训练 。这一"双模式"特性通过巧妙的数学重排实现:在训练时,RWKV可以展开为类似Transformer的"宽"网络结构,所有位置的计算通过矩阵运算批量完成。具体实现中,采用时间并行(Time-Parallel)或块并行(Chunkwise Parallel)技术,将序列分块处理,块内通过矩阵乘法并行计算,块间通过状态传递衔接 。
关于并行训练能力曾存在一些误解需要澄清。RetNet论文曾声称RWKV不支持特定定义的"训练并行化",但RWKV社区回应指出:通过DeepSpeed等框架,RWKV完全支持多GPU并行训练,且在多数情况下训练速度超越同等参数量的Transformer。实际上,RetNet论文作者也已承认RWKV在多GPU高吞吐量训练方面没有问题 。
#### 1.4.2 状态演化机制:动态隐状态更新策略
RWKV-7引入的动态状态演化机制代表了状态空间模型的新进展 。广义Delta规则使得状态更新规则本身可以根据输入内容动态调整,实现了更灵活的上下文适应。训练过程中,状态演化参数需要与网络的其他参数协同优化,采用分层学习率策略——关键参数使用较低的学习率以保证稳定性 。
RWKV还支持独特的状态微调(State-Tuning)技术:仅优化模型的初始状态,而保持其他参数固定,实现零推理开销的领域适应。这一方向展现了RWKV架构独特的微调可能性 。
#### 1.4.3 多语言训练优化:中文、日语等非英语语言的特殊处理
RWKV项目从一开始就高度重视多语言能力。团队注意到OpenAI的tokenizer在非英语语言(特别是中文、日语等)上存在效率问题,因此开发了专门的多语言tokenizer,优化了CJK字符的编码效率 。RWKV-7-World系列使用RWKV World v3语料库,包含3.1万亿token的多语言数据,在英语、中文、日语等多种语言上展现了均衡表现 。Eagle 7B模型在发布时特别强调其多语言基准上的优势,在多个非英语评估中超越了Mistral、Falcon和Llama 2等同期模型 。
2. 推理性能深度分析
2.1 消费级GPU性能实测
#### 2.1.1 NVIDIA RTX 4090平台:fp16/int8/nf4精度对比
NVIDIA RTX 4090作为当前消费级GPU的旗舰产品,为RWKV模型提供了卓越的推理性能平台。基于官方性能测试数据,RWKV7-G1-2.9B模型在该平台上展现了出色的效率特性 :
| 推理引擎 | 精度 | 速度 (tokens/s) | 显存占用 (GB) | 效率比 (speed/GB) |
|---|
| web-rwkv | fp16 | 95.98 | 5.90 | 16.27 |
| web-rwkv | int8 | 108.22 | 3.90 | 27.75 |
| web-rwkv | nf4 | 115.46 | 2.40 | 48.11 |
| llama.cpp(CUDA) | Q8_0 | 110.30 | 3.47 | 31.79 |
| RWKV pip | fp16 | 56.18 | 5.52 | 10.18 |
*测试环境:Intel Xeon Platinum 8331C, Ubuntu 22.04, PyTorch 2.5.1+cu121 *
web-rwkv引擎是当前推荐的推理方案,采用Rust和WebGPU实现,提供跨平台高性能支持。三种精度配置清晰展示了量化技术的收益:int8相对于fp16速度提升12.8%,显存节省33.9%,质量损失轻微;nf4速度提升20.3%,显存节省59.3%,是资源受限场景的首选 。
llama.cpp(CUDA) 作为跨平台推理生态,其Q8_0量化达到110.3 tokens/s,介于web-rwkv的int8和nf4之间,显存效率更优(3.47GB)。这一结果验证了RWKV与成熟量化生态的兼容性 。
#### 2.1.2 NVIDIA RTX 4060 Ti 8GB平台:中端显卡优化部署
RTX 4060 Ti 8GB代表了更主流的消费级硬件配置,RWKV的量化友好特性在此平台上得到充分体现 :
| 精度 | 速度 (tokens/s) | 显存 (GB) | 相对4090性能 | 适用性 |
|---|
| fp16 | 43.92 | 5.90 | 45.8% | ⚠️ 临界,可能OOM |
| int8 | 62.93 | 3.90 | 58.2% | ✅ 推荐配置 |
| nf4 | 86.03 | 2.40 | 74.5% | ✅ 高效配置 |
