以下从数学底层剖开 GFT 的肌理,逐层递进,不避繁难。
---
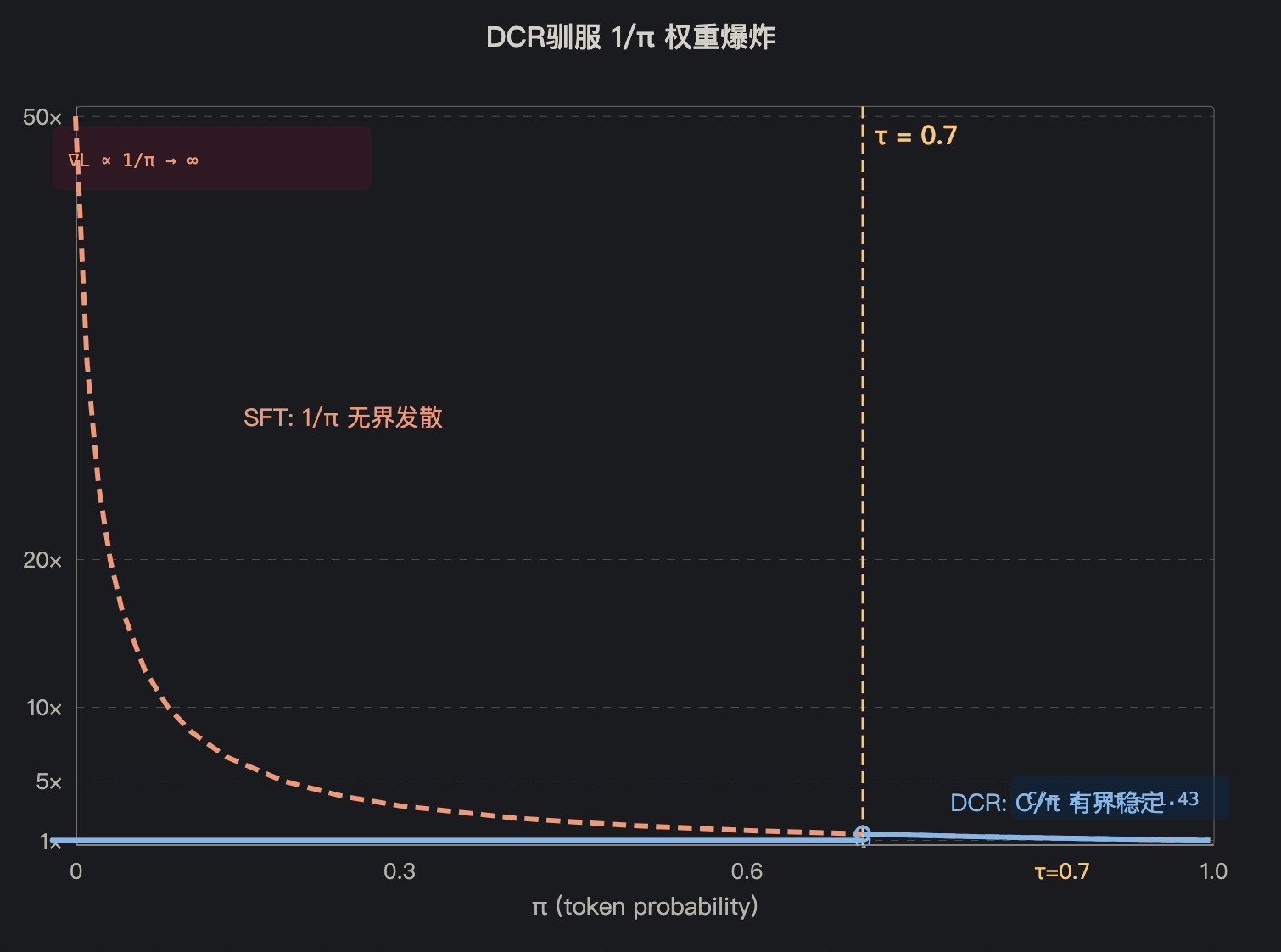
在开讲之前,先看一道图——DCR 如何驯服 $1/\pi$ 的爆炸性:
{kind=link}
图中所见,即 DCR 的核心功:$1/\pi$ 在低概率区如脱缰野马,C/π 却老僧入定,变化幅度不过 1 到 1.43 之间。
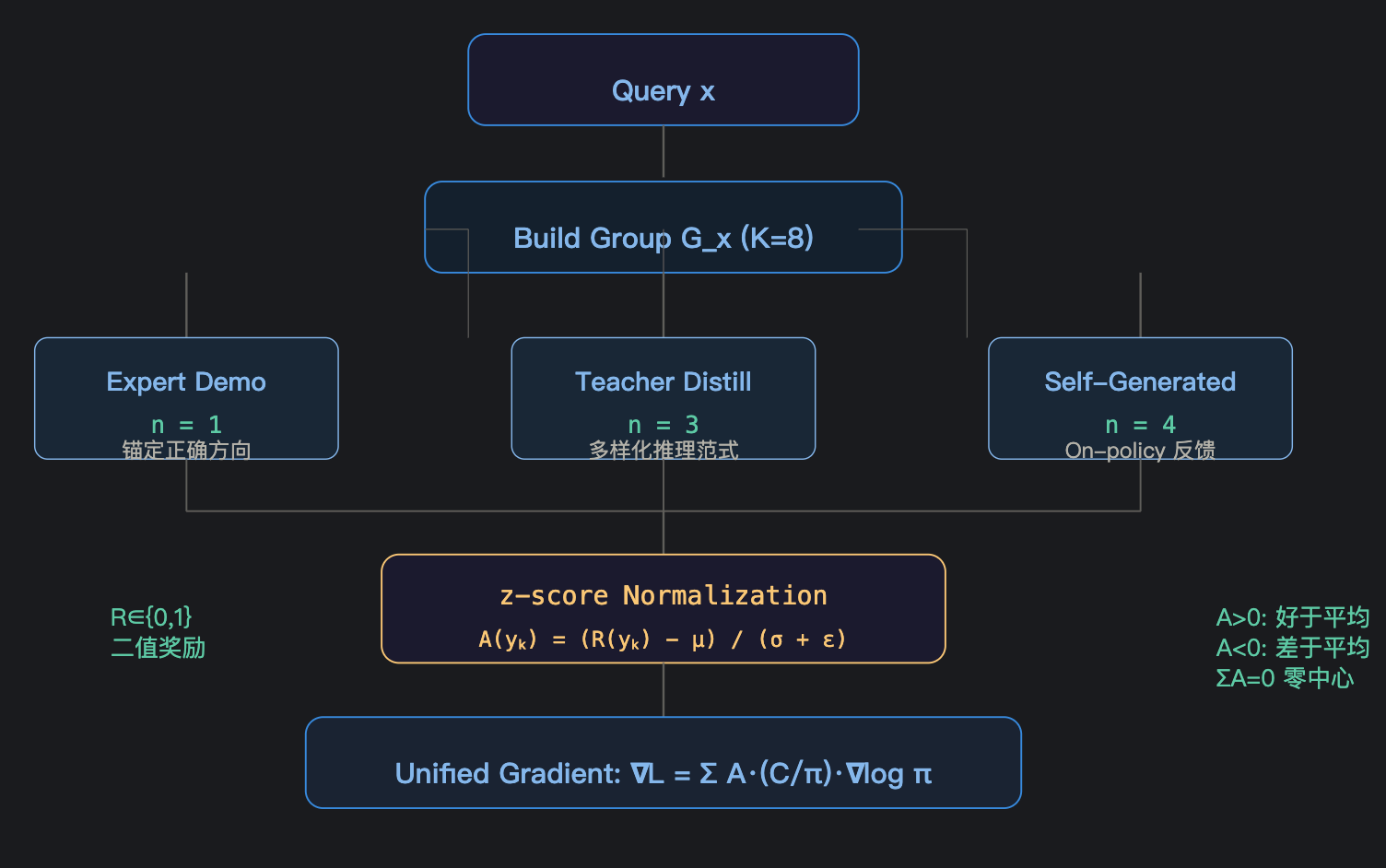
再看第二图——GAL 的群体构建与优势计算:
{kind=link}
---
以下便是 GFT 的数学内核,分七重探究,逐层剥开。
---
第一重:SFT 何以是 RL 的退化形式
SFT 的标准交叉熵损失为:
$$\mathcal{L}_{\text{SFT}} = -\mathbb{E}_{(x, y^*) \sim \mathcal{D}} [\log \pi_\theta(y^* | x)]$$
其梯度可以直写:
$$\nabla_\theta \mathcal{L}_{\text{SFT}} = -\mathbb{E}_{(x, y^*) \sim \mathcal{D}} [\nabla_\theta \log \pi_\theta(y^* | x)] \tag{1}$$
此式干净利落,但掩藏了深层结构。令 $\pi_{\text{expert}}(y|x) = \delta(y - y^*)$ 为 Dirac 脉冲(专家分布只在 $y^*$ 处有非零密度),作重要性采样:
$$\nabla_\theta \mathcal{L}_{\text{SFT}} = -\mathbb{E}_{y \sim \pi_\theta(\cdot|x)} \left[ \frac{\delta(y - y^*)}{\pi_\theta(y|x)} \nabla_\theta \log \pi_\theta(y|x) \right]$$
$$= -\mathbb{E}_{y \sim \pi_\theta(\cdot|x)} \left[ \frac{\mathbb{I}[y = y^*]}{\pi_\theta(y|x)} \nabla_\theta \log \pi_\theta(y|x) \right] \tag{2}$$
与 REINFORCE 的策略梯度对照:
$$\nabla_\theta J_{\text{REINFORCE}} = \mathbb{E}_{y \sim \pi_\theta} [R(y) \nabla_\theta \log \pi_\theta(y)] \tag{3}$$
SFT 的梯度可视为 REINFORCE 的变体,其中:
$$R_{\text{SFT}}(y) = -\mathbb{I}[y = y^*]$$
权重因子 $1/\pi_\theta(y|x)$ 为重要性采样权重。此即 GFT 论文的核心洞察:SFT 并非"非 RL",它是 RL 的一种退化实例——奖励函数极度稀疏(二值),重要性权重无界(发散)。
---
