Vision-Language-Action Models
for Video Object Detection
A comprehensive strategic analysis of VLA models as supplementary and alternative solutions to Gemma 4 for intelligent video analysis systems

VLA models are fundamentally designed for robotic control, creating natural limitations for traditional MOT tasks requiring 30+ fps performance. Optimal deployment combines YOLO/ByteTrack for real-time detection with VLA semantic enrichment at 5-10 frame intervals. VLA models excel as semantic supervisors, providing open-vocabulary recognition and temporal reasoning that complements high-speed pipelines.Structural Mismatch
Hybrid Architecture
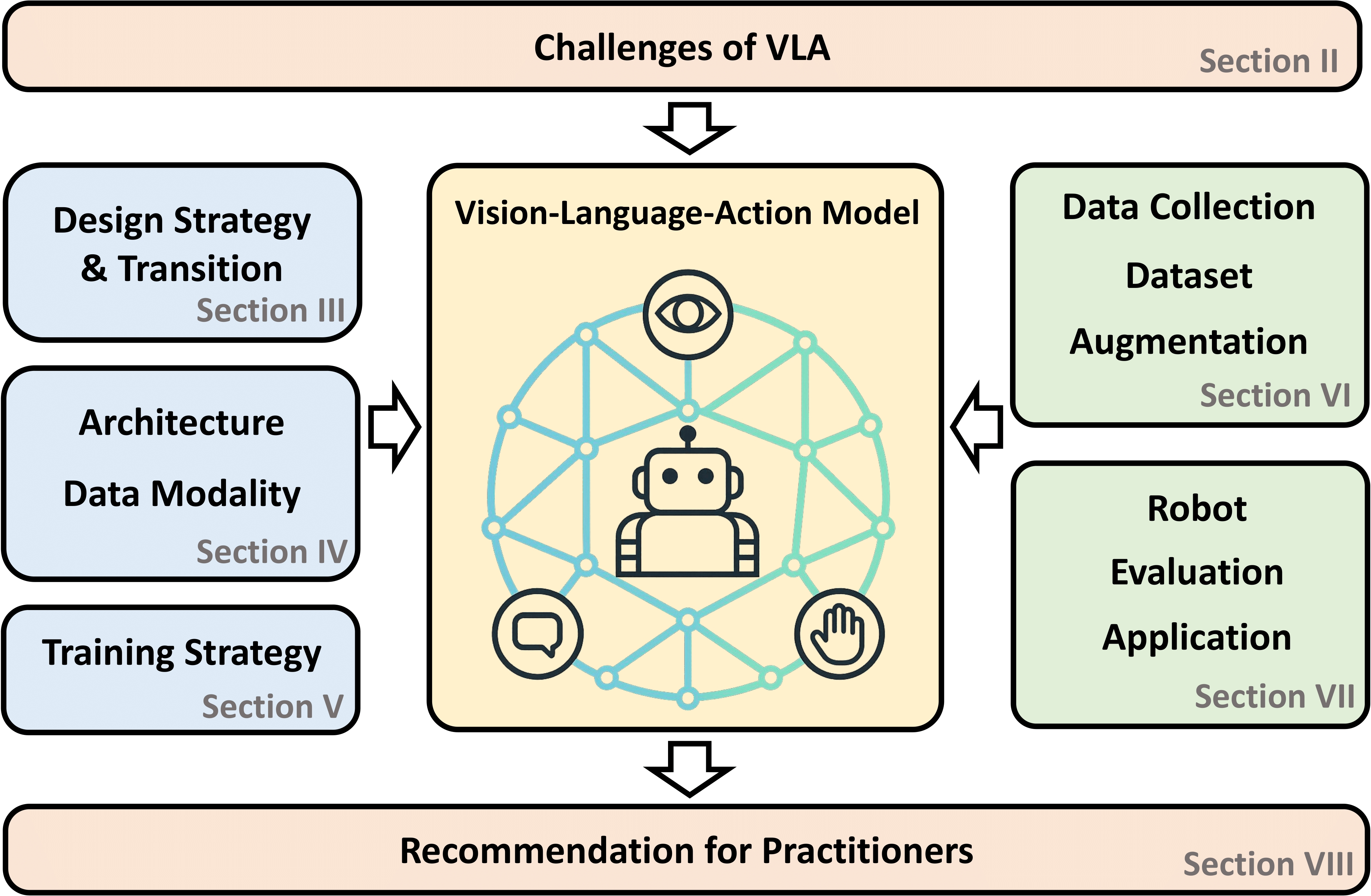
Intelligent Brain
VLA models are fundamentally architected to bridge the gap between high-level semantic understanding and low-level physical execution. Unlike conventional computer vision systems that terminate at perception outputs, VLA models are designed to ingest visual observations alongside natural language instructions and directly generate executable action signals for robotic systems.
"The robotic control imperative shapes every layer of VLA architecture, from vision encoder selection to action head design."