关键观察:
nf4配置在4060 Ti上实现了86.03 tokens/s,超过RTX 4090 fp16水平的90%,同时仅占用2.4GB显存。这一"以精度换速度"的策略在中端硬件上尤为有效——显存带宽瓶颈使得更低精度反而提升实际吞吐量 。
#### 2.1.3 AMD RX 7900 XTX平台:跨平台性能表现
AMD GPU通过web-rwkv的Vulkan/ROCm后端获得了出色支持。RX 7900 XTX在int8精度下达到137.36 tokens/s,显著超越RTX 4090同配置(108.22 tokens/s),幅度达27% :
| 平台 | 精度 | 速度 (tokens/s) | 显存 (GB) |
|---|
| NVIDIA RTX 4090 | int8 | 108.22 | 3.90 |
| AMD RX 7900 XTX | int8 | 137.36 | 3.90 |
| NVIDIA RTX 4060 Ti | int8 | 62.93 | 3.90 |
这一结果证明了RWKV架构的硬件无关性优势——其线性复杂度设计使得性能更多地取决于底层矩阵运算效率,而非特定厂商的专有优化。对于追求性价比和硬件多元化的部署场景,AMD平台值得认真考虑 。
2.2 量化技术效果分析
#### 2.2.1 精度-速度-显存三维度权衡
基于RTX 4090/web-rwkv数据,量化效果的定量分析如下 :
| 对比维度 | int8 vs fp16 | nf4 vs fp16 |
|---|
| 速度提升 | +12.8% (95.98→108.22) | +20.3% (95.98→115.46) |
| 显存节省 | -33.9% (5.90→3.90) | -59.3% (5.90→2.40) |
| 质量评级 | 与fp16相当 | 显著低于int8 |
| 推荐场景 | 通用部署默认方案 | 资源受限/边缘部署 |
int8代表了质量-效率的保守平衡点,是生产部署的推荐默认配置。
nf4追求极致效率,20%的速度提升和近60%的显存节省,使其成为边缘设备和多实例部署的理想选择,但需要在具体任务上评估质量影响 。
#### 2.2.2 量化对模型质量的影响评估
RWKV官方文档提供了明确的质量指导 :
- FP16:最高质量,推荐用于质量敏感场景
- INT8:质量与FP16"comparable"(可比较),是最佳平衡选择
- NF4:"significantly lower than INT8",仅用于显存极度受限场景
RWKVQuant研究表明,针对RWKV架构优化的量化方法可将14B模型压缩至约3-bit,精度损失小于1%,速度提升2.14倍 。这一成果验证了RWKV架构对量化的友好性——其线性注意力机制避免了Transformer中常见的异常值敏感问题。
#### 2.2.3 不同推理引擎的量化支持对比
| 引擎 | 支持精度 | 平台覆盖 | 核心特点 |
|---|
| web-rwkv | fp16/int8/nf4 | NVIDIA/AMD/Intel (Vulkan) | 推荐方案,跨平台,最高性能 |
| llama.cpp | Q4_0-Q8_0等GGUF | NVIDIA/AMD/CPU | 生态成熟,格式丰富,工具链统一 |
| RWKV pip | fp16/int8(有限) | NVIDIA (CUDA) | 官方实现,易用性高,性能非最优 |
| Ai00 Server | INT8/NF4 | 跨平台 | 开箱即用API服务器,无PyTorch依赖 |
2.3 长序列处理能力
#### 2.3.1 理论无限上下文:架构层面的原生支持
RWKV最独特的技术优势在于其理论上的无限上下文支持。由于采用递归状态机制而非KV缓存,RWKV处理序列的内存占用与序列长度完全无关——无论是100 token还是100万token,所需的状态内存都是固定的约400KB(典型7B架构)。这一特性使得"无限上下文"成为架构层面的原生能力,而非需要特殊技巧(如滑动窗口、稀疏注意力)来近似实现的功能。
#### 2.3.2 实际部署中的序列长度限制因素
尽管理论无限,实际部署中仍存在实践限制:
- 训练上下文限制:模型在特定长度上训练,超出此范围性能可能逐渐衰减。RWKV支持通过微调扩展有效上下文,社区已有32K、128K乃至更长版本
- 数值稳定性:极长序列的递归计算可能累积数值误差,需要特定的数值处理策略
- 应用层设计:大多数应用不需要真正的无限上下文,RWKV的能力更多作为安全网确保不会因意外长输入而失败