第二重:$1/\pi$ 的方差灾难——一个矩分析
考虑单个 token $t$ 对梯度的贡献。设自回归分解下 $y = (y_1, \ldots, y_T)$,条件概率 $\pi_t = \pi_\theta(y_t | x, y_{ $$\Delta_t^{\text{SFT}} = \frac{\mathbb{I}[y_t = y_t^*]}{\pi_t} \cdot \nabla_\theta \log \pi_t \tag{4}$$ 问题在于标量因子 $w_t = 1/\pi_t$ 的统计行为。 $\pi_t$ 是 softmax 输出,取值于 $(0, 1]$。设其分布密度为 $p(\pi)$(在训练数据上自然形成),则 $w_t$ 的矩: $$\mathbb{E}[w_t] = \int_0^1 \frac{1}{\pi} \cdot p(\pi) \, d\pi$$ $$\text{Var}[w_t] = \int_0^1 \frac{1}{\pi^2} \cdot p(\pi) \, d\pi - \mathbb{E}[w_t]^2$$ 核心在于:当 $\pi \to 0$ 时,$1/\pi$ 和 $1/\pi^2$ 均无界。即便 $p(\pi)$ 在 $\pi \to 0$ 处衰减,只要 $p(0) > 0$ 或 $p(\pi)$ 的衰减速率低于 $O(\pi^2)$,则方差发散: $$\text{Var}[w_t] \to \infty$$ 实证上,语言模型的 token 概率分布尾部重(rare tokens 的 $\pi_t$ 可低至 $10^{-4}$ 乃至更低),对应 $w_t$ 达到 $10^4$ 量级。这意味着:
---
第三重:DCR 的矩分析与偏倚-方差权衡
DCR 引入修正系数 $C(\pi_t)$,使有效权重变为:
$$w_t^{\text{DCR}} = \frac{C(\pi_t)}{\pi_t}$$
其中:
$$C(\pi_t) = \begin{cases} \text{sg}(\pi_t) & \pi_t < \tau \\ 1 & \pi_t \geq \tau \end{cases}$$
sg 为 stop-gradient 操作——前向传播保持原值,反向传播视为常数。
核心性质:对任意 $\pi_t < \tau$,有 $C(\pi_t)/\pi_t = \text{sg}(\pi_t)/\pi_t$。由于 $\text{sg}(\pi_t)$ 在反向传播中充当常数(值为 $\pi_t$),有效梯度的标量因子实为:
$$w_t^{\text{eff}} \approx 1, \quad \forall \pi_t < \tau$$
(严格地说,前向乘 $\pi_t$ 除 $\pi_t$ 得 1;反向 $\text{sg}$ 阻断对 $\pi_t$ 的依赖。)
因此 DCR 的有效权重分布为:
$$w_t^{\text{DCR}} \in \begin{cases} [1 - \delta, 1 + \delta] & \pi_t < \tau \\ [1, 1/\tau] & \pi_t \geq \tau \end{cases}$$
