深入探讨Transformer架构的核心挑战,分析Causal Grassmann Transformer模型如何从根本上解决计算复杂度与可解释性两大难题
从O(n²)降低到O(n),显著提升长序列处理效率 基于Grassmann流形的内在可解释架构
《Attention Is All You Need》的L2平方复杂度与"黑盒"问题:
替代方案深度研究及新模型分析
线性复杂度
几何可解释性
自2017年Vaswani等人发表开创性论文《Attention Is All You Need》以来,基于Transformer架构的模型已成为自然语言处理乃至整个深度学习领域的基石。然而,随着模型规模的指数级增长和应用场景的不断拓宽,Transformer架构固有的两个核心挑战也日益凸显:自注意力机制带来的二次方计算复杂度和"黑盒"特性。
"论文《Attention Is Not What You Need》中提出的Causal Grassmann Transformer模型,为应对标准Transformer的L2平方复杂度和'黑盒'可解释性两大核心挑战,提供了一种极具创新性的综合解决方案。"
自注意力机制的核心计算过程涉及计算序列中所有token对之间的相互关系。对于长度为n的输入序列,每个token都会被线性映射为查询向量Q、键向量K和值向量V。
最关键的步骤是生成n×n的注意力分数矩阵,这导致了二次方复杂度的产生。
[41]
QKᵀ矩阵乘法 Softmax操作 加权求和
综合来看,自注意力层的时间复杂度主要由O(n²·d_k)和O(n²·d_v)决定,可以近似表示为O(n²·d)。
[41]
Transformer模型的"黑盒"特性主要体现在其决策过程的不可知性。当一个模型做出预测时,我们很难确切地知道它是依据哪些输入特征、通过怎样的内部逻辑得出这个结论的。
论文《Attention Is Not What You Need》深刻指出,Transformer的核心操作是一种"高维张量提升",将每个token的d维隐藏状态向量提升到一个L×L的成对兼容性张量空间。
[72]
高维张量空间 L²个元素的成对交互空间 自由度大 多层多头中注意力张量云演化 数学上不可追踪 缺乏明确的不变量族描述全局效应Transformer模型的核心挑战
L2平方复杂度问题
自注意力机制的计算瓶颈
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
复杂度分析:O(n²d)的时间与空间复杂度
"黑盒"问题
模型可解释性的缺失
高维张量操作的不可追踪性
问题的核心
从根本上设计本身就具备可解释性的"白盒"模型,如CRATE(Coding and Rate Reduction Transformer)。
[63]
将深度学习模型建立在更坚实的数学或物理基础之上,与具有明确几何或物理意义的操作联系起来。
现有替代方案综述
针对L2平方复杂度的优化方案
针对"黑盒"问题的解决方案
白盒化Transformer架构
基于几何或物理原理的模型设计
该论文的根本性问题是:显式的L×L自注意力权重张量,是否真的是实现强大序列建模和推理能力所必需的根本要素?
[72]
作者的答案是否定的。他们认为注意力机制只是实现隐藏表示几何演化的一种特定实现。
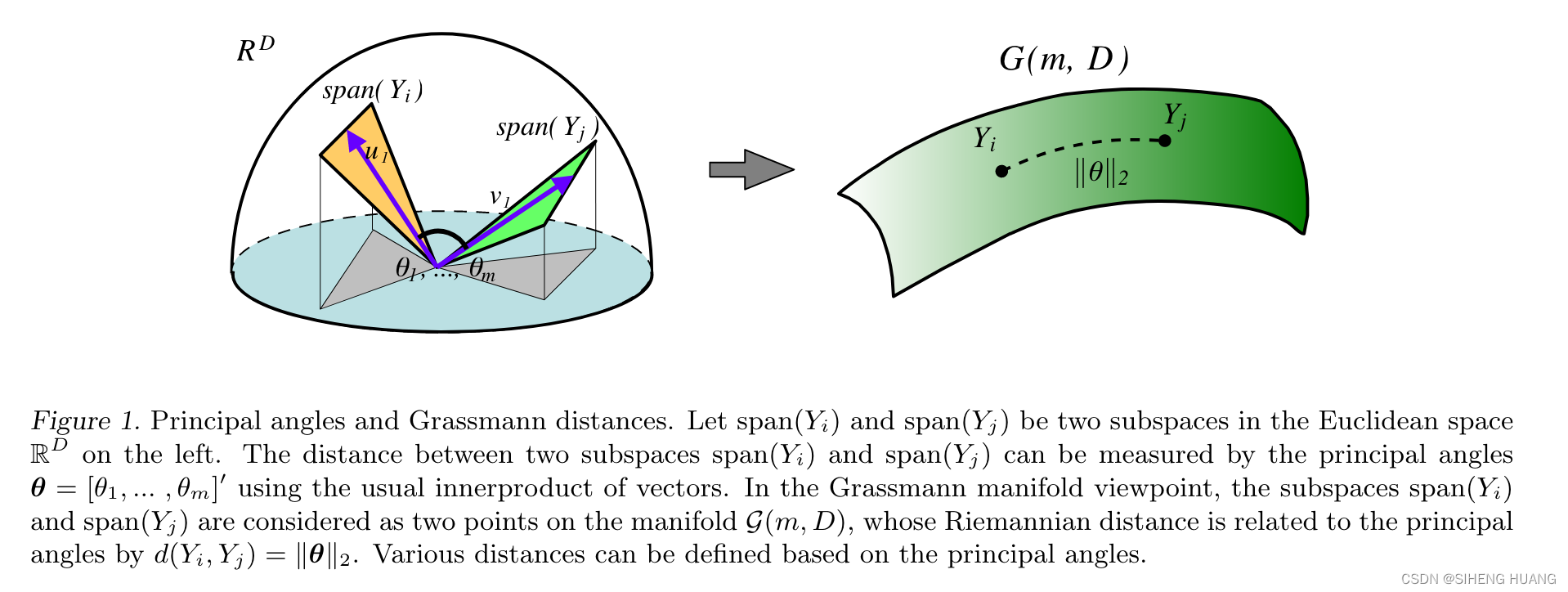
Grassmann流形Gr(k, n)是所有n维向量空间中k维子空间的集合。模型将token的隐藏状态解释为流形上的点。
subgraph Grassmann["Causal Grassmann Transformer"]
G1["输入序列"] --> G2["词嵌入"]
G2 --> G3["位置编码"]
G3 --> G4["降维投影"]