#### 2.3.3 与Transformer架构在长文本上的效率对比
| 指标 | RWKV (线性) | Transformer (标准) | 实际影响 |
|---|
| 时间复杂度 | O(n) | O(n²) | RWKV速度恒定,Transformer急剧下降 |
| 内存复杂度 | O(1) 状态 | O(n) KV-Cache | RWKV显存固定,Transformer线性增长 |
| 100K token显存 | ~400KB | ~20GB+ | RWKV消费级GPU可行,Transformer需企业级集群 |
| 延迟可预测性 | 恒定 | 随上下文增长 | RWKV适合实时系统,Transformer后期卡顿 |
以
100万token序列为例,Transformer的KV-Cache需要约
400GB显存,完全不可行;RWKV仅需约
400KB状态内存,差距达
100万倍 。
3. 基准测试与模型对比
3.1 标准学术基准测试
#### 3.1.1-3.1.3 MMLU、HellaSwag、GSM8K:公开基准数据现状
截至2026年初,RWKV在标准学术基准(MMLU、HellaSwag、GSM8K)上的公开评估数据存在显著缺口。与Llama、Mistral、Gemma等主流模型不同,RWKV项目未系统发布完整的基准测试报告 。这一现状源于RWKV的社区驱动、工程导向发展模式——资源集中于架构开发和效率优化,而非全面的学术评估。
主流模型的已知基准分数提供了参照系 :
| 模型 | 参数 | MMLU | HellaSwag | GSM8K | 训练数据 |
|---|
| Llama-2-7B | 7B | ~45% | ~75% | ~15% | 2T tokens |
| Mistral-7B-v0.1 | 7B | ~60% | ~80% | ~37% | ~2T+ tokens |
| Llama-3-8B | 8B | ~68% | ~78% | ~46% | 15T+ tokens |
| Gemma-2-9B | 9B | ~65% | ~82% | ~50% | 6T tokens |
#### 3.1.4 替代评估方法与间接比较
在直接基准数据缺失的情况下,采用以下替代方法:
开发者报告的性能定位:RWKV官方博客报告EagleX v2(RWKV-v5,14B,2.25T tokens)"明显超过了训练了2万亿token的Llama-2-7B,并且接近Mistral-7B-v0.1和Llama-3-8B" 。若此声明准确,RWKV-5/6 7B级别的MMLU分数可能在55-65%区间,RWKV-7作为更新版本应在此基础上进一步提升。
架构特性推断:RWKV-7的动态状态演化机制突破了TC⁰复杂度限制,理论上增强了表达能力,可能在需要深度推理的基准上表现更优 。
3.2 开发者报告的性能定位
#### 3.2.1 EagleX v2评估结果
EagleX v2是理解RWKV竞争力的关键参考点。该模型在60多项评估中超越Llama-2-7B,在23种主要语言的测试中表现优异,验证了RWKV架构的数据效率和参数效率 。特别值得注意的是,这一成绩是在相对较少的训练数据(2.25T vs Llama-3-8B的15T+)下取得的,表明RWKV架构能够从同等数据中提取更多有效信号。
#### 3.2.2 多语言评估
RWKV的多语言优势有明确的架构和训练基础。专门优化的多语言tokenizer、3.1T tokens的多语言训练数据、以及社区对非英语场景的持续关注,使得RWKV在中文、日语等语言上的零样本和少样本性能优于多数同规模开源模型 。
#### 3.2.3 长文本专项评估
RWKV-7-World-3-2.9B在处理长达35000 token的上下文时仍能保持较高准确率 。虽然缺乏与LongBench等标准基准的直接对比,但架构的线性复杂度优势在理论上不可逾越,实际部署反馈也支持这一推断。
3.3 主流开源模型性能参考
#### 3.3.1-3.3.3 Llama、Mistral、Gemma系列定位
| 系列 | 核心优势 | 典型场景 | 相对RWKV |
|---|
| Llama | 生态完善,工具链丰富,社区最大 | 通用对话,RAG系统 | 效率落后,生态领先 |
| Mistral | 推理速度,指令遵循,欧洲背景 | 实时聊天,客户支持 | 效率相当,架构传统 |