VLA models can recognize and reason about novel object categories, attributes, and relationships described in natural language, enabling zero-shot generalization. Explicit mechanisms for temporal reasoning through multi-frame input support and visual trace prompting. Full-scale VLA models achieve only ~1-5 fps, orders of magnitude below the 30+ fps required for real-time MOT applications. Absence of explicit bounding box + ID output mechanisms, generating continuous action vectors instead of detection-compatible formats. Diffusion/flow-matching outputs optimize for trajectory likelihood rather than frame-by-frame detection precision.Foundational Positioning
VLA Design Philosophy
End-to-End Robotic Control
Perceptual Capabilities
Open-Vocabulary Understanding
Temporal Reasoning
Fundamental Limitations
Frame Rate Constraints
Output Format Mismatch
Architecture Mismatch
SigLIP + DINOv2 fusion provides both semantic alignment and geometric understanding, yielding 256 rich visual tokens per image. Well-established language model enabling cross-modal reasoning with 4096-token context for extended temporal sequences. π0.5 introduces flow matching for continuous action generation, replacing discrete tokenization with direct trajectory regression for smoother, more physically plausible motions up to 50 Hz control rates. Built on Google's flagship multimodal model with native multi-frame video processing and exceptional language understanding. Specialized training for fine-grained hand control, developing precise visual-motor coordination for tracking small, fast-moving targets. Lightweight edge deployment option with 10-100× efficiency improvement, enabling practical real-time applications. Humanoid-centric design with NVIDIA robotics stack co-optimization. Trained on massive synthetic data from Isaac Sim, emphasizing bimanual manipulation and spatial coordination. Dual-system architecture (System 1/2) for reactive vs. deliberative control. Focus on full-body humanoid motion planning with video context awareness.Comparative Model Analysis
Leading VLA Models Comparison
Model
Parameters
Open Source
Video Capabilities
Real-time
Recommendation
OpenVLA
7B
✓ Full (HF)
Strong open-vocab perception, multi-frame training
Low~Medium
High
π0 / π0.5
~2B-7B
~ Partial
Excellent open-world generalization, spatial reasoning
Medium
High
Gemini Robotics
Large
~ On-Device
Gemini 2.0 base, multi-frame video processing
Medium
Medium-High
GR00T N1 (NVIDIA)
-
~ Partial
Humanoid robot video + synthetic data
Medium
Medium
SmolVLA
Small
✓ Open
Compact, efficient for edge devices
Medium-High
High
OpenVLA: The Open-Source Baseline
Architecture Specifications
Dual Vision Encoder
Llama 2 7B Backbone
Performance Profile
π0 Series: Open-World Generalization
Architectural Innovation
Key Advantages:
Empirical Results
Gemini Robotics: Ecosystem Integration
Gemini 2.0 Foundation
Dexterous Manipulation
On-Device Variant
Hardware-Aligned Alternatives
GR00T N1 (NVIDIA)
Helix (Figure AI)
Complex referring expressions and conditional specifications without specialized engineering. Object state maintenance through action sequence generation with natural motion priors. 30-100+ fps throughput with explicit optimization for speed-precision tradeoffs. Interpretable debugging and predictable failure modes with consistent identity labels.
The appropriate conceptualization positions VLA models as "intelligent brains" that augment rather than replace "front-end detectors." This architectural pattern preserves real-time performance while leveraging VLA capabilities for semantic enrichment.
High-frequency perception engine (30+ fps) Semantic supervisor (5-10 fps interval) Visual-language interface (analysis-focused)Functional Role Assessment
Capability Mapping Across Paradigms
Traditional Detectors
VLA Models
Gemma 4
Performance Tradeoffs Analysis
VLA Advantages
Natural Language Interface
Implicit State Tracking
Traditional Pipeline Advantages
Real-time Performance
Explicit Association
Complementary Rather Than Substitutive
Front-End Detector
VLA Model
Gemma 4
YOLO/YOLO-World at 30+ fps ByteTrack/DeepSORT for identity preservation 5-10 frame interval processing Semantic analysis corrects association errors through long-term identity consistency checks and re-identification after occlusion. Coarse detector categories replaced by fine-grained VLA identifications with backward propagation to trajectory history. Direct velocity commands and waypoint sequences for robotic platforms following tracked targets. Behavior-based alert generation with natural language specification of complex alert conditions. Dynamic VLA invocation frequency based on scene complexity and motion magnitude. Non-blocking VLA processing with result buffering and temporal interpolation. Fallback to pure traditional pipeline under resource pressure or complexity spikes.Hybrid Architecture Design
Tiered Processing Framework
High-Speed Detection
Per-Frame Processing
Performance Targets
Temporal Association
Tracking Functions
Association Methods
Semantic Enrichment (VLA)
Open-Vocabulary Recognition
Behavior Understanding
Action Generation
Information Flow Integration
VLA → Tracker Updates
Identity Verification
Dynamic Label Refinement
VLA → Downstream Control
Action Command Generation
Intelligent Alert Triggering
Latency-Aware Scheduling
Adaptive Frame Sampling
Asynchronous Inference
Graceful Degradation
Behavior understanding and alert prioritization with hybrid architecture. Language-guided association across viewpoint changes. Activity classification and pattern recognition over extended periods. Physics-informed motion forecasting for traffic participants. Behavioral cue interpretation for pedestrian intent prediction. Situation assessment and emergency planning for wrong-way drivers. Tensor G4 and equivalent platforms Jetson, Snapdragon, IoT processors Microcontrollers, embedded systemsScenario-Specific Deployment
Robotics-Centric Applications
Visual Servoing & Grasp Planning

Intelligent Video Surveillance
Application Requirements
Real-time Anomaly Detection
Cross-Camera Re-ID
Long-term Behavior Analysis
VLA Role & Benefits
Autonomous Driving Perception
Multi-Agent Interaction
Vulnerable Road Users
Anomaly Response
Edge and Embedded Deployment
High-End Mobile
General Edge
Ultra-Low Power
224×224 or 336×336 for optimal balance of detail and speed 4-8 frames for dynamic scenes, sufficient for motion understanding Include distinguishing attributes to reduce ambiguity Calibrate on domain-specific validation sets Beyond standard MOT metrics, VLA-integrated systems require action-correctness assessment—evaluating whether VLA-generated actions appropriately respond to tracked events through task-specific protocol development.Implementation Pathways
OpenVLA Quick-Start Protocol
Environment Setup
Model Loading
model = AutoModelForVision2Seq.from_pretrained("openvla/openvla-7b", torch_dtype=torch.float16, device_map="auto")
processor = AutoProcessor.from_pretrained("openvla/openvla-7b")
Key Implementation Considerations
Frame Resolution
Temporal Context
Query Specificity
Confidence Thresholding
YOLO-VLA Integration Code Pattern
class HybridTrackingSystem:
def __init__(self):
self.detector = YOLO("yolov8x-worldv2.pt") # 30+ fps
self.tracker = ByteTrack() # Real-time association
self.vla = OpenVLAWrapper() # 5-10 fps semantic enrichment
self.vla_queue = asyncio.Queue(maxsize=4) # Async buffering
async def process_frame(self, frame):
# Layer 1: High-speed detection (every frame)
detections = self.detector(frame, verbose=False)[0]
# Layer 2: Temporal association (every frame)
tracks = self.tracker.update(detections)
# Layer 3: Async VLA enrichment (every 5-10 frames)
if self.frame_count % self.vla_interval == 0:
await self.vla_queue.put({
'frame': frame,
'tracks': tracks,
'timestamp': time.time()
})
# Apply available VLA results with temporal interpolation
enriched_tracks = self.apply_vla_updates(tracks)
return enriched_tracks
async def vla_worker(self):
while True:
item = await self.vla_queue.get()
vla_output = await self.vla.process(
frames=self.get_temporal_window(item),
query=self.generate_tracking_query(item['tracks'])
)
self.update_track_cache(item['timestamp'], vla_output)
Evaluation and Benchmarking Framework
Detection Quality
Tracking Performance
Semantic Accuracy
Novel Evaluation Dimension
Native bounding box + ID output through auxiliary heads, as demonstrated by UAV-Track VLA's 55% success rate on unseen pedestrian tracking. Task-optimal hybrids combining detector speed with VLA reasoning through automated design space exploration. Sub-second frame rates with >90% capability retention through teacher-student knowledge transfer. Microsecond effective latency through asynchronous visual sensing and sparse processing. Visual-language-audio integration for surveillance with acoustic event detection. Theory-of-mind modeling for crowd monitoring and public safety applications. Future Trajectory and Research Frontiers
Architectural Convergence
Detection-Specific VLA Design
Neural Architecture Search
Efficiency Breakthroughs
Progressive Distillation
Event-Camera Integration
Expanded Task Horizons
Multi-Modal Tracking
Social Behavior Prediction
Research Frontiers Timeline
Vision-Language-Action models represent a transformative but strategically bounded capability for video object detection and tracking applications. Their core design for robotic end-to-end control creates fundamental mismatches with traditional MOT requirements—particularly the ~1 fps inference speeds versus 30+ fps real-time needs, and the implicit action outputs versus explicit bounding box + ID expectations.
Not incidental engineering challenges but architectural consequences of VLA's distinctive strengths Traditional pipelines + VLA semantic enrichment + Gemma 4 analysis interface OpenVLA offers complete open-source availability with established community support OpenVLA - Fully open, established community, proven LoRA adaptability SmolVLA - Practical efficiency without catastrophic capability loss π0.5 - State-of-the-art open-world performance Gemini Robotics - On-device deployment advantages The field is evolving rapidly. The strategic practitioner will monitor developments while deploying today's capabilities in architectures that leverage genuine strengths without demanding performance they cannot deliver.Strategic Conclusion
Structural Limitations
Complementary Architecture
Accessible Entry Point
Recommended Starting Points
For General Exploration
For Resource-Constrained
For Superior Generalization
For Google Ecosystem
Strategic Imperative