G4 --> G5["子空间构建"]
G5 --> G6["Plücker嵌入"]
G6 --> G7["门控融合"]
G7 --> G8["输出"]
end style Traditional fill:#f1f5f9,stroke:#374151,stroke-width:2px
style Grassmann fill:#f0fdfa,stroke:#0f766e,stroke-width:2px
style T4 fill:#fee2e2,stroke:#dc2626,stroke-width:2px
style G5 fill:#d1fae5,stroke:#059669,stroke-width:2px
style G6 fill:#d1fae5,stroke:#059669,stroke-width:2px
将输入序列的每个token的d维隐藏状态h_t通过可学习的线性变换W_down ∈ R^(d×r)投影到r维的低维空间。
在局部因果性窗口内,选取token对(i,j),将对应的低维向量z_i和z_j组合成2×r矩阵。
使用Plücker坐标将子空间嵌入到射影空间,通过对2×r矩阵的两行进行外积运算得到。
通过将token状态降维到低维空间再进行几何操作,模型的核心机制从一个难以分析的"黑盒"张量空间,转移到了一个数学上结构清晰、性质明确的流形上。
[72]
标准Transformer 自注意力机制 稀疏注意力 Longformer/BigBird Causal Grassmann 线性复杂度
复杂度分析:Causal Grassmann Transformer在固定子空间秩r的情况下,计算复杂度随序列长度L线性增长。
[72]
新模型分析:Causal Grassmann Transformer
论文《Attention Is Not What You Need》核心思想
提出无注意力机制的序列模型
基于Grassmann流形的几何方法
Causal Grassmann Transformer架构对比
模型设计与机制
降维投影
z_t = h_t W_down
子空间构建
Plücker嵌入
几何解释与可解释性
从"高维张量提升"到"低维几何演化"
复杂度与性能分析
复杂度对比分析
实验结果:与标准Transformer的性能对比
任务
数据集
模型
性能指标
结果
对比
语言建模
Wikitext-2
Causal Grassmann LM
验证集困惑度
与基线差距10-15%
性能接近,证明可行性
自然语言推理
SNLI
DistilBERT + Grassmann Head
验证集准确率
0.8550
优于Transformer (0.8545)
自然语言推理
SNLI
DistilBERT + Grassmann Head
测试集准确率
0.8538
优于Transformer (0.8511)
Causal Grassmann Transformer通过将token交互从计算昂贵的矩阵代数转换到几何意义明确的Grassmann流形上,实现了双重突破。
优势: 局限性:
Causal Grassmann Transformer的成功证明了"无注意力"序列建模的可行性,将激励更多研究者跳出注意力机制的框架。
该模型是几何深度学习思想在序列建模领域的成功应用,为将其他几何和拓扑工具引入深度学习提供了范例。
结论与展望
综合解决方案的潜力
同时解决复杂度和可解释性问题
优势与局限性
未来研究方向
无注意力机制模型的发展
几何深度学习的应用前景
"Causal Grassmann Transformer的出现,为解决Transformer的固有缺陷提供了一个极具潜力的综合解决方案,标志着序列建模领域开始从'注意力中心论'向更多元化的几何方法探索。"