| Gemma | Google优化,多模态扩展,轻量 | 研究实验,移动部署 | 定位重叠,效率劣势 |
#### 3.3.4 RWKV竞争力综合分析
| 评估维度 | RWKV定位 | 关键依据 |
|---|
| 效率 | 显著领先 | 线性复杂度,无KV-Cache,数量级优势 |
| 质量 | 接近竞争 | 开发者报告接近Mistral-7B/Llama-3-8B |
| 多语言 | 优势领域 | 专门优化,社区反馈积极 |
| 长文本 | 架构领先 | 理论无限,实际验证达35K+ token |
| 生态 | 明显落后 | 工具链、微调资源、社区规模差距 |
3.4 实际任务表现维度
#### 3.4.1 代码生成与补全能力
RWKV-7-G1系列明确强化了代码和数学能力 。社区开发了基于RWKV的代码补全模型 ,递归状态机制对于结构化输出(如代码)的生成可能具有优势——状态机制有助于维护语法结构的长期一致性。
#### 3.4.2 多轮对话与上下文保持
RWKV的恒定每步延迟确保了对话长度增加时响应时间的稳定性,不会出现Transformer中常见的"对话越久越慢"现象。这一特性对于生产级聊天系统至关重要,支持真正的"无限记忆"助手 。
#### 3.4.3 实时流式生成质量
RWKV被明确推荐用于"real-time streaming, chaining short prompts"场景 。其稳定的低延迟特性使其成为语音助手、实时翻译等时间敏感应用的有力候选,状态机制天然支持高效的提示链接。
4. 应用场景与部署实践
4.1 核心应用场景推荐
#### 4.1.1 长文档处理:无限上下文支持的法律、学术、金融文本分析
RWKV的线性复杂度架构使其成为长文档处理的理想选择。法律合同审查、学术论文综述、金融报告摘要等场景通常需要处理数万至数十万token的输入。RWKV可以完整摄入文档,保持全局连贯的理解,而无需Transformer的分段截断策略 。
部署建议:采用RWKV-6/7 7B-14B模型,int8或nf4量化,配合提示工程引导模型关注特定方面。对于超大规模文档(百万字级别),可采用分层摘要策略——先用RWKV生成章节摘要,再基于摘要进行全局整合。
#### 4.1.2 实时交互系统:低延迟要求的聊天机器人与虚拟助手
低延迟是对话系统的核心指标。研究表明,超过300ms的响应延迟会显著降低用户满意度。RWKV的恒定每token推理时间确保了无论对话历史多长,生成速度保持稳定 。对比测试显示,RWKV 4x量化模型在CPU上的延迟约58ms,优于多数同规模Transformer的量化版本 。
#### 4.1.3 边缘与端侧部署:量化后的轻量级推理需求
RWKV7-G1-2.9B的nf4配置仅需2.4GB显存,在RTX 4060 Ti上达到86 tokens/s ,这一性能水平足以支持流畅的本地对话体验。移动端部署同样可行——高通骁龙8 Gen 3平台上,A16W4配置达到31.3 tokens/s ,对于非实时应用已具实用价值。
#### 4.1.4 流式内容生成:连续短提示链式处理
RWKV被明确推荐用于"chaining short prompts, avoiding attention matrix blow-up"场景 。Agent系统、工作流自动化等新兴应用涉及大量短提示的连续执行,RWKV的状态机制天然支持高效的提示链接——状态向量作为紧凑的上下文表示,在不同提示间传递,无需重复处理历史信息。
4.2 模型版本选择指南
| 显存预算 | 推荐配置 | 预期性能 | 典型应用 |
|---|
| <4GB | RWKV7-G1-2.9B nf4 | 20-40 t/s (GPU), 可用 (CPU) | 边缘设备,轻量助手,离线处理 |
| 8GB | RWKV7-G1-2.9B int8 或 RWKV-6 7B nf4 | 60-110 t/s | 标准部署,日常对话,文档处理 |
| 16GB | RWKV-6/7 7B int8 或 14B nf4 | 40-80 t/s | 高性能应用,长文本,代码生成 |
| 24GB+ | RWKV-6/7 14B fp16/int8 | 30-60 t/s | 服务器部署,质量优先,研究用途 |
| 推理专用 | RWKV-7-G1系列 | 依配置 | 数学推理,代码生成,多步思考 |
4.3 部署工具与教程
#### 4.3.1 web-rwkv引擎:推荐方案
环境依赖:Rust工具链(cargo)、Vulkan驱动(NVIDIA/AMD/Intel均支持),无需CUDA Toolkit或PyTorch