其中 $\delta$ 来自数值误差。取 $\tau = 0.7$,则 $1/\tau \approx 1.43$。
矩的对比:
| 量 | 原始 $1/\pi_t$ | DCR $C(\pi_t)/\pi_t$ |
|---|---|---|
| 值域 | $[1, \infty)$ | $[0, 1.43]$ |
| 期望 | 依赖 $p(\pi)$,可很大 | $\le 1.43$ |
| 方差 | 可发散 | $\le (0.715)^2 \approx 0.51$ |
---
第四重:GAL 标准化优势估计量的统计性质
对查询 $x$,构建群体 $\mathcal{G}_x = \{y_1, \ldots, y_K\}$,每个响应获得奖励 $R(y_k)$(数学题上即为答案正确性:$R \in \{0, 1\}$)。
定义优势:
$$A(y_k) = \frac{R(y_k) - \mu_x}{\sigma_x + \epsilon} \tag{5}$$
其中 $\mu_x = \frac{1}{K} \sum_k R(y_k)$,$\sigma_x^2 = \frac{1}{K} \sum_k (R(y_k) - \mu_x)^2$。
统计性质(对任意 $K$ 精确成立):
1. 零中心:$\sum_k A(y_k) = 0$,因为 $\sum_k (R_k - \mu) = 0$ 2. 单位方差:$\frac{1}{K} \sum_k A(y_k)^2 = 1$(当 $\epsilon = 0$) 3. 保序:$A(y_i) > A(y_j) \iff R(y_i) > R(y_j)$ 4. 仿射不变:若 $R \mapsto aR + b$($a > 0$),则 $A$ 不变 5. 难度自适应:$\sigma_x$ 小 → 群体意见一致 → $A$ 幅度收窄 → 减少对"已掌握"查询的无效学习
二值奖励特例($R \in \{0, 1\}$):
令 $p_x = \frac{1}{K} \sum R_k$ 为正确率,则 $\mu_x = p_x$,$\sigma_x = \sqrt{p_x(1 - p_x)}$。
$$A(y_k) = \begin{cases} \sqrt{\frac{1-p_x}{p_x}} \cdot \frac{1}{\sqrt{p_x(1-p_x)} + \epsilon} & R_k = 1 \\ -\sqrt{\frac{p_x}{1-p_x}} \cdot \frac{1}{\sqrt{p_x(1-p_x)} + \epsilon} & R_k = 0 \end{cases}$$
忽略 $\epsilon$ 时简化为:
$$A(y_k) \approx \begin{cases} \frac{1-p_x}{\sqrt{p_x(1-p_x)}} & R_k = 1 \\ \frac{-p_x}{\sqrt{p_x(1-p_x)}} & R_k = 0 \end{cases} \tag{6}$$
三种典型场景:
| 场景 | $p_x$ | 正样本优势 | 负样本优势 | 解释 |
|---|---|---|---|---|
| 极致困难 | $\to 0$ | $\to \infty$(截断) | $\to 0$ | 所有人都错,极少数对的样本获强信号 |
| 中等难度 | $=0.5$ | $+1$ | $-1$ | 最大区分度,学习信号最强 |
| 极致简单 | $\to 1$ | $\to 0$ | $\to -\infty$(截断) | 几乎全对,避免在已掌握任务上浪费容量 |
---
第五重:统一梯度——把三件武器熔于一炉
GFT 的完整梯度为:
$$\nabla_\theta \mathcal{L}_{\text{GFT}} = \mathbb{E}_{y_k \in \mathcal{G}_x} \left[ A(y_k) \cdot \frac{C(\pi_\theta(y_k|x))}{\pi_\theta(y_k|x)} \cdot \nabla_\theta \log \pi_\theta(y_k|x) \right] \tag{7}$$
三要素逐层解析:
- $A(y_k)$:信号的方向与强度——正的推高概率,负的压低概率,零的不管
- $C(\pi)/\pi$:梯度的保险丝——对低置信 token 限流,阻止单条轨迹 dominating
- $\nabla \log \pi$:标准的策略梯度方向——告诉模型该往哪走
$$\mathcal{L}_{\text{GFT}} = -\sum_{y_k \in \mathcal{G}_x} w_k \cdot \log \pi_\theta(y_k | x)$$
其中 $w_k = |A(y_k)| \cdot \frac{C(\pi_\theta(y_k|x))}{\pi_\theta(y_k|x)}$,且 $A(y_k) > 0$ 的样本正常学习,$A(y_k) < 0$ 的样本取负 loss(实质上是"反学习")。
---
第六重:信息论审视——熵坍缩的数学机制
SFT 的损失可以分解为:
$$\mathcal{L}_{\text{SFT}} = \mathbb{E}_x \left[-\log \pi_\theta(y^*|x) \right] = \mathbb{E}_x \left[ D_{\text{KL}}(\delta_{y^*} \| \pi_\theta(\cdot|x)) + H(\delta_{y^*}) \right]$$
由于 $H(\delta_{y^*}) = 0$(Dirac delta 的熵为零),
$$\mathcal{L}_{\text{SFT}} = \mathbb{E}_x \left[ D_{\text{KL}}(\delta_{y^*} \| \pi_\theta(\cdot|x)) \right] \tag{8}$$
最小化此 KL 散度本质上迫使 $\pi_\theta$ 向 $\delta_{y^*}$ 靠拢——即熵坍缩:
$$H(\pi_\theta(\cdot|x)) \to 0$$
这何以导致 SFT→GRPO 的协同困境?