安装命令:
git clone https://github.com/cryscan/web-rwkv
cd web-rwkv && cargo build --release
基础推理:
./target/release/web-rwkv \
--model RWKV7-G1-2.9B.safetensors \
--strategy "cuda int8" \
--prompt "Your prompt" --max-tokens 512
多精度策略:"cuda fp16"(全精度)、"cuda int8"(推荐平衡)、"cuda nf4"(极致效率)、"vulkan int8"(跨平台)
#### 4.3.2 llama.cpp生态
# 转换为GGUF格式
python convert-rwkv-to-gguf.py --input model.pth --output model.gguf
# 量化与推理
./quantize model.gguf model-Q8_0.gguf Q8_0
./main -m model-Q8_0.gguf -p "Prompt" -n 512
#### 4.3.3-4.3.4 其他方案与云端部署
- RWKV pip:
pip install rwkv,适合快速原型
- Ai00 Server:基于web-rwkv的API服务器,开箱即用
- 云端Docker:容器化web-rwkv服务,配合FastAPI或Triton Inference Server
4.4 性能优化实践
#### 4.4.1 批处理策略
RWKV的常数内存特性使得批处理扩展更为高效。相同显存预算下可支持更大的批次或更长的样本,建议根据GPU利用率和延迟要求探索最优批大小 。
#### 4.4.2 内存管理
长上下文场景下,输入编码的激活内存成为瓶颈。可采用渐进式处理——分段编码后合并状态,平衡内存与效率。状态向量的小体积(~400KB)也便于跨设备传输和持久化 。
#### 4.4.3 多GPU扩展
RWKV的层内计算密集特性适合张量并行,状态向量的小体积降低了通信开销。DeepSpeed等框架可用于大规模分布式部署 。
5. 竞争优势与发展展望
5.1 核心差异化优势
#### 5.1.1 效率与性能的平衡:线性复杂度下的竞争力表现
RWKV重新定义了效率与性能的权衡边界。在Transformer架构主导的时代,长上下文、低延迟、边缘部署往往意味着巨大的资源投入或显著的质量妥协。RWKV通过架构创新,证明了线性复杂度下仍可实现 competitive 的模型质量,为AI能力的普惠化提供了技术基础 。
#### 5.1.2 硬件友好性:消费级GPU上的卓越推理效率
RWKV对消费级GPU的高效利用——RTX 4060 Ti即可流畅运行7B级别模型,RTX 4090上115+ tokens/s的峰值速度——使得高质量语言模型真正 accessible 到普通用户。这一特性对于个人开发者、中小企业、以及算力受限地区尤为重要 。
#### 5.1.3 架构简洁性:训练与部署的工程复杂度降低
无KV-Cache设计大幅简化了推理引擎的实现,RWKV核心推理代码可数百行内实现,便于审计、定制和移植。这种简洁性对于安全敏感场景和新型硬件适配具有价值 。
5.2 当前局限性与挑战
#### 5.2.1-5.2.3 生态、工具链与透明度
| 挑战领域 | 具体表现 | 缓解方向 |
|---|
| 生态系统成熟度 | 微调模型、应用案例、社区规模落后于Llama/Mistral | 持续开源,社区建设 |
| 工具链完善度 | RLHF微调、多模态扩展、企业级工具待完善 | 重点投入,生态合作 |
| 基准测试透明度 | 缺乏系统的MMLU/HellaSwag/GSM8K公开报告 | 第三方评估,学术合作 |
5.3 技术演进方向
#### 5.3.1-5.3.3 未来展望
- RWKV-7及后续版本:动态状态演化机制为复杂推理、规划、工具使用奠定基础,能力边界持续拓展
- 多模态扩展:VisualRWKV等视觉-语言融合方向,将架构优势延伸至跨模态场景
- 推理能力强化:GooseOne等专用版本的迭代,针对数学、代码、科学推理等任务深度优化
RWKV的长期愿景是成为
高效AI的默认选择——当应用场景对效率敏感时,开发者首先考虑RWKV架构。实现这一愿景需要持续的技术创新、生态建设和社区培育,但架构的 fundamental 优势为此提供了坚实基础。