GRPO 的核心操作是:对每个查询采样一组响应,计算相对优势,然后用策略梯度更新。这要求群体有足够的多样性,否则 $\sigma_x \approx 0$,优势信号消失。
设 $\pi_{\text{SFT}}$ 为 SFT 后的策略,其每个查询的熵为 $H(\pi_{\text{SFT}}(\cdot|x))$。当此熵极低时,对 $x$ 采样 $K$ 个响应,几乎次次相同:
$$\mathbb{P}(y_1 = y_2 = \cdots = y_K) \to 1$$
此时 $\sigma_x = 0$,所有 $A(y_k) = 0$,GRPO 学无可学。
GFT 何以避免?关键在于 GAL 的群体构建不依赖单一模型采样:教师蒸馏样本和专家演示外源注入多样性,即便模型自身的熵再低,群体中仍有 4 条非自生成轨迹提供差异信号。加之 DCR 阻止极端更新进一步压缩熵,GFT 维持了一个健康的探索空间。
KL 散度的实证证据(从预训练基模型到训练后模型):
$$D_{\text{KL}}(\pi_{\text{base}} \| \pi_{\text{trained}}) = \begin{cases} \text{SFT: 高} \\ \text{GFT: 低} \quad (\approx \text{GRPO 水平}) \end{cases}$$
KL 低意味着模型没有剧烈偏离预训练分布 → 遗忘少 → 通用能力保留。
---
第七重:GAL 在二值奖励下的精确行为——一个工作实例
设 $K=8$,某查询 $x$:
- 专家样本:$R=1$(正确)
- 教师蒸馏 3 个:$R \in \{1, 1, 0\}$(2 对 1 错)
- 模型自生成 4 个:$R \in \{0, 1, 0, 0\}$(1 对 3 错)
计算:
- $\mu = \frac{4}{8} = 0.5$
- $\sigma = \sqrt{0.5 \times 0.5} = 0.5$
- $A(1) = \frac{1-0.5}{0.5} = +1$
- $A(0) = \frac{0-0.5}{0.5} = -1$
对比 SFT:SFT 只能用那 1 条专家轨迹,其余 7 条完全浪费。GFT 每条轨迹都有学习信号——4 条正向,4 条负向——数据利用效率拉开到了 8×。即便考虑到负样本的信号强度可能略弱,这个倍数仍然巨大。
---
余论:数理之美的边界
GFT 的数学构造堪称优雅:用重要性采样揭示 SFT 的 RL 本质,用 z-score 归一化构建零中心对比信号,用 stop-gradient 裁剪驯服无界权重。三块拼图,严丝合缝。
然则以下几个数理问题尚待厘清:
1. DCR 阈值 $\tau$ 的最优性:当前 $\tau=0.7$ 是启发式的。理论上,$\tau$ 由 $p(\pi)$ 的分布决定——若能在 $\pi$ 的累积分布函数 $F(\pi)$ 上定义一个与下游任务相关的泛函,则 $\tau$ 可得自适应解。此方向有待形式化。
2. GAL 优势估计的渐近性质:当 $K \to \infty$ 时,标准化优势 $A(y_k)$ 逼近什么?若群体构成独立同分布,$A$ 渐近正态。但 GFT 的群体混合了三种分布(专家、教师、自生成)——这是一个分层采样问题,优势估计的偏差需进一步分析。
3. 与 PPO-clip 的内在联系:DCR 的 $\text{sg}(\pi_t)$ 截断与 PPO 的 $[1-\epsilon, 1+\epsilon]$ 夹逼在本质上都是重要性采样权重的正则化。二者的泛函形式能否统一?若能,则可在 GFT 与 PPO 之间建立连续谱系